





この記事の3行まとめ
- サイバーエージェントのコア技術本部チーム、『シェーダー最適化入門 第2回目 「タイルベースレンダリングのGPUとは?」』と題した記事を公開
- モバイルデバイスでレンダリングを効率化する「タイルベースレンダリング」アーキテクチャのGPUを紹介
- VulkanやMetal、Unity 6などで使用できる「フレームバッファフェッチ」によるさらなる高速化なども解説している
サイバーエージェント ゲーム・エンターテイメント事業部 コア技術本部(以下、コアテク)は、『シェーダー最適化入門 第2回目 「タイルベースレンダリングのGPUとは?」』と題した記事を、技術ブログ「CORETECH ENGINEER BLOG」で公開しました。
同記事では、モバイルGPUで主流の「タイルベースレンダリング」アーキテクチャについて、その仕組みや最適化の手法などを解説しています。
◤#コアテクブログ 更新◢
\連載記事✨/
シェーダー最適化入門 第2回目
「タイルベースレンダリングのGPUとは?」 https://t.co/Mh24PX6ELg
今回は、スマートフォンのGPUで主流となっているタイルベースレンダリングのGPUの最適化について紹介しています!
— サイバーエージェント 技術広報(ゲーム・エンタメ) (@ca_ge_tech) January 27, 2025
◤#コアテクブログ 更新◢
\連載記事✨/
シェーダー最適化入門 第2回目
「タイルベースレンダリングのGPUとは?」 https://t.co/Mh24PX6ELg
今回は、スマートフォンのGPUで主流となっているタイルベースレンダリングのGPUの最適化について紹介しています!
— サイバーエージェント 技術広報(ゲーム・エンタメ) (@ca_ge_tech) January 27, 2025
現代のGPUは演算速度とメモリの読み書き速度の差が大きくなり、メモリアクセスがボトルネックと述べられています。
PCのディスクリートGPUではグラフィックス専用メモリを積むなどして対応できます。しかしモバイルGPUでは、発熱量や消費電力の問題から専用のグラフィックスメモリを持てず、CPUとGPUでメモリを共有していることが多いとのこと。
そこで生まれたのが、タイルベースレンダリングアーキテクチャのGPU。タイルメモリと呼ばれる小さく高速なキャッシュメモリをシェーダーコアに搭載し、画面をタイルで分割して、タイルメモリに対してレンダリングできます。
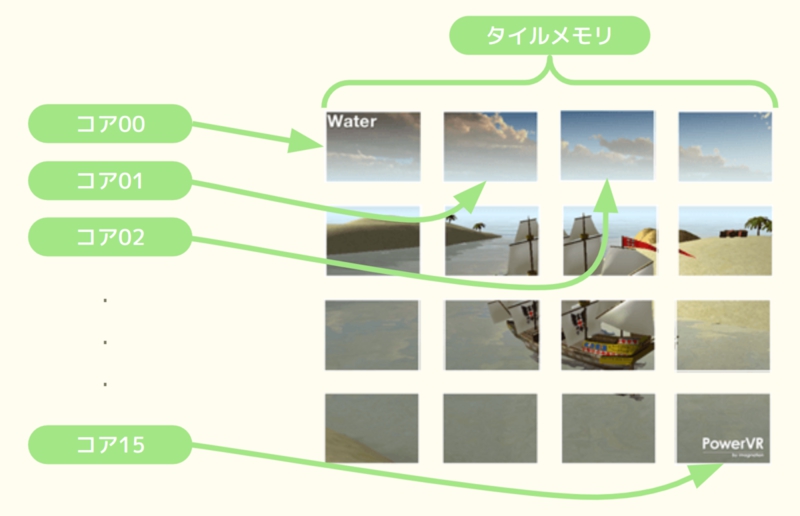
画像では16分割しかされていないが、あくまで例示されたもの。実際には16×16ドットや32×32ドットの矩形を1タイルとして扱うことが多く、本来はより多くのタイルが存在する(画像はブログ記事より引用)
タイルメモリに対して先にレンダリングし、レンダリングが完了したグラフィックスをCPU/GPUメモリにストア(保存)することで、速度の遅いメモリへのアクセス回数を減らし、高速化が可能とのことです。
ただし、最終的にはタイルメモリの内容をメインメモリにストアする作業が必要なため、この回数が多くなることはボトルネックにつながってしまいます。
記事ではこの問題への対処として、G-Bufferの作成を例に解説。最初に、「G-Bufferの作成(アルベドや法線などの情報をタイルメモリに書き込む)」「G-Bufferをメインメモリにストアする」「ストアされたG-Bufferをサンプリングし、ディファードライティングを行う」といったワークフローを紹介しています。
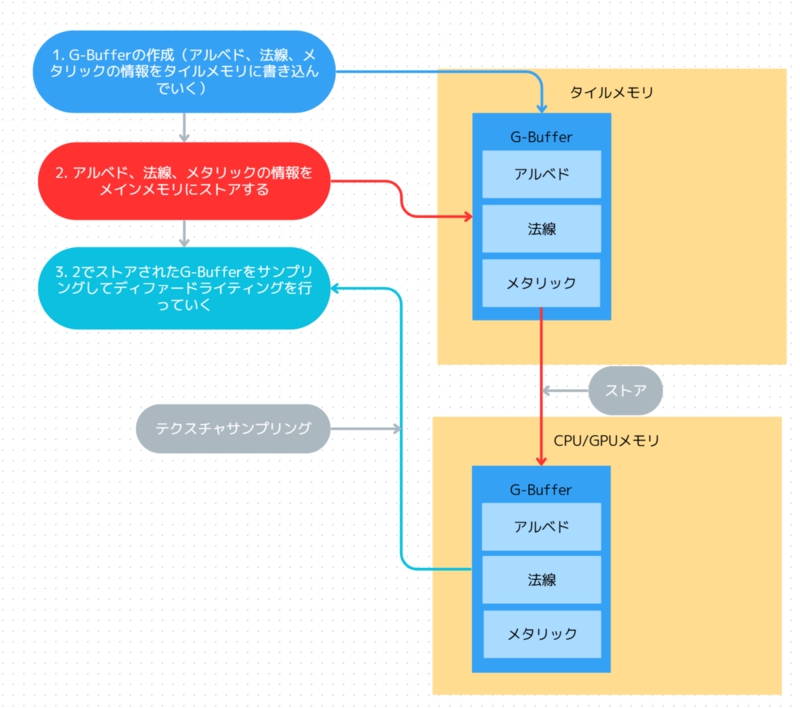
(画像はブログ記事より引用)
しかし、メインメモリからではなく、タイルメモリからG-Bufferを直接読み込むことができれば、メインメモリへのストア回数を減らせます。
同機能はフレームバッファフェッチと呼ばれ、VulkanやMetalといったグラフィックスAPIで利用可能。なお、Unityでも「Unity 6」から利用しやすい旨が記事で書かれています。
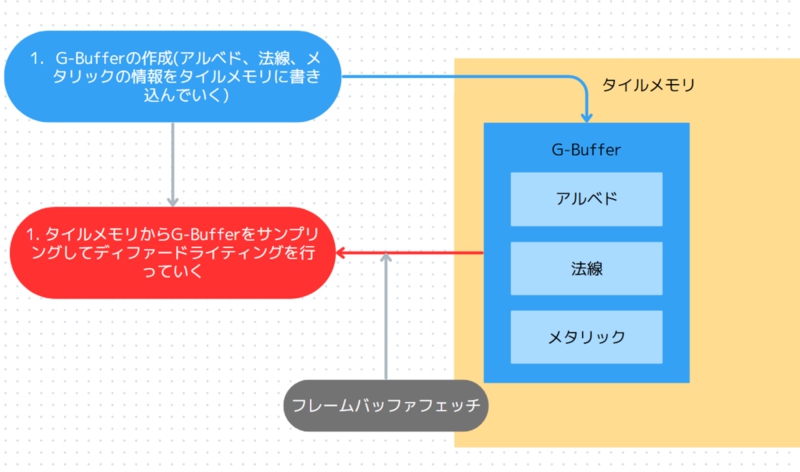
(画像はブログ記事より引用)
記事ではほかにも、VulkanやMetalで使用できる「RenderPass」を用いたリソースの定義手法について紹介。また、同様の機能をUnityで実装する手法についても、Render Graphを使用するケース/使用しないケースに分けて解説しています。
さらに、レンダリングテクスチャをタイルメモリに一時保存し、CPU/GPUに保存せずに処理することでアプリのメインメモリ使用量を削減する「メモリレスモード」についても言及しています。
詳細は、コアテクの技術ブログをご確認ください。
シェーダー最適化入門 第2回目 「タイルベースレンダリングのGPUとは?」 | CORETECH ENGINEER BLOG









