
2023年8月23日から25日まで開催された、国内最大規模のゲーム業界カンファレンス「CEDEC2023」。
カプコン サウンドディレクター 神田 幸範氏、サウンドデザイナー 三上 崇氏、サウンドプログラマー 夏苅 繁俊氏が登壇した講演「大量恐竜vs多人数チーム対戦が織りなす近未来オンラインマルチアクション 『EXOPRIMAL』における動的大量制御のインタラクティブサウンド表現と人工音声技術の活用」をレポートします。




2023年8月23日から25日まで開催された、国内最大規模のゲーム業界カンファレンス「CEDEC2023」。
カプコン サウンドディレクター 神田 幸範氏、サウンドデザイナー 三上 崇氏、サウンドプログラマー 夏苅 繁俊氏が登壇した講演「大量恐竜vs多人数チーム対戦が織りなす近未来オンラインマルチアクション 『EXOPRIMAL』における動的大量制御のインタラクティブサウンド表現と人工音声技術の活用」をレポートします。
TEXT / HATA
EDIT / 神谷 優斗, 酒井 理恵, 神山 大輝
神田氏は『ストリートファイター』シリーズや『モンスターハンターフロンティア』などに携わり、『EXOPRIMAL』ではサウンドディレクターとして開発に従事しています。三上氏はサウンドの制御やシステム制作を担当。夏苅氏はエンジニアとして、サウンド制御周辺の実装を担当しています。
『EXOPRIMAL』は最大10人のチーム対戦型オンラインアクションゲームです。「5人対100万の恐竜、多勢に無勢で挑み勝利するカタルシス」がコアコンセプト。プレイヤーはエグゾスーツを身にまとい、大量の恐竜と戦います。サウンドは7.1chサラウンド(現世代のプラットフォームでは7.1.4ch)の3Dオーディオに対応しています。
サウンドコンセプトは「相反するものを共存させて表現する」「相反するコントラストが乱暴に喧嘩したままブルドーザーのように突き進むサウンド」が掲げられました。新規IP、初のゲームジャンル、大規模ネットワークゲームなど挑戦的な要素が多かったと神田氏は語ります。
本作では、開発チーム内で「群れ恐竜」と呼称される、100体を超える小型恐竜の群れがレベルの各所に現れます。サウンドの実装においては、群れの各個体ごとに音をつけるのは処理負荷の観点から現実的ではありません。そこで、大群表現に適したサウンド機能が求められました。
また、群れ恐竜の表現方法はゲームデザインの変更に付随して変更が繰り返されたそうです。講演の前半では、大群表現の変更に対するアプローチについて解説されました。
初期の群れ恐竜の仕様はリリース時と異なり、恐竜の一群がプレイヤーに向かってくる挙動でした。群れは100体ほどの恐竜を管理する「群れオブジェクト」の連なりによって表現され、1つの群れオブジェクトにつき1つの音源が割り当てられていました。

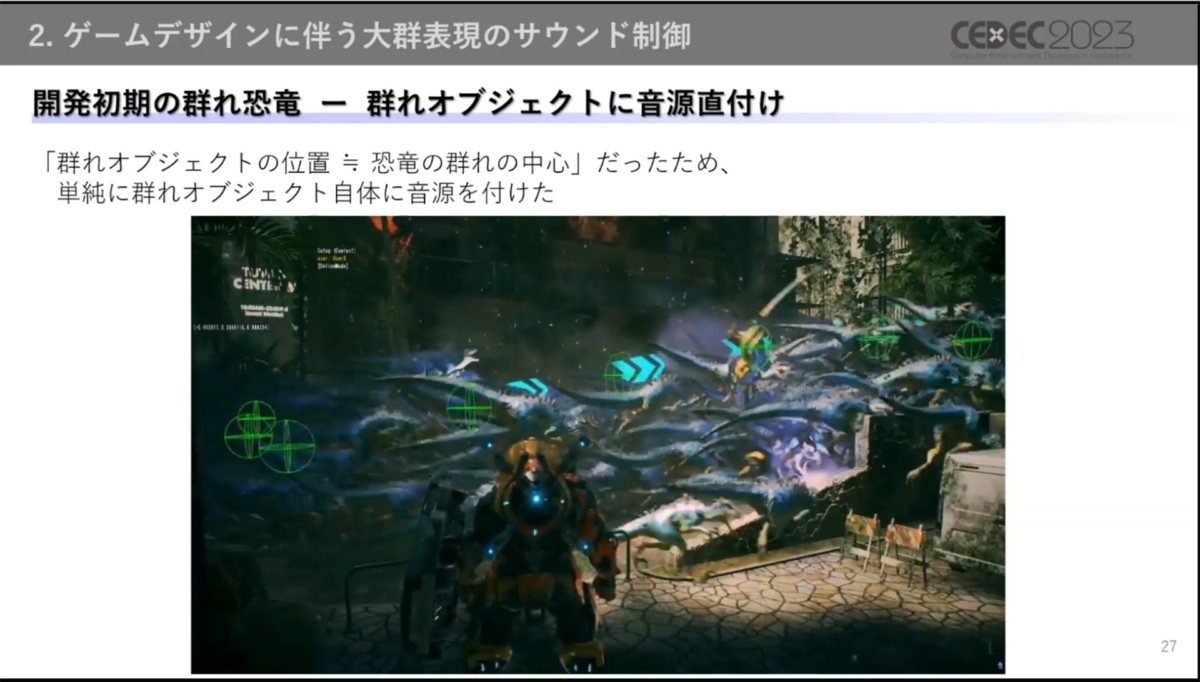
群れオブジェクトが団子のように連なって動くことで大群を形成している
群れオブジェクトにアタッチする方法には、大群感が出せるほか、群れオブジェクト自体が動くため音源の移動制御をする必要がない利点がありました。一方で、迫力をコントロールするボリューム制御の難しさや、複数の音源によるフランジングなど課題もありました。

開発中盤には、仕様変更により群れオブジェクト数の上限が引き上げられました。これまでの手法は群れオブジェクト数が10個までであることを前提としていたため、これを受けて別のサウンド設計が検討されました。

新たな仕様では、群れオブジェクトの最大数増加だけでなく、群れ恐竜が複数に分かれて動くようになりました。
オブジェクト数に従い発音数が大幅に増えたため、対策として連結している群れオブジェクトにつき1つのエミッター(音源オブジェクト)を使用する方式がとられました。
エミッターは、一連の群れオブジェクトのうちプレイヤーから最も近いものと同じ位置に置かれます。群れオブジェクトとプレイヤーの位置関係が変わると、それに応じてエミッターが置かれる群れオブジェクトも変わります。
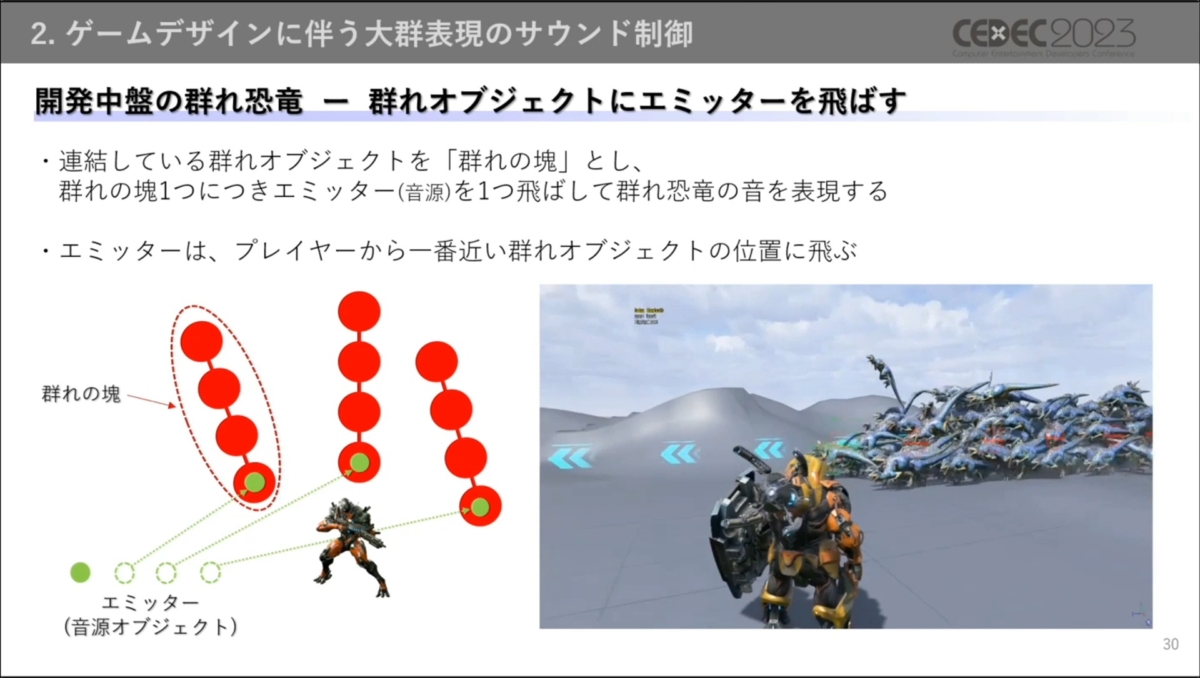
この方法には、群れの塊ごとにエミッターがただ1つ使われることから群れオブジェクト数増加の影響を受けにくいほか、音の制御がしやすいメリットがあります。反面、大群の移動に合わせたエミッターの位置更新が難しい問題もあります。

群れオブジェクト間をエミッターが移動する時、急に音源が移動したように感じてしまう
開発終盤では、恐竜が個別に動くよう群れ恐竜のシステムが変更。群れオブジェクトの概念がなくなり、個別に動く恐竜が群れたり散らばったりすることで大群表現を行う仕様になったため、サウンド制御も対応に迫られました。
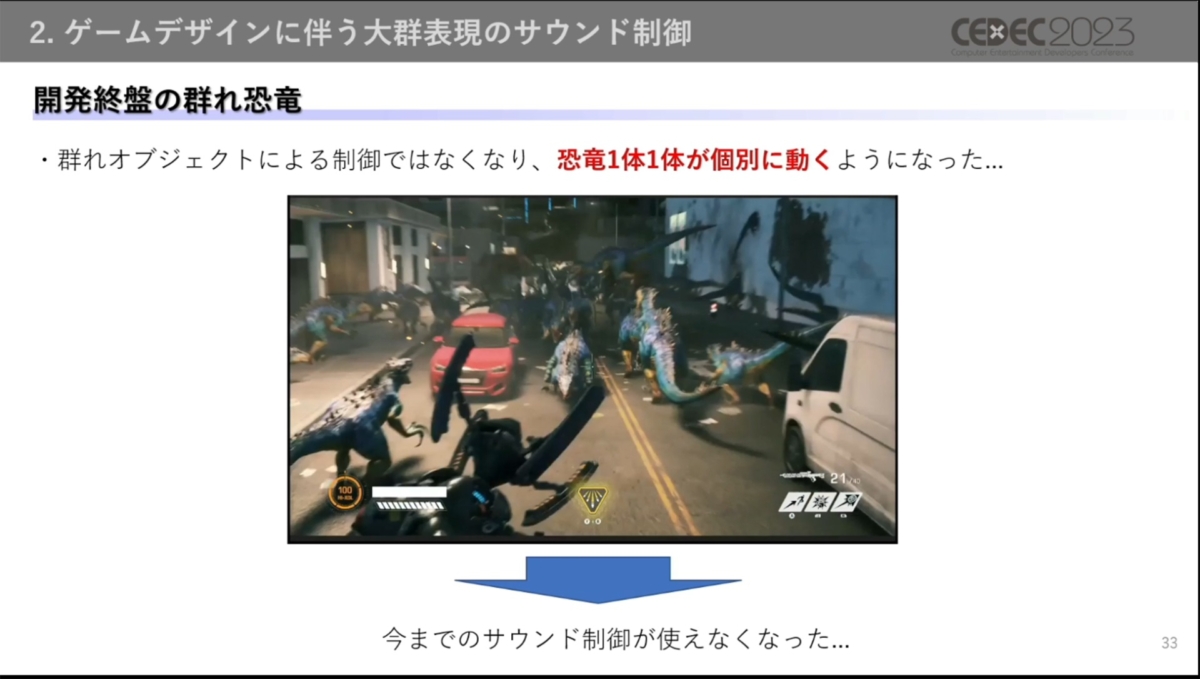
個々の恐竜がバラバラに動く場合でも、それぞれに音をつけるのは現実的ではないと考えた神田氏。そこで、個体用のサウンドと群れ全体用のサウンドの2カテゴリを用意し、ゲーム内の状況に応じてミックスする手法が採用されました。
プレイヤーの近くにいる小型恐竜は「個体の音」を表現すべく、大型恐竜と同様にモーションに対応して音を再生します。
一方、遠い位置にいる恐竜の群れの音(ガヤ音)は、これまでと同じようにエミッターを用いて制御。プレイヤーの周りに指定した4つの領域内に存在する小型恐竜の平均座標にエミッターを配置し、群れオブジェクトがない場合でも定位感のある群れ表現を実現しています。また、プレイヤーとエミッターの距離に応じて再生する音の種類や大きさを変えているとのこと。
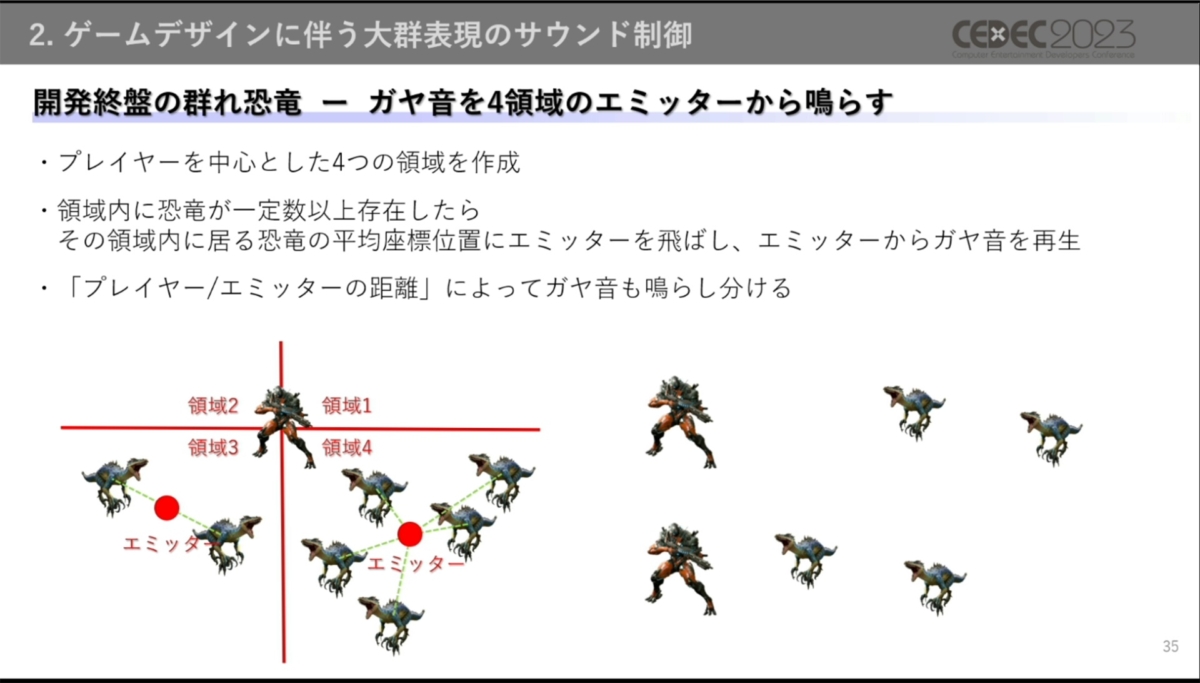
エミッターも群れの動きに合わせて移動するため、遠くの群れがプレイヤーに迫ってくる演出に迫力を持たせられるという。なお、領域内にいる恐竜の個体数が少なければガヤ音は再生されない
エミッターのある群れの中心に必ずしも恐竜がいるわけではないことに対しては、再生するのがガヤ音であることから問題ないと判断されました。
続いて、夏苅氏より大量発音の動的カリングおよびダイナミックミキシングシステムについて解説が行われました。
本作には最大10人のプレイヤーに加え、群れ恐竜や大型・中型恐竜が同時に存在するため、発音数を制限する仕組みが必要でした。しかし、効果音の発音数を最初から減らしてしまうとエグゾスーツや恐竜の迫力がなくなってしまいます。また、プレイヤーや恐竜次第でゲームの状況が変わるため、カリングの処理を事前に決め打つのが難しい事情もありました。

その対応として、現在のゲームの状況からリアルタイムにカリングを行う動的カリング制御が採用されました。動的カリング制御では、状況に応じて3段階のカリングを行っています。
第一段階では、最も多い群れ恐竜の個体音を減らすための距離と個体数に基づくカリングを適用。遠くにいる恐竜の個体の音は再生しないほか、近くにいる恐竜にも個体数の上限を設けて数体以外は再生しないようにしています。
個体の音を再生しない恐竜は、ガヤ音によって表現を補完しています。
第二段階では、プレイヤー周辺の状況に応じた、聞こえなくても違和感の少ない音をカリングしています。
周りに味方プレイヤーが多くいる場合、味方からのサウンドは重要な音(攻撃音)のみが再生され、細かなスーツの動作音などは再生されません。
一方、周りの味方プレイヤーが少ない場合は発音数に余裕があるため、動作音などもカリングせず再生します。
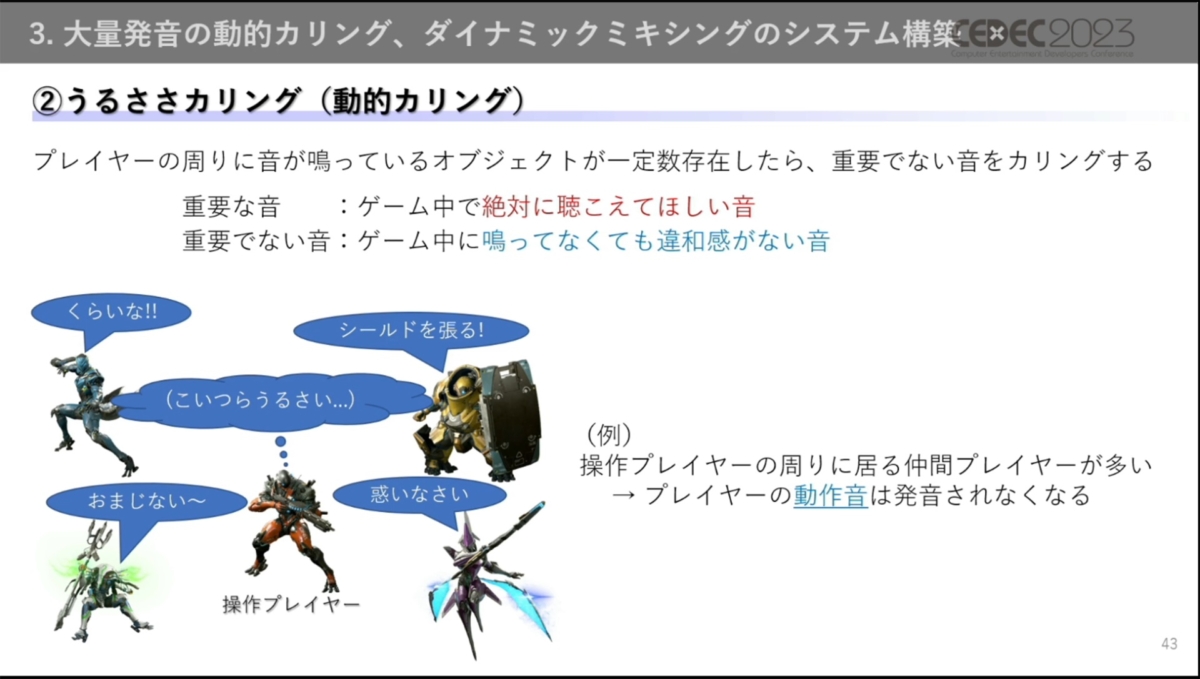
プレイヤー周辺で特定オブジェクトから音が鳴っている場合に木や滝などの環境音をカリングする用途などにも使われている。夏苅氏はこのカリングを「うるささカリング」と呼んでいるそう
第三段階では、サウンドごとに設定されている同時発音数上限や優先度によるカリングが行われます。再生されている音と鳴らそうとする音の設定を比較するため処理コストがかかりますが、これを低減するため「うるささカリング」によって明らかに鳴らさなくてよい音を除外しています。
また、安全装置としてWwise側のVolume Threshold設定によるカリングも行っています。
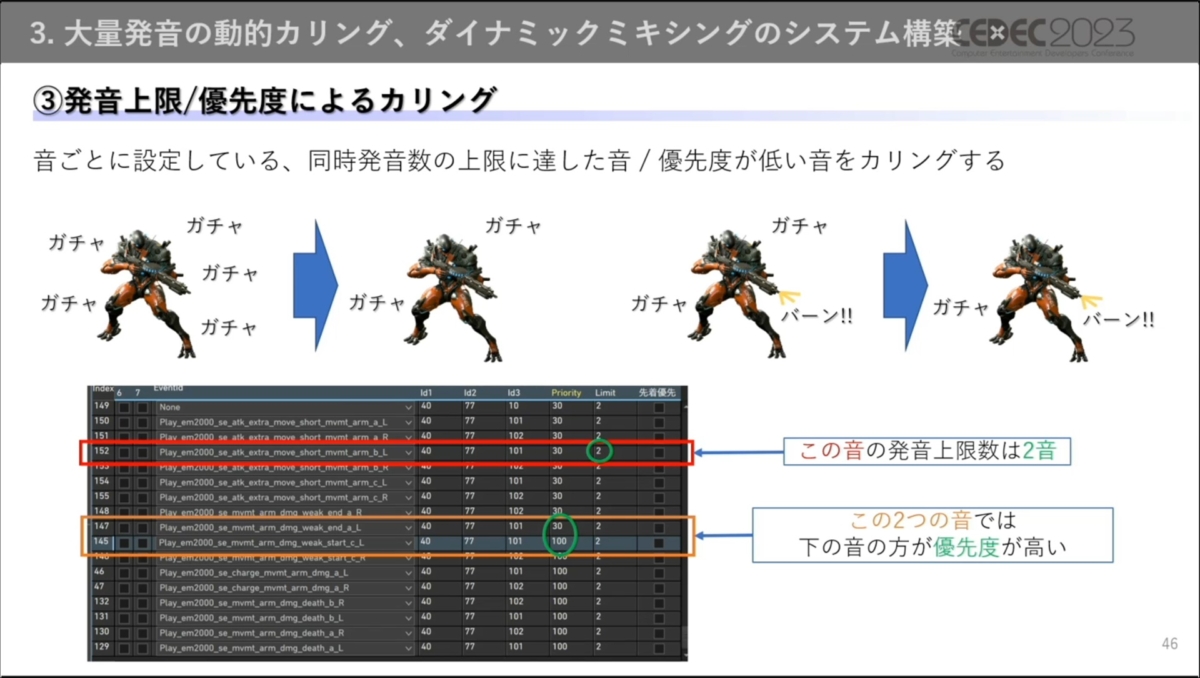
ただし、カリングのみでは大量の効果音がプレイヤーの周りで再生され続ける状況は変わりません。重要度によるカリングで最適化されていますが、本作では重要度の高いサウンド自体が多いため音が飽和状態になってしまう可能性が残されています。
そこで、カリングと同様にミキシングもリアルタイムに制御が行われています。
ここで講演は三上氏に交代し、ダイナミックミキシングの説明が行われました。
ダイナミックミキシングは、プレイヤーがフォーカスしたい音が聞こえる点と、「ピンチの時に味方が必殺技で助けてくれた」といった場面で開発者側が意図した体験を演出できる点を軸に構築されました。
具体的には、恐竜の数や行動などに基づく周囲の状況をそれぞれ定義したうえで、状況に応じたミックスのプリセットを適用するよう実装されています。これにより、いかなる状況であっても必殺技やT-rexの鳴き声などのプレイヤーにとって重要な音や聞かせたい音を聞かせることが可能です。
プリセットは、「周囲に仲間プレイヤーが多い状況では、仲間プレイヤーが発する音のバスボリュームをこれだけ下げる」「大型恐竜が周りに一体以上存在していたら、仲間プレイヤーと群れ恐竜のバスボリュームをこれだけ下げる」などが用意されています。
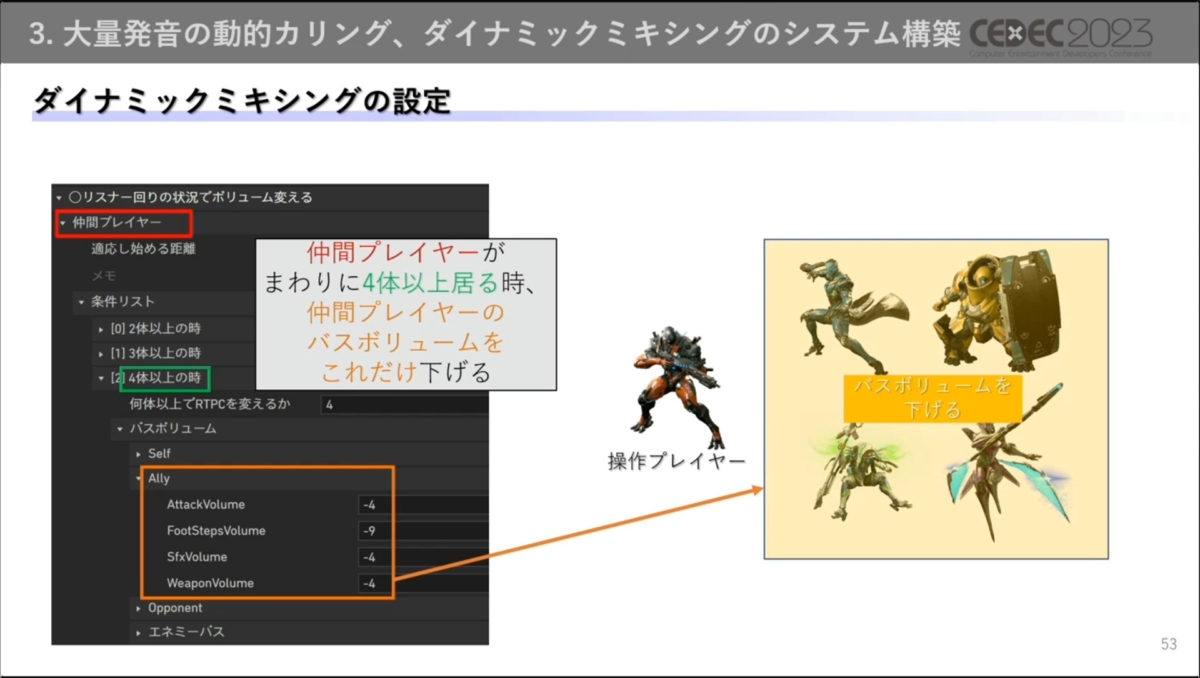
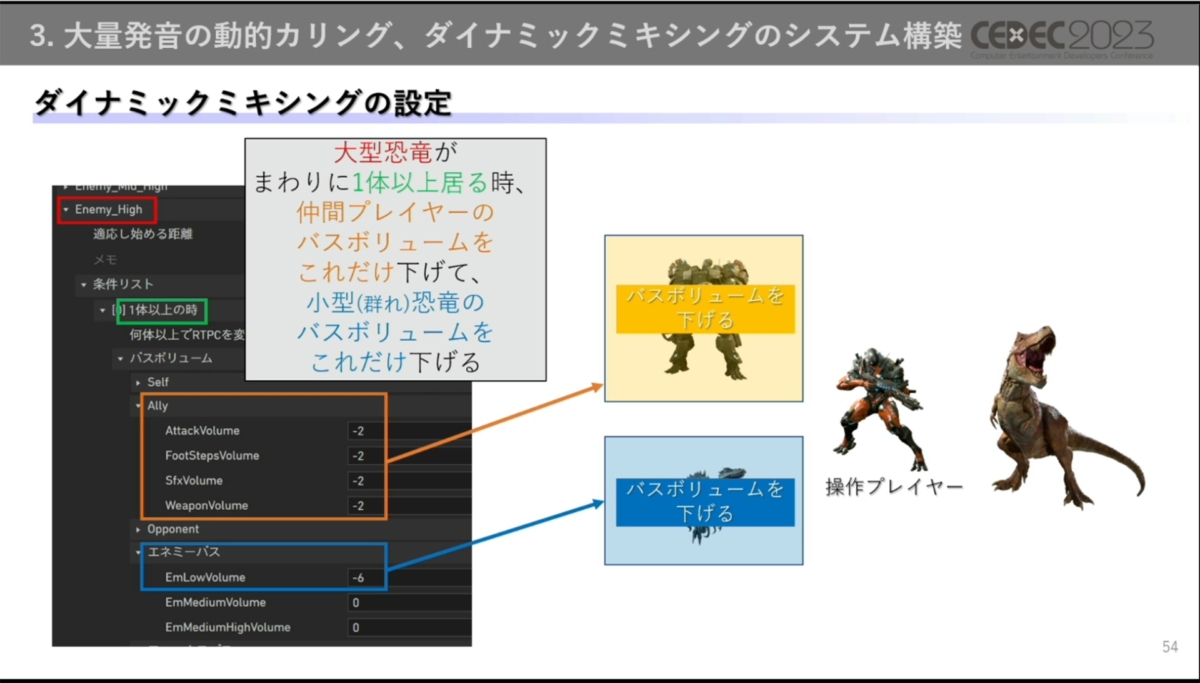
状況に紐づいたプリセットの作成は、すべてサウンドデザイナーが担当している
続いて、三上氏は大量のオブジェクトが存在するシチュエーションに伴う、ヒット音の問題について説明しました。
本作におけるヒット音の要件は、以下の3点です。
新規IPであることから開発のイテレーションが激しかったため、システムはシンプルに仮組みしたうえで挙動を確認しつつ固めていく方針を採用。試作段階では、攻撃を受けたオブジェクト自身がヒット音を鳴らす一般的な仕組みが使われました。
しかし、開発が進むと大量にオブジェクトが存在していることに起因するさまざまな問題が発生したそう。例えば「プレイヤーに関係のない敵や味方の攻撃によるヒット音が大量に鳴る」「広範囲攻撃によるヒット音の多重コール」「攻撃が当たった回数分すべてコールされる」などの問題です。
「そこから試行錯誤したが、なかなか要件を達成できなかった」と三上氏は言います。というのも、当初の仕組みではヒット時のイベントは攻撃を受けた情報しか送信しないため、プレイヤーと攻撃要因との関係(自キャラ、味方、敵など)や攻撃属性に応じたヒット音の出し分けやコールのカリングが不可能だったためです。
それを受けて、本作独自の新しいヒット音制御システムが開発されました。新たなシステムでは、オブジェクトごとではなくゲーム空間全体でヒット判定を管理し、ヒット音専用のオブジェクトでヒット音を鳴らします。
各オブジェクトのヒット判定はヒット音用オブジェクトに集積されたあとに鳴らし方が決まります。ヒット音用オブジェクトはゲーム空間全体の情報を取得できるため、「誰が」「どの属性で」「誰を」攻撃したのかなどの詳細な情報に基づいた発音が可能です。
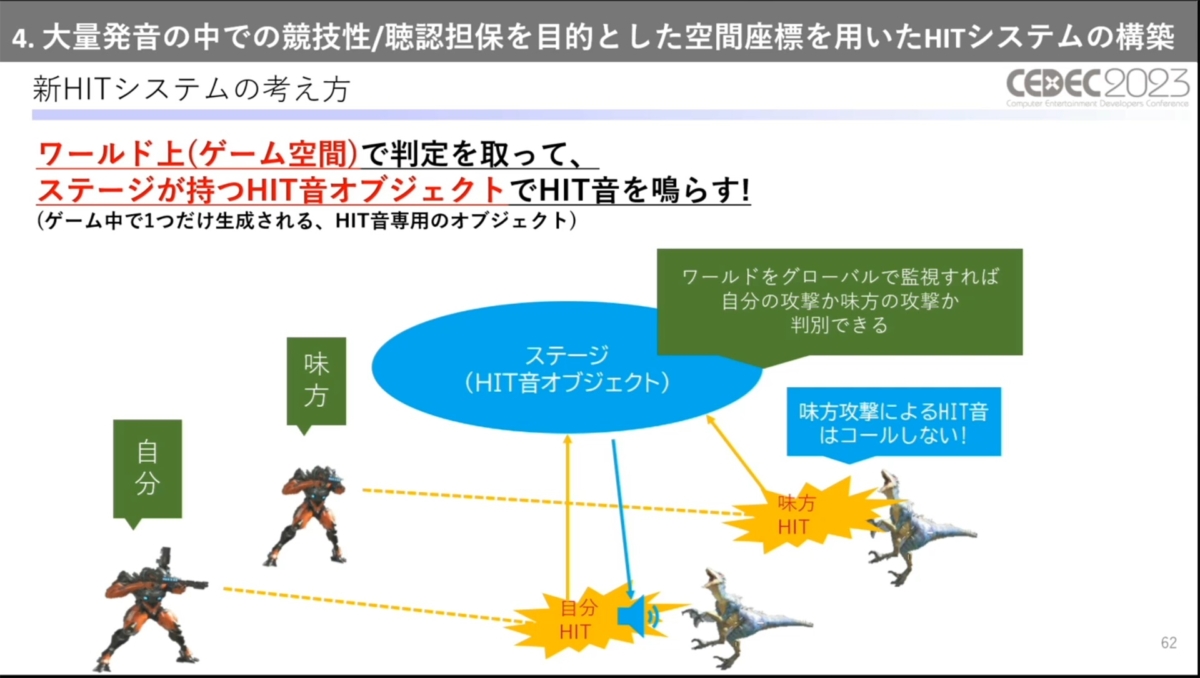
プレイヤーの攻撃によるヒット音は鳴らし、味方の攻撃によるヒット音は鳴らさないなどが制御できるようになった
これにより、もう一つの課題であった、当たり判定の大きい攻撃が複数のオブジェクトにヒットした際にヒット音が多重再生される問題も解決しました。ヒット判定を集積し、プレイヤーに最も近い座標で発生したもののみコールすることで、処理コストが増えるリスクを回避しています。
ここで、詳細な処理について説明。リスナーを中心に空間を19エリアに区切り、各エリアごとにヒット判定を集計してコールを制御しています。
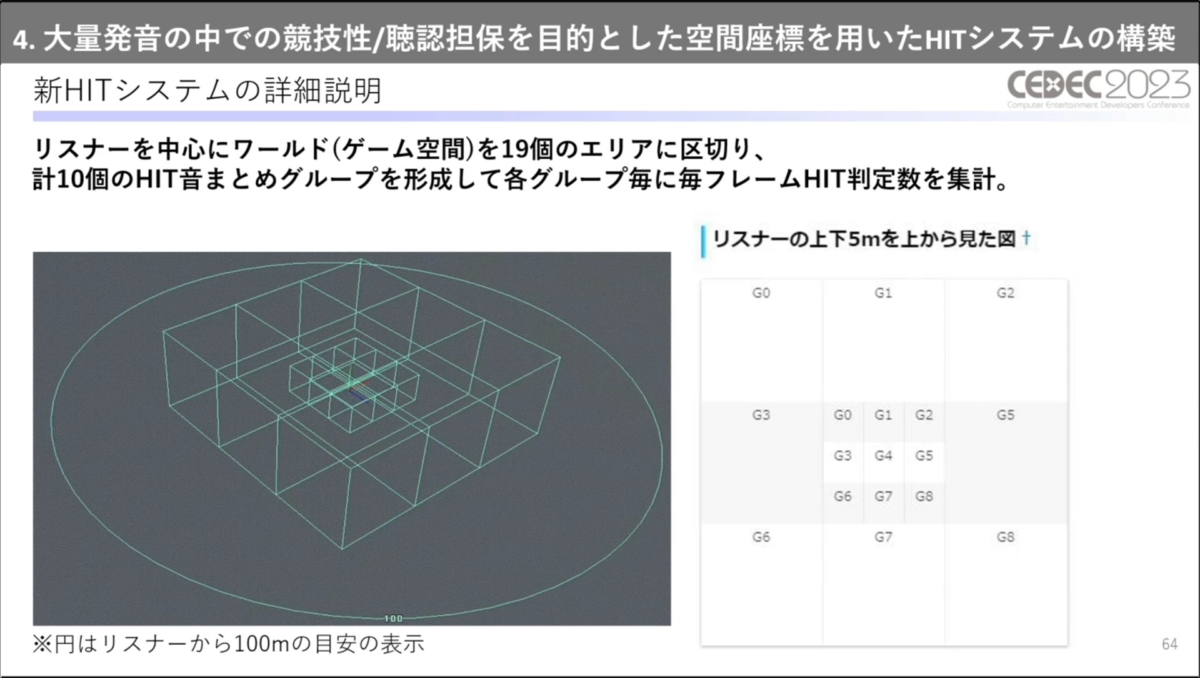
プレイヤーに近いほどグリッドを小さく分割している
最終的に、プレイヤーから見て同方向にあるグリッドは統合され、空間は10グループに分けられます。グループ内で同じ攻撃属性のヒット判定が同時に多数発生した場合、リスナーに最も近い座標のヒット音のみコールされる仕組みになっています。
また、ヒットに関する情報をより詳細に取得できるようになったことで、より細かにヒット音を鳴らし分けられるようにもなりました。本作では、攻撃者で19項目、攻撃属性で24項目、攻撃を受けた対象者で19項目、強さ・部位で8項目でヒット音を分類し、約7万パターンの組み合わせで鳴らし分けています。
特に、恐竜単体と集団でのダメージボイスの鳴らし分けは手応えアップに大きく寄与したそうです。
講演後半では、人工音声によるイテレーションとボイス制御について、神田氏から解説が行われました。
本作は高速な開発イテレーションに加え、複雑性の高いPvEvPであることや画面上に多くの要素が存在するなどの理由から、ゲームルールが伝わりづらい特性があるとのこと。そこで、キャラクターの声によって説明や誘導を行う「ボイスナビゲーション」の導入が検討されました。
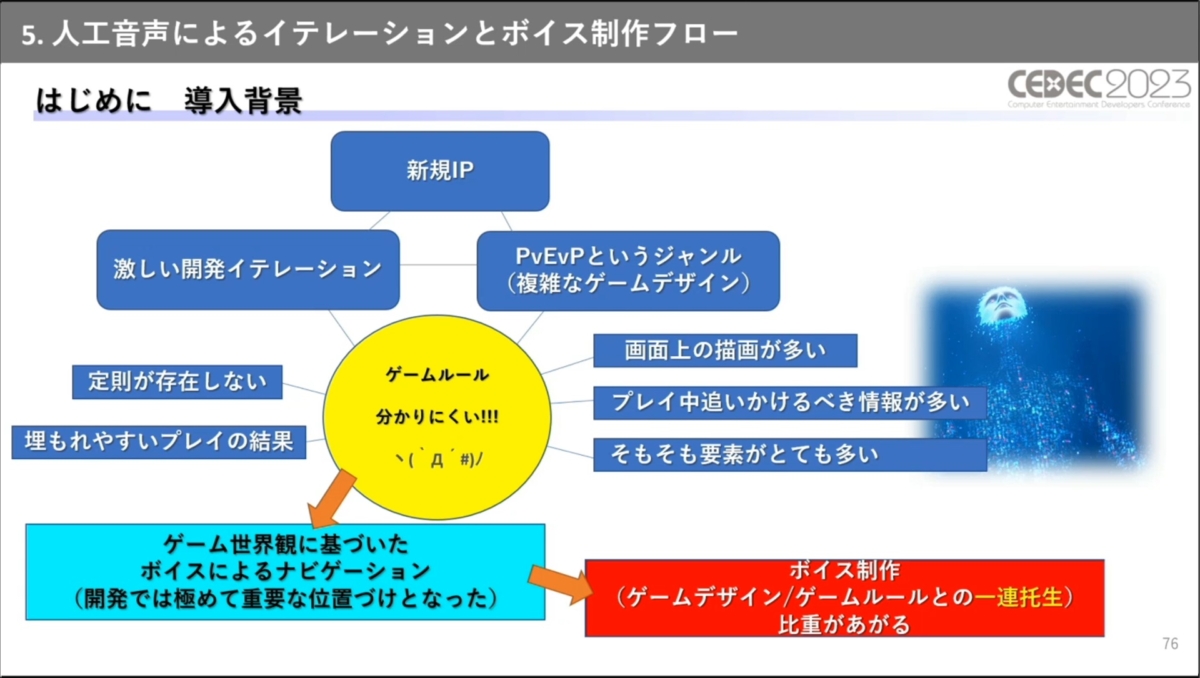
開発当初、ボイスナビゲーションは従来通りプレスコまたはインハウスでの仮ボイス収録を行い、ゲームテスト後に本番収録という流れで制作が進行していました。
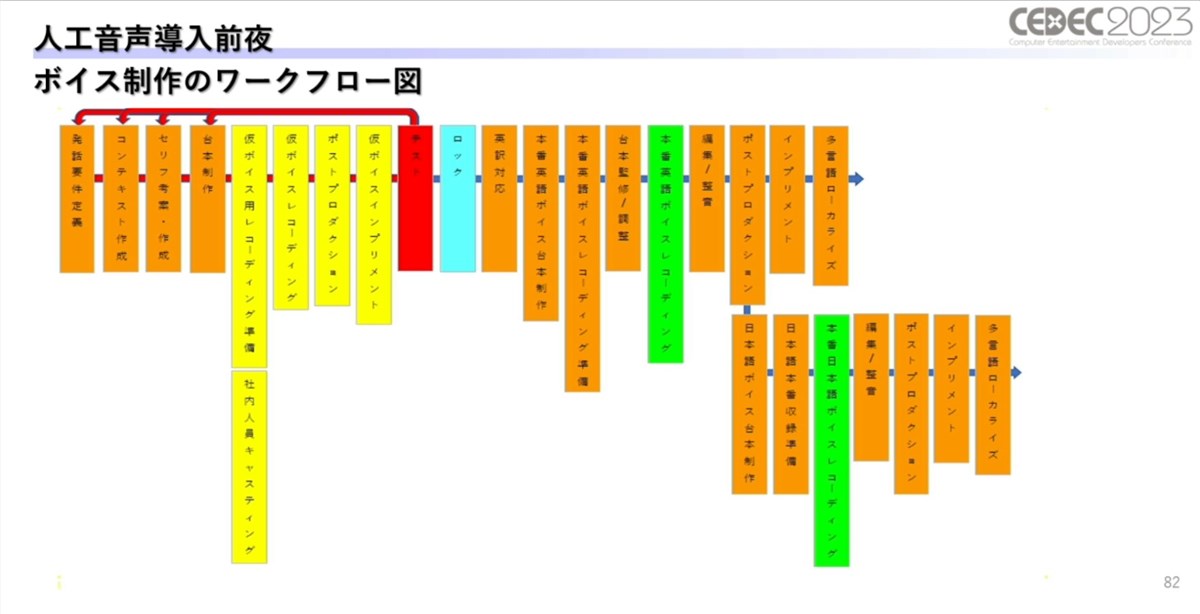
音声収録を使用したワークフロー。イテレーションのサイクルは赤い矢印で示されている
ボイスの主要言語は英語。北米での現地収録のほか、リモートでの収録も行っていた
新規IPであったため、特に初期段階ではゲームデザインや表現の正解がまだ確立されておらず、開発チームやレビュアーの認識が統一できていなかったとのこと。その中で、ボイスナビゲーションはゲームが目指すべき方向性を示す道しるべとしての役割が求められました。
しかし、音声収録を行う従来の手法では、本作における仮ボイスの要件を満たしたうえで、激しい開発イテレーションに伴う仕様変更に対応するのは不可能でした。収録に必要な段取りにコストがかかる点や、アイデアがすぐに試せない点などが開発の枷となっていったそうです。
そんな中、合成音声を用いたテキストの読み上げ機能を持つマイクロソフトのクラウドサービス「Azure Text To Speech」の導入がプログラムサイドから提案されました。
Azure Text To Speech 公式サイト導入した結果、従来のボイス収録で必要としていた多くの工程がほぼゼロになり、イテレーションの高速化に大きく寄与。ボイスの品質も高く、人工音声と気づかない開発者もいるほどでした。マイクロソフトのサポートが同サービスのゲームへの使用に協力的であったことや、多くのボイスプリセットが使用できたことも品質向上に作用したそうです。
また、オリジナルの音声モデルが作成できることも導入を後押ししました。

ナビゲーションを行うキャラクター『リヴァイアサン』が人工知能という設定だったため、AIによる音声がマッチしていた
導入には障壁もありました。従来にはない開発工程であるため、オリジナルの音声モデル作成に関する調査や社内プレゼンへの準備に時間がかかったと神田氏は言います。また、クラウドや従量課金制サービスの利用に対しての知識を持つメンバーが少なかったため、サービスの管理などを考慮した人員配置が必要でした。
人工音声の導入により、従来の音声収録にかかっていたコストが大きく削減。台本作成から人員のキャスティング、レコーディングなどを行う音声収録工程が、データベースの入力と人工音声の書き出し工程に置き換わりました。
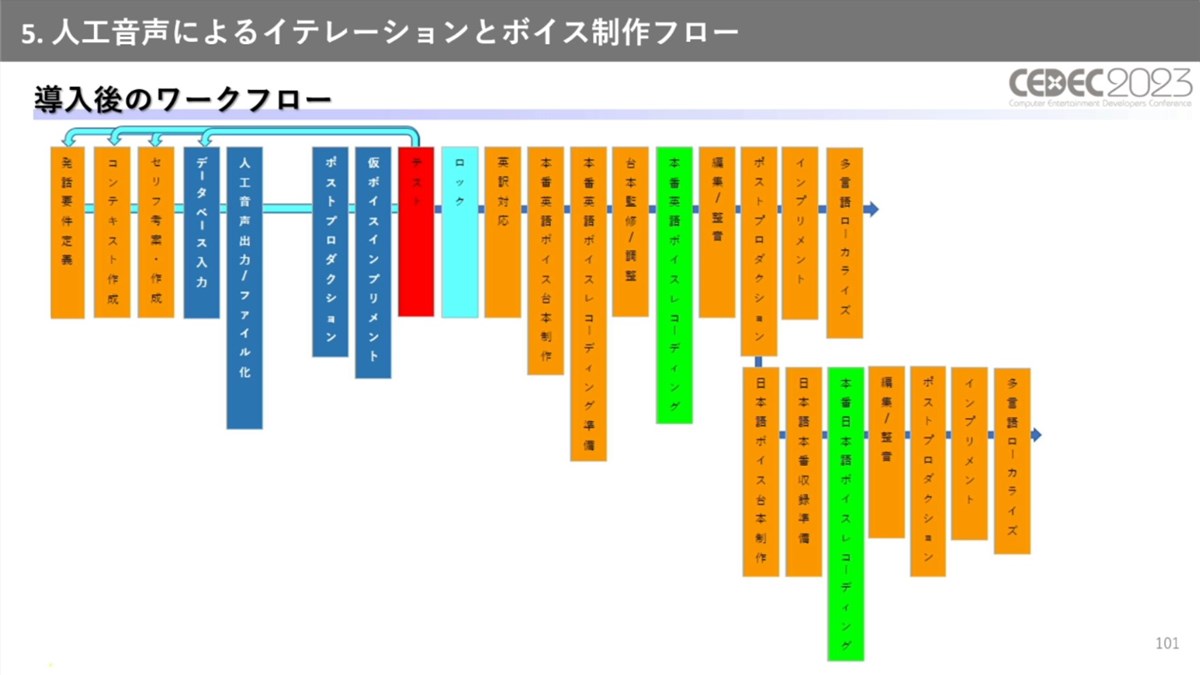
音声収録の代わりとなった人工音声生成工程は、ほぼ自動化できているという
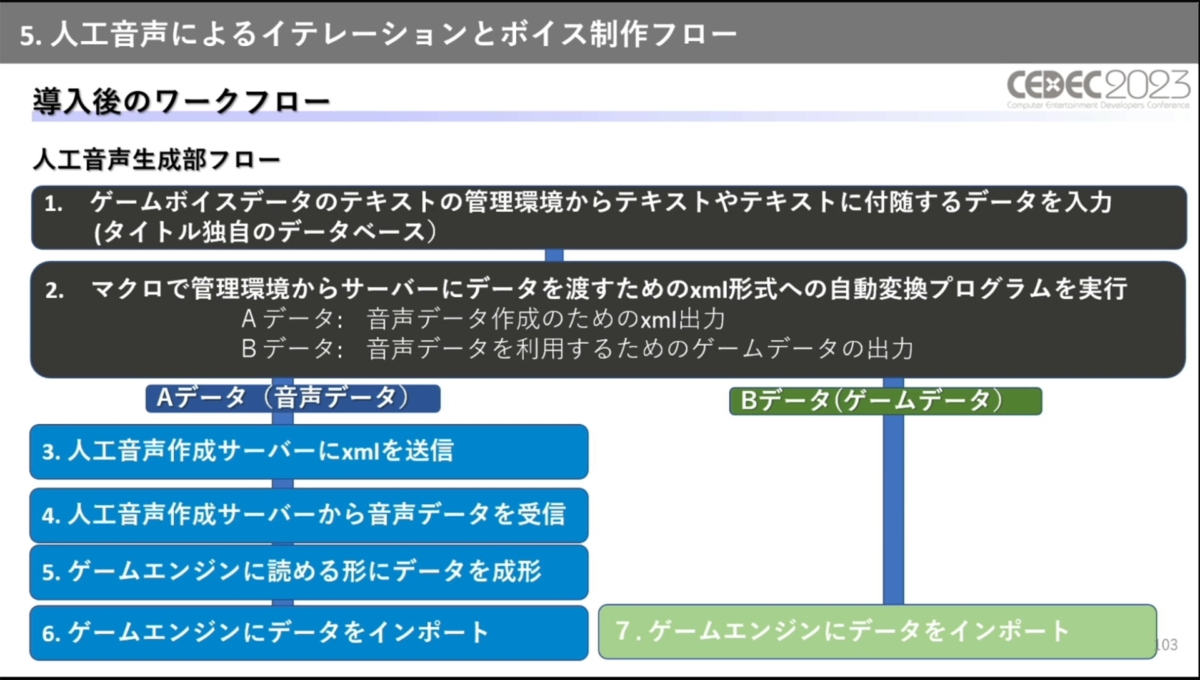
具体的な生成フローでは、最初にデータベースにテキストに関する情報を入力し、これをもとに音声の生成に使うデータとゲーム内で使用するデータを出力します。
音声生成用データはサーバーに送られ、Azure Text To Speechによって音声が作られます。音声をゲームエンジンにインポートするまでの工程はほぼ自動化されており、数万のボイスが数時間あれば使えるようになるとのことです。
生成した音声は収録音声と同様に扱われます。また、すべてのボイスではなく、一部のカットシーンやボイスナビゲーションには人工音声、感情表現が必要な部分には収録音声を使い分けています。
激しいイテレーションに伴う課題が解消された反面、ワークフローやルールが未成熟であったことから起こる問題もあったそう。これまでは収録が期限となっていたイテレーションを際限なく行えるようになったため、歯止めがきかなくなった点が事例として挙げられました。
また、従量課金であることから操作ミスによる事故を防ぐため、発注権限を持つメンバーを制限していたことで担当者にほかのメンバーから発注依頼が殺到する問題も挙げられました。
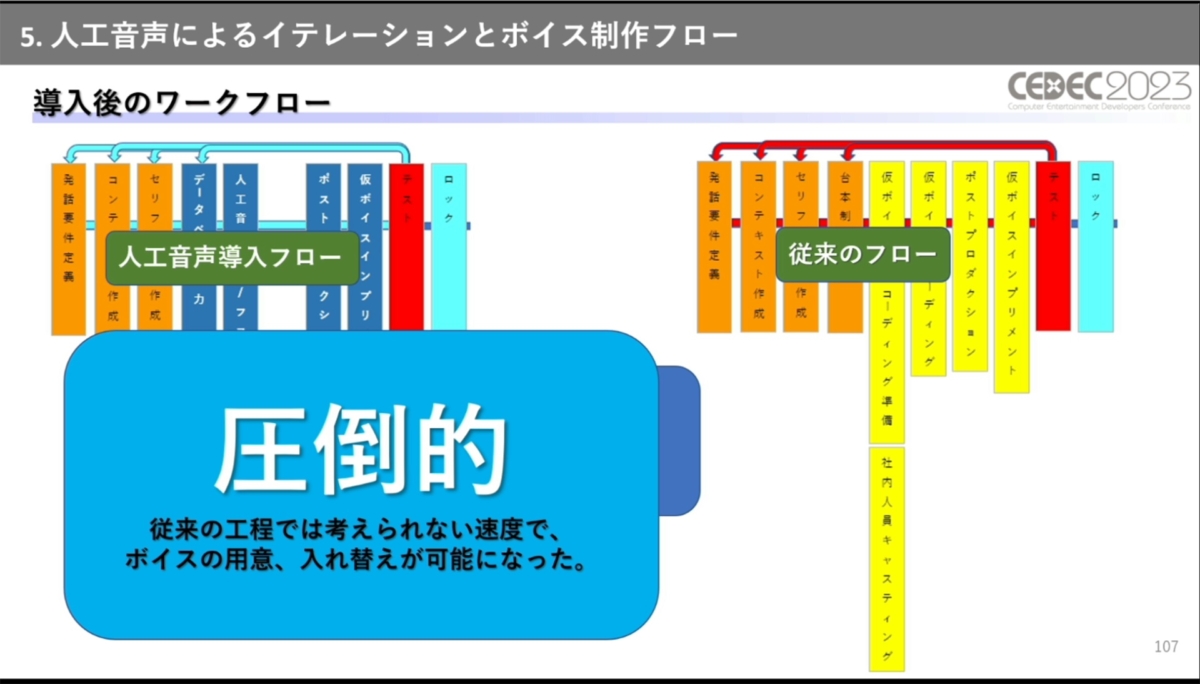
次に、神田氏は人工音声とともに活用した技術であるカスタムニューラル音声について解説しました。
カスタムニューラル音声は、マイクロソフトの管理する学習データと録音した音声アセットを用いて、機械学習により新たな音声モデルを作り出す技術です。実在する声優の演技を学習した音声モデルを作れば、あたかも本人が話しているかのような人工音声が生成できます。
本番用のボイスがイテレーションで使えれば大きな効率化になるほか、現場やコアメンバーからの期待の声もあったことが理由となり、ボイスナビゲーションにカスタムニューラル音声が導入されました。
ただし、学習結果の品質が事前に想定できない懸念や、ゲームで使用できる品質を生み出せるほどのアセット数を用意するコストの高さなど、課題も多かったとのこと。仮ボイスでの品質は好感触でしたが、ゲームへの採用実績は当時公開されておらず、製品としての品質を満たしうるか分からない中での取り組みになりました。
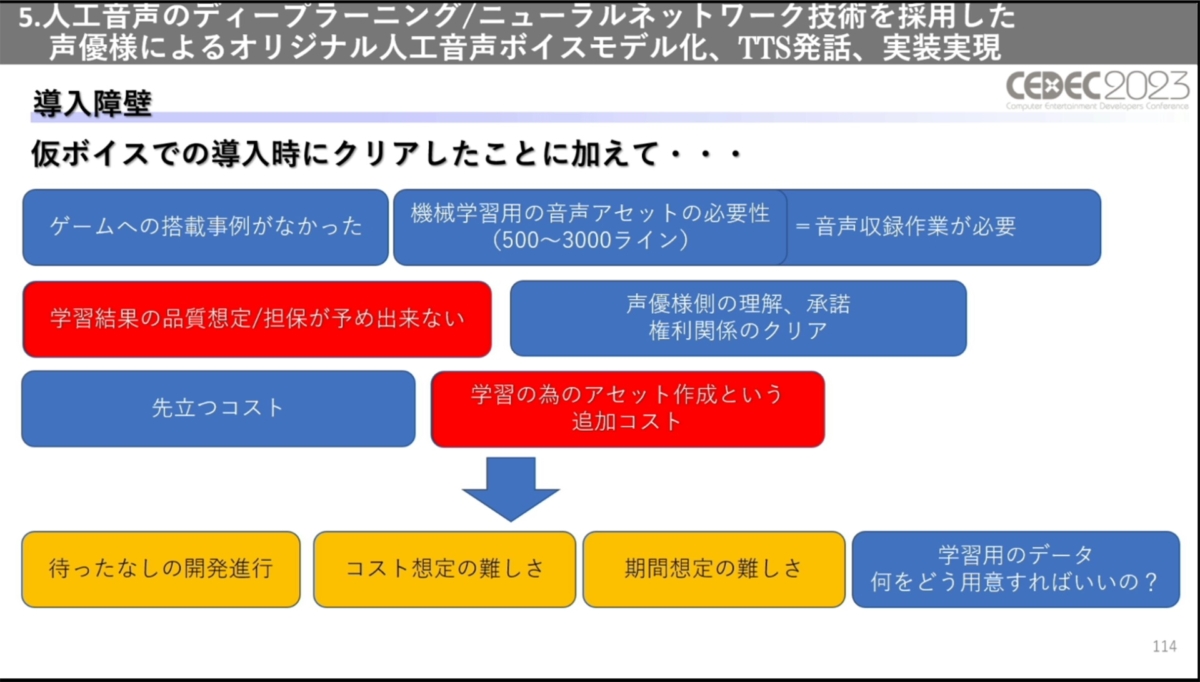
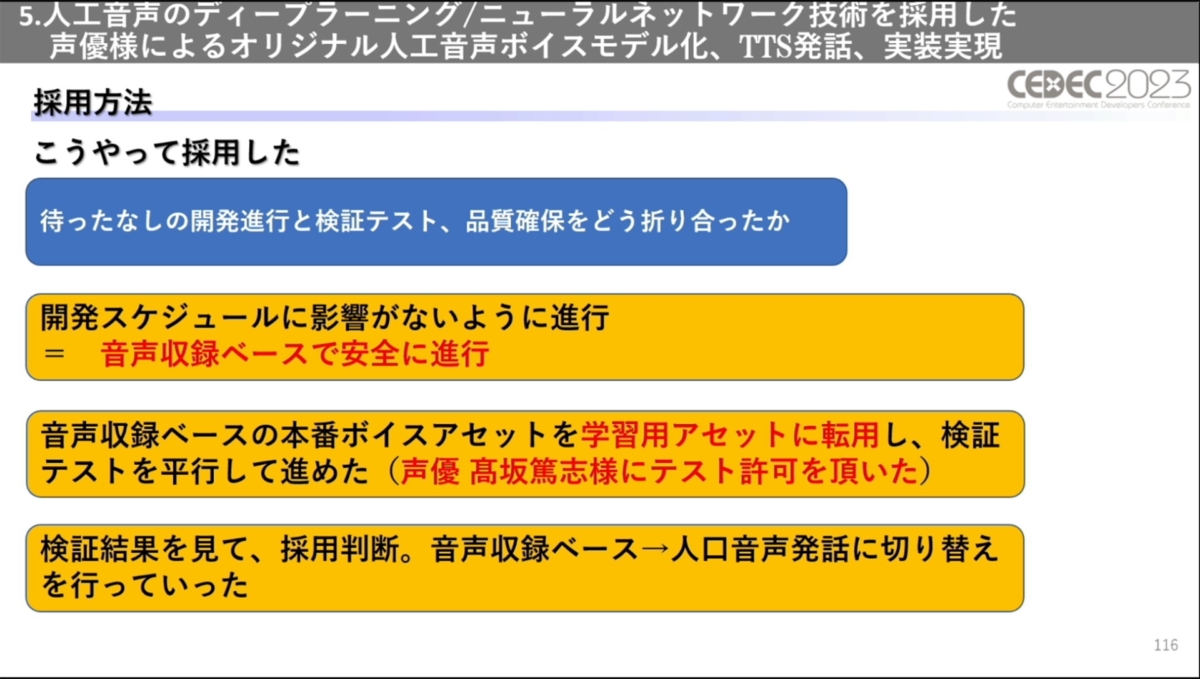
実際の開発においては、進行がタイトだったため本番用とは別に学習用の音声を収録することはできなかったそう。そこで、一旦は従来の音声収録ベースで進行。本番用に収録したボイスをそのまま学習に転用し、制作と並行して技術検証を行うかたちとなりました。
その後、さまざまな検証を経て音声収録ベースから人工音声に順次切り替えを行い、実際の製品では収録音声と人工音声がハイブリッドで使われることになりました。
なお、本作では約1,300ライン44,440ワードで学習を行い、学習時間は約40時間でした。
人工音声を導入した結果、キャラクターボイス収録作業の撤廃によって工程が短縮されるなど効率化に大きく寄与したほか、仮ボイスから本番用ボイスまで一貫して管理できるなどのメリットがありました。
一方で、学習結果のプレビューができない点や、抑揚のあるキャラクターボイスモデルの作成に学習データが必要な点などがメリットとして挙げられました。
神田氏は最後に「人工音声が今後より自然な発話、抑揚ある演技が実現可能になれば非常に強力な開発ツールとなる可能性がある。今後、本物と聞き分けがつかないような時代が来るかもしれない」と語り、講演を締めくくりました。
EXOPRIMAL 公式サイト大量恐竜vs多人数チーム対戦が織りなす近未来オンラインマルチアクション 『EXOPRIMAL』における動的大量制御のインタラクティブサウンド表現と人工音声技術の活用 - CEDEC20235歳の頃、実家喫茶店のテーブル筐体に触れてゲームライフが始まる。2000年代にノベルゲーム開発を行い、異業種からゲーム業界に。ゲームメディアで記事執筆を行いながらゲーム開発にも従事する。


西川善司が語る“ゲームの仕組み”の記事をまとめました。
Blenderを初めて使う人に向けたチュートリアル記事。モデル制作からUE5へのインポートまで幅広く解説。
アークライトの野澤 邦仁(のざわ くにひと)氏が、ボードゲームの企画から制作・出展方法まで解説。
ゲーム制作の定番ツールやイベント情報をまとめました。
CEDECで行われた講演のレポートをまとめました。
UNREAL FESTで行われた講演のレポートやインタビューをまとめました。
GDCで行われた講演などのレポートをまとめました。
CEDEC+KYUSHUで行われた講演のレポートやイベントレポートをまとめました。
GAME CREATORS CONFERENCEで行われた講演のレポートをまとめました。
Indie Developers Conferenceで行われた講演のレポートやインタビューをまとめました。
ゲームメーカーズ スクランブルで行われた講演のアーカイブ動画・スライドやレポートなどをまとめました。
東京ゲームショウで展示された作品のプレイレポートをまとめました。
BitSummitで展示された作品のプレイレポートをまとめました。
ゲームダンジョンで展示された作品のプレイレポートをまとめました。
日本と文化が近い中国でゲームを展開するための知見を、LeonaSoftware・グラティークの高橋 玲央奈氏が解説。
インディーゲームパブリッシャーの役割や活動内容などを直接インタビューします。









