
国内最大規模のゲーム業界カンファレンス「CEDEC 2022」が、2022年8月23日(火)から8月25日(木)までの日程で開催されました。2日目となる8月24日には、コナミデジタルエンタテインメント技術開発部の岩倉 宏介氏、宗政 俊一氏、第三制作部の池畑 望氏の3名が登壇し、「強化学習AIを活用してゲームデザインを!:『桃太郎電鉄~昭和 平成 令和も定番!~』『実況パワフルサッカー』」と題した講演が行われました。強化学習AIをゲームデザイン分析やゲームバランス調整に活かした事例について解説された本講演をレポートします。

強化学習AIが『桃太郎電鉄』や『実況パワフルサッカー』サクセスを徹底的に周回プレイ!統計的にバランス調整を行い、ゲームデザインを分析する【CEDEC2022】




TEXT / 神谷 優斗
EDIT / 田端 秀輝、神山 大輝
目次

登壇したのは、株式会社コナミデジタルエンタテインメント技術開発部の岩倉 宏介氏、第三制作部の池畑 望氏、技術開発部の宗政 俊一氏の3名。
本講演は「強化学習AIによるゲームデザインに興味はあるものの、どのように活用できるかをイメージできていない方」に向けて、『桃太郎電鉄~昭和 平成 令和も定番!~』(以下、『桃鉄』)と『実況パワフルサッカー』(以下、『パワサカ』)での活用事例が紹介されています。
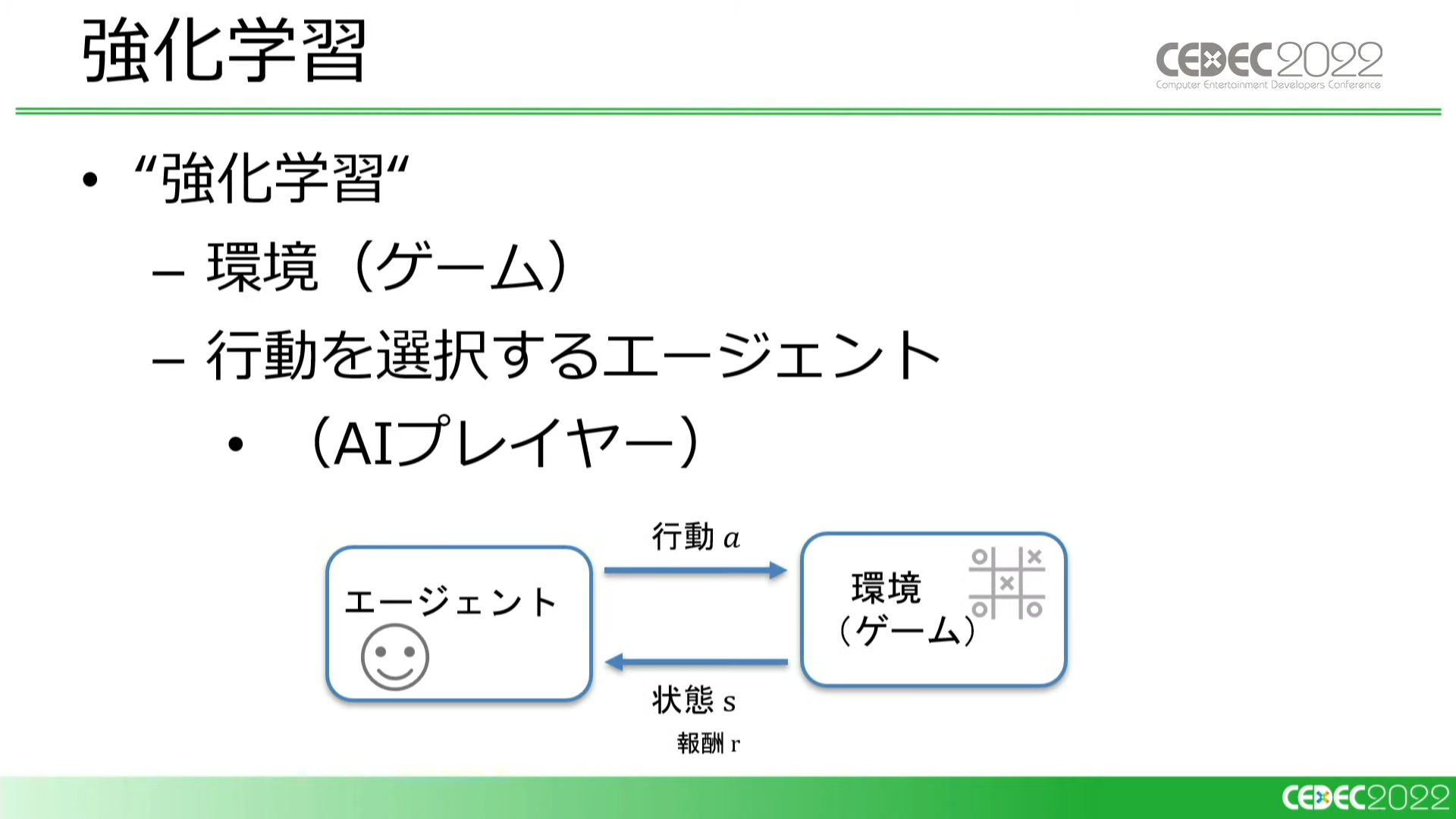
強化学習とは?
講演冒頭、強化学習について岩倉氏から簡単な解説が行われました。
強化学習とは、エージェント(今回のケースではAIプレイヤー)が環境(ゲーム)に対して繰り返し行動(プレイ)することで学習していくことを指しています。AIはゲーム内の要素を数値化して学習をしていくのですが、具体的に何を学習しているのでしょうか?
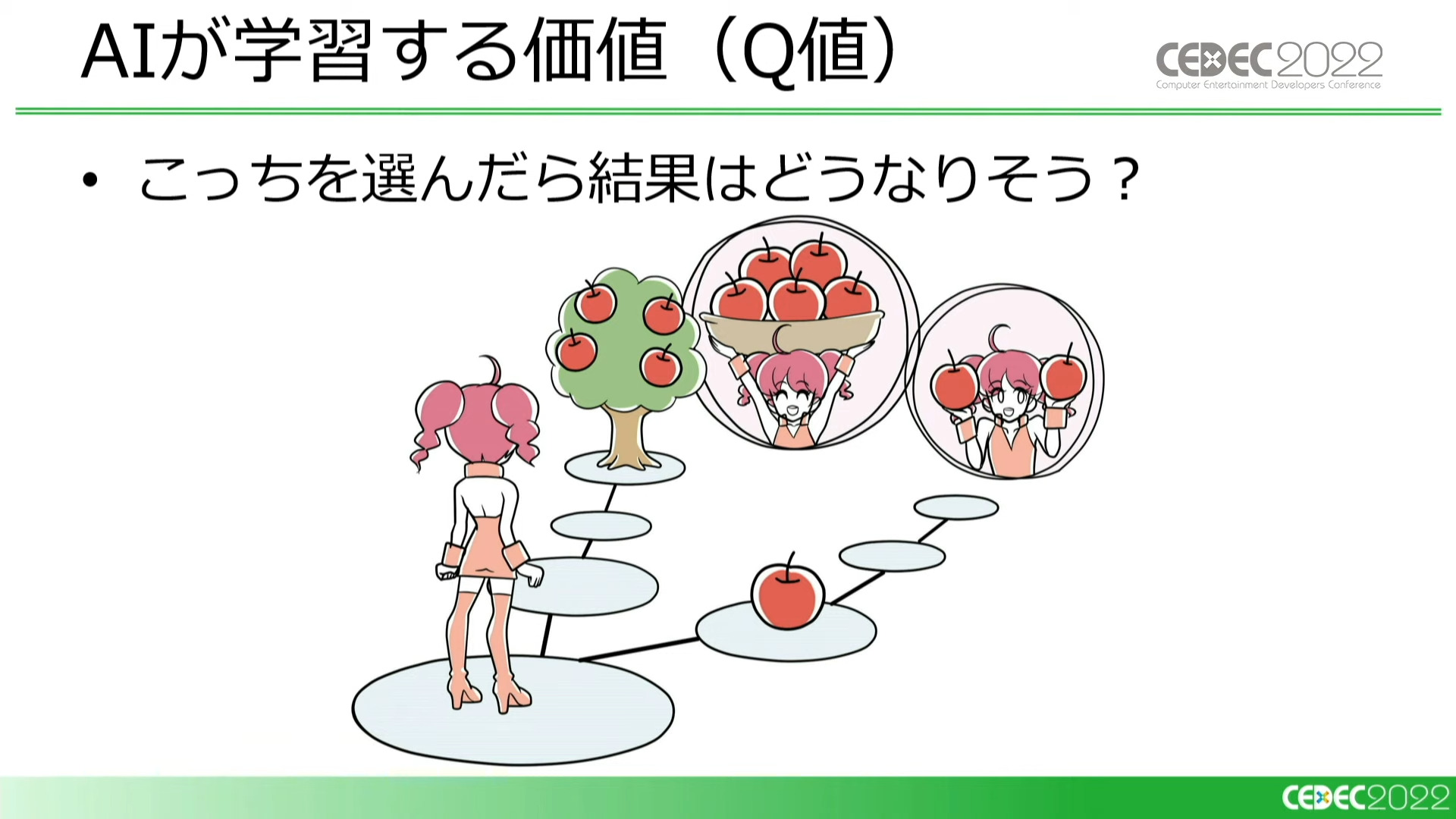
強化学習では、まず、今の状態がどれくらい良いのかという「状態の価値(V値)」を学習します。
例えば、単純なすごろくであれば、ゴールに近いほうが価値が高いと言えます。しかし複雑なルールになると、ゴールから遠いプレイヤーの方が先に「あがり」に辿り着くというケースもあります。
通常のゲームプレイでも、プレイヤーは自らの経験から現在の状況がどれほど有利・不利かを判断しています。AIも同じように、ゲームを繰り返しプレイすることで現在の状況の価値を想定できるようになっていくのです。

同時に、特定の状態でどんな選択をするとどんな価値が得られるかという「行動の価値(Q値)」も学習します。目先の利益だけではなく、最終的にゲームをクリアしたときの結果を考慮して、行動の価値を決めていきます。
短期的な目線で判断すると、目先のリンゴを優先してしまう。ゲームには長期的な目標があり、それを考慮に入れた判断ができるよう行動を学習する必要がある
状態や行動は数多く存在しているため、適切に学習できたとしても、すべての価値が発見できるとは限りません。
そこでAIは、様々な行動パターン(ポリシー)を試すことにより、得られる価値を最大化しようとします。
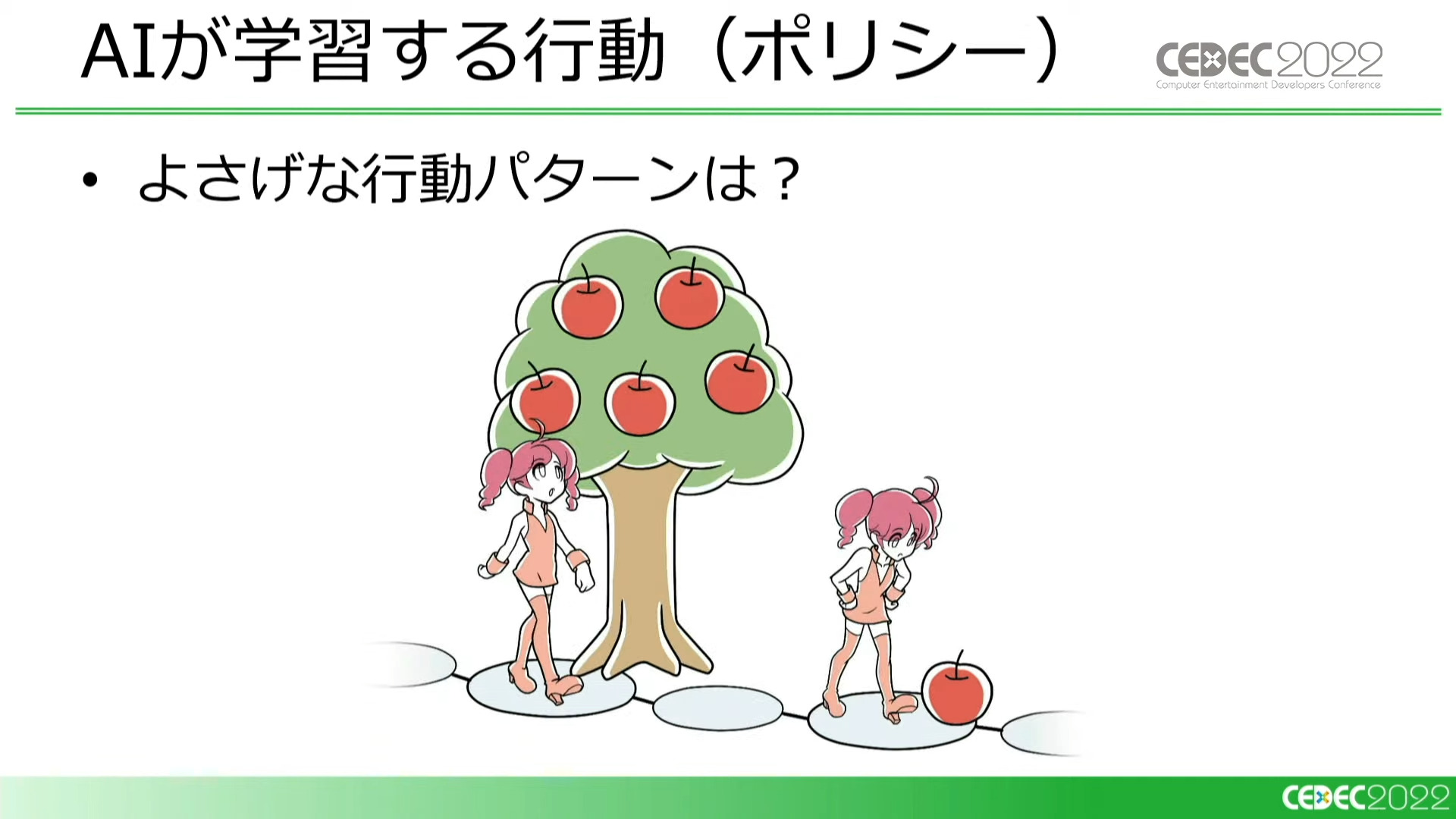
下を向いて行動するようなパターンばかり試していると、上を向くようにして行動した際の価値を見落としたまま進んでしまう
強化学習というのは、繰り返しのプレイを通して状況や行動の価値をより正しく推測し、「ゲームに勝つ」「強いキャラクターを育てる」といったより高い価値を得られる行動パターンを選ぶことであると言えます。
桃太郎電鉄での活用事例
強化学習について解説したところで、開発初期から強化学習AIを活用する提案として『桃鉄』での研究内容が紹介されました。なお今回の事例では、実際には開発時にAIを導入したわけではなく、リリース後に研究として取り組んだものです。
『桃太郎電鉄~昭和 平成 令和も定番!~』は、各プレイヤーがターンごとにさいころの出目だけ全国を移動し、投資などを駆使し総資産1位を目指すパーティゲーム『桃太郎電鉄』シリーズの最新作。どの程度物件に投資するか、いつ戦況を一変するカードを使用するかなど、戦略性の強いゲームとなっている
今回のケースでは、ゲームのロジック部分のみを移植したC#でのシミュレータを用意し、それに対して強化学習を試みました。学習環境はクラウド上で処理を実行できる「Google Cloud Platform」とローカルPCを併用したそうです。
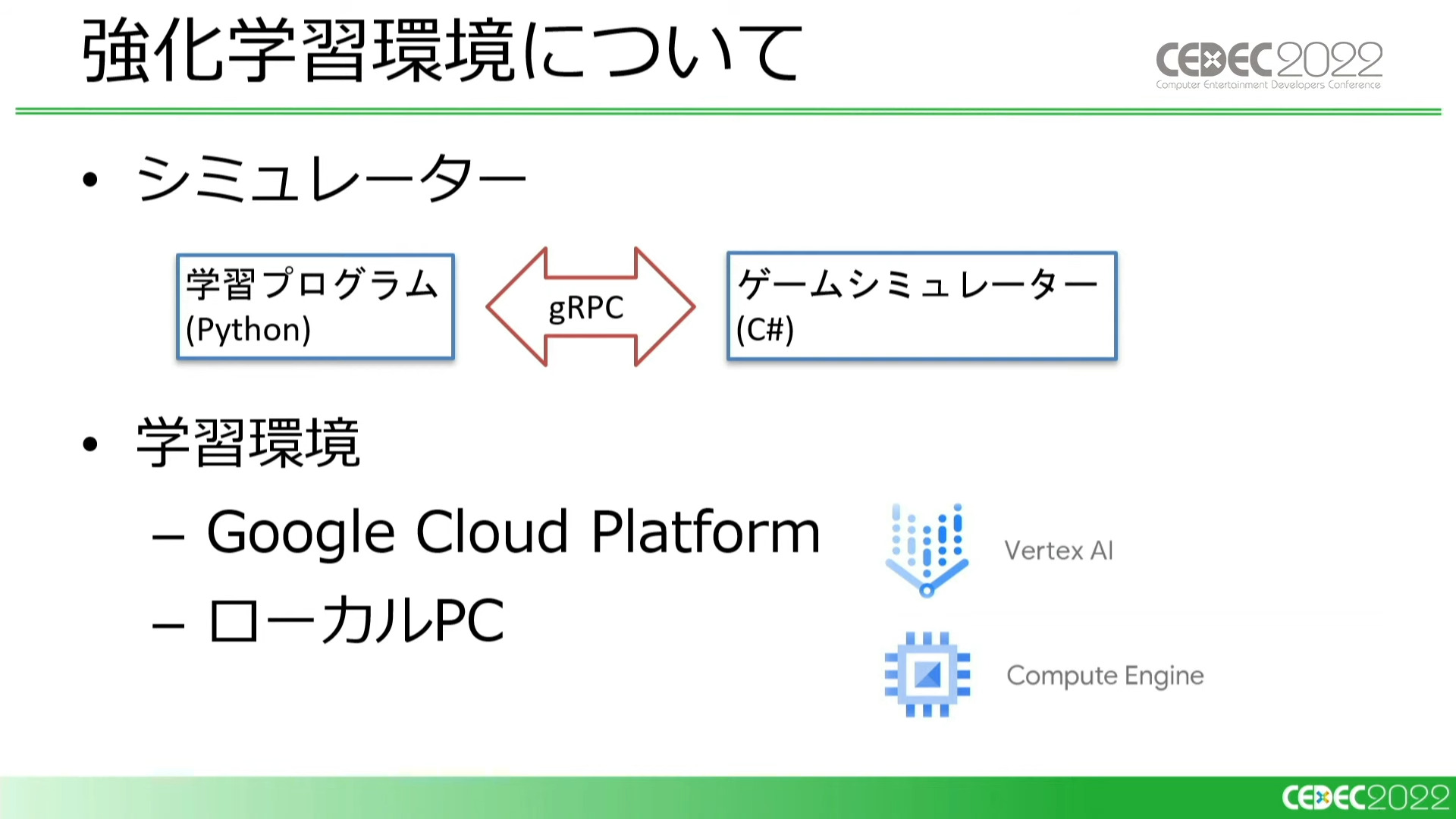
開発初期から強化学習AIを用いる理由については、「ゲームシミュレータに仕様を追加するに従い、強化学習AIの学習結果、つまり最適なプレイスタイルに興味深い変化が見られたから」と説明されています。

最初は「北海道のマップのみ」という非常に単純な仕様で学習を行ない、順番に仕様を加えていった結果、強いプレイヤー(最適なプレイスタイル)が変化していったという
”ミニ桃鉄”から貧乏神の実装まで、具体的な検証の流れ
続いて、『桃鉄』のようなランダム要素の強いゲームにおける強いプレイヤーを作るための試行錯誤とゲームバランスの変化について宗政氏から解説がありました。宗政氏によれば「まずは検証用のミニ桃鉄(単純な仕様のみを持ったシミュレータ)を作成した」とのこと。最初から複雑なつくりにすると、うまく学習できなかった際ゲーム側に原因があるのか、強化学習側に原因があるのかの究明が困難になるからです。

学習する要素は複数考えられましたが、今回は「移動ルート選択」と「カード選択」を学習させることにしました。

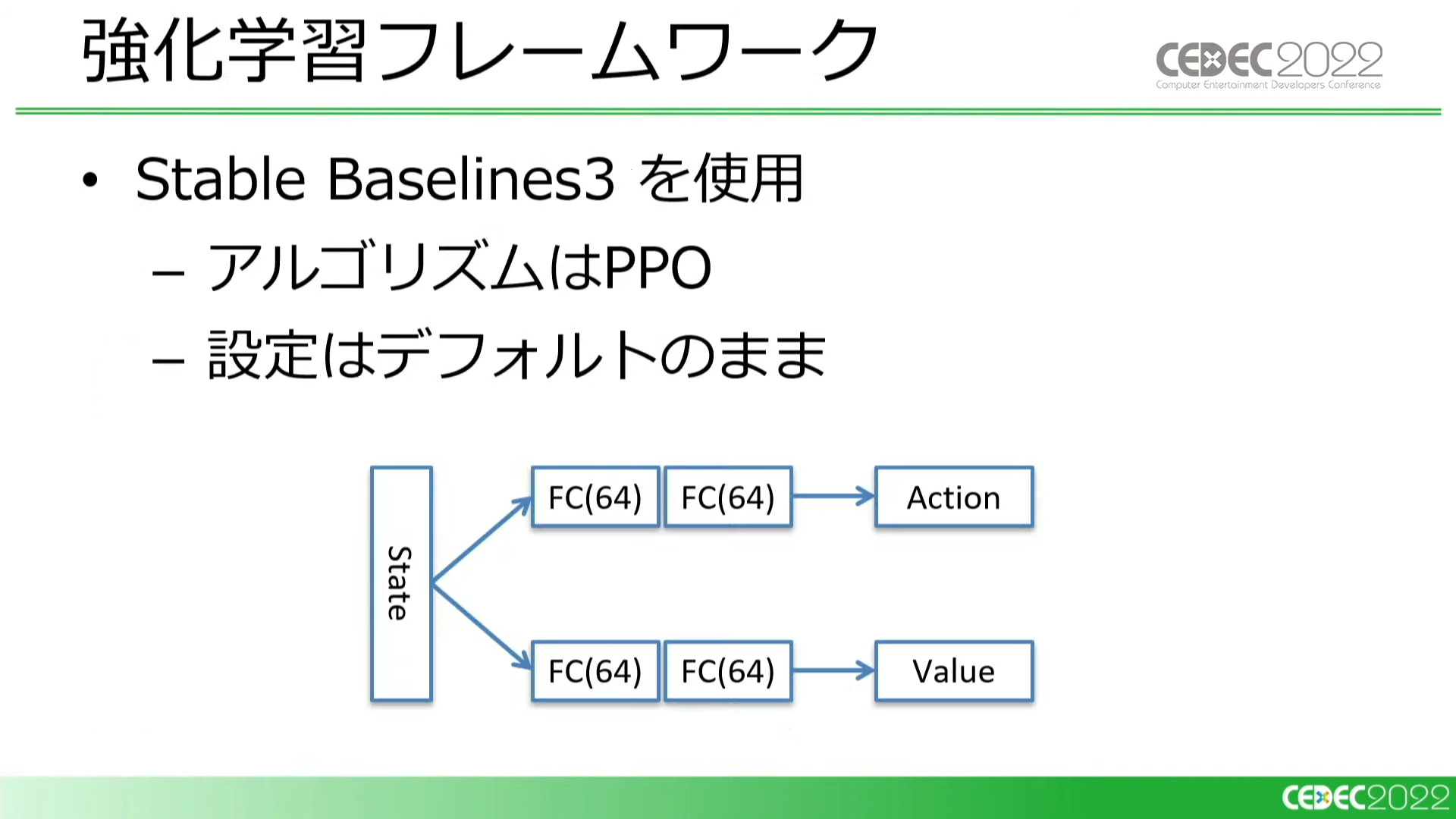
実証実験でもあるため、手っ取り早さを重視し、PPOの既存のフレームワークを採用。設定値もデフォルトのまま
さいころを振ったあとのルート選択ひとつとっても選択肢は不定数であり、そのままでは学習できないため、あらかじめメタアクションを定義して数を固定させました。
最初のバージョンで用意したメタアクションは「目的地優先」(目的地を目指すことを優先する)、「持ち金獲得優先」(止まると持ち金がもらえる「プラス駅」に止まることを優先する)、「物件購入優先」(物件が多く買える駅に止まることを優先する)の3種類に加えて、急行系カード(出目を増やす効果があるカード)の使用の有無でそれぞれ2種に分け、「ランダム」に行動するものを含めた7種類です。

ゲームルールは、やりこみ性の高い「10年トライアルモード」での3人対戦を想定しました。学習させるAIに対し、ルールベースで動く対戦相手(COM=コンピュータープレイヤー)を用意しています。COMのルールベースは「目的地優先」「持ち金優先」「物件購入優先」の3種類です。

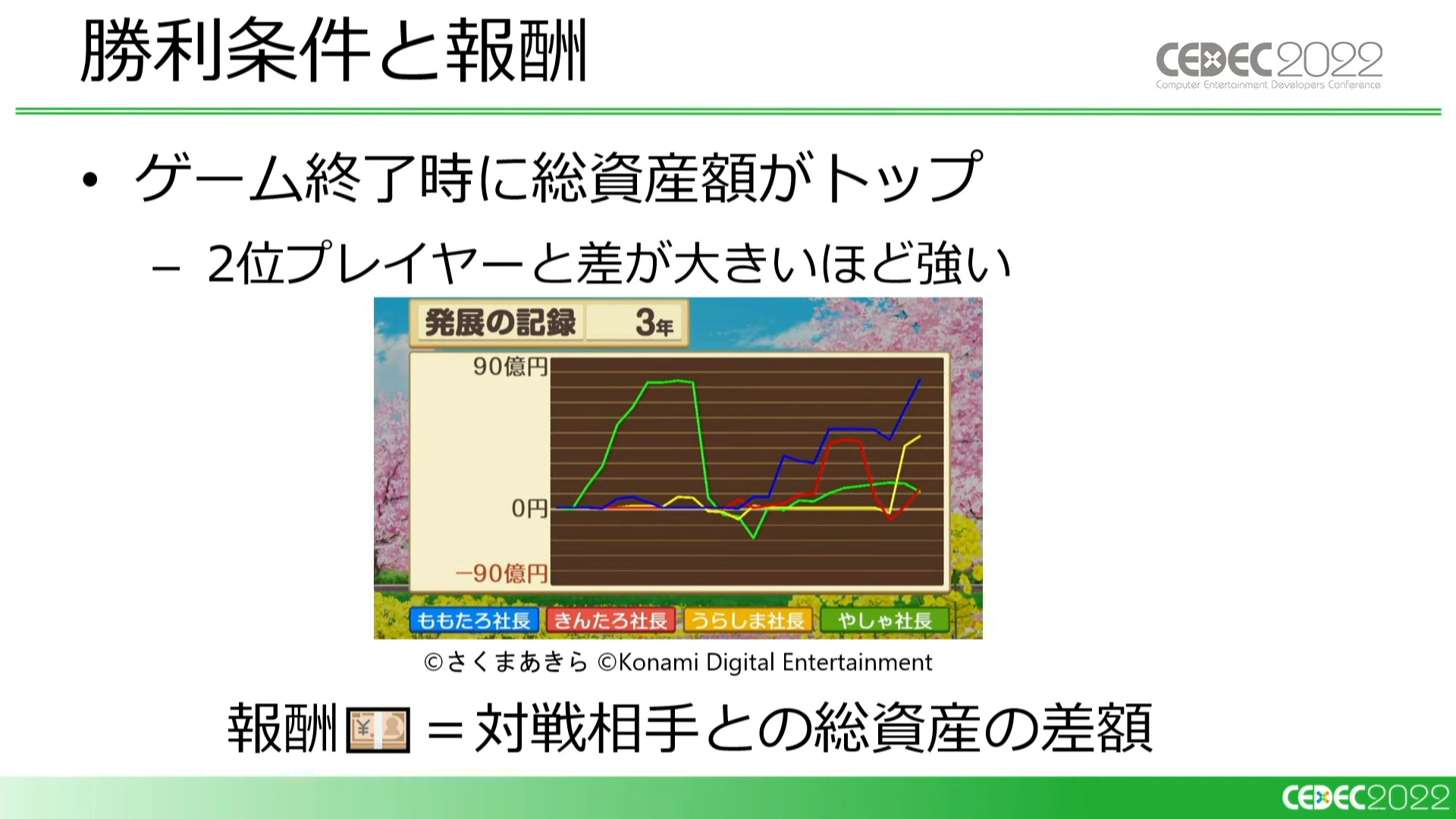
『桃鉄』の勝利条件は、ゲーム終了時の総資産額がトップであること。さらに2位のプレイヤーとの差額が大きいほど強いという事になります。今回のケースでは、強化学習の報酬をゲーム終了時における対戦相手との総資産額の差額としました。
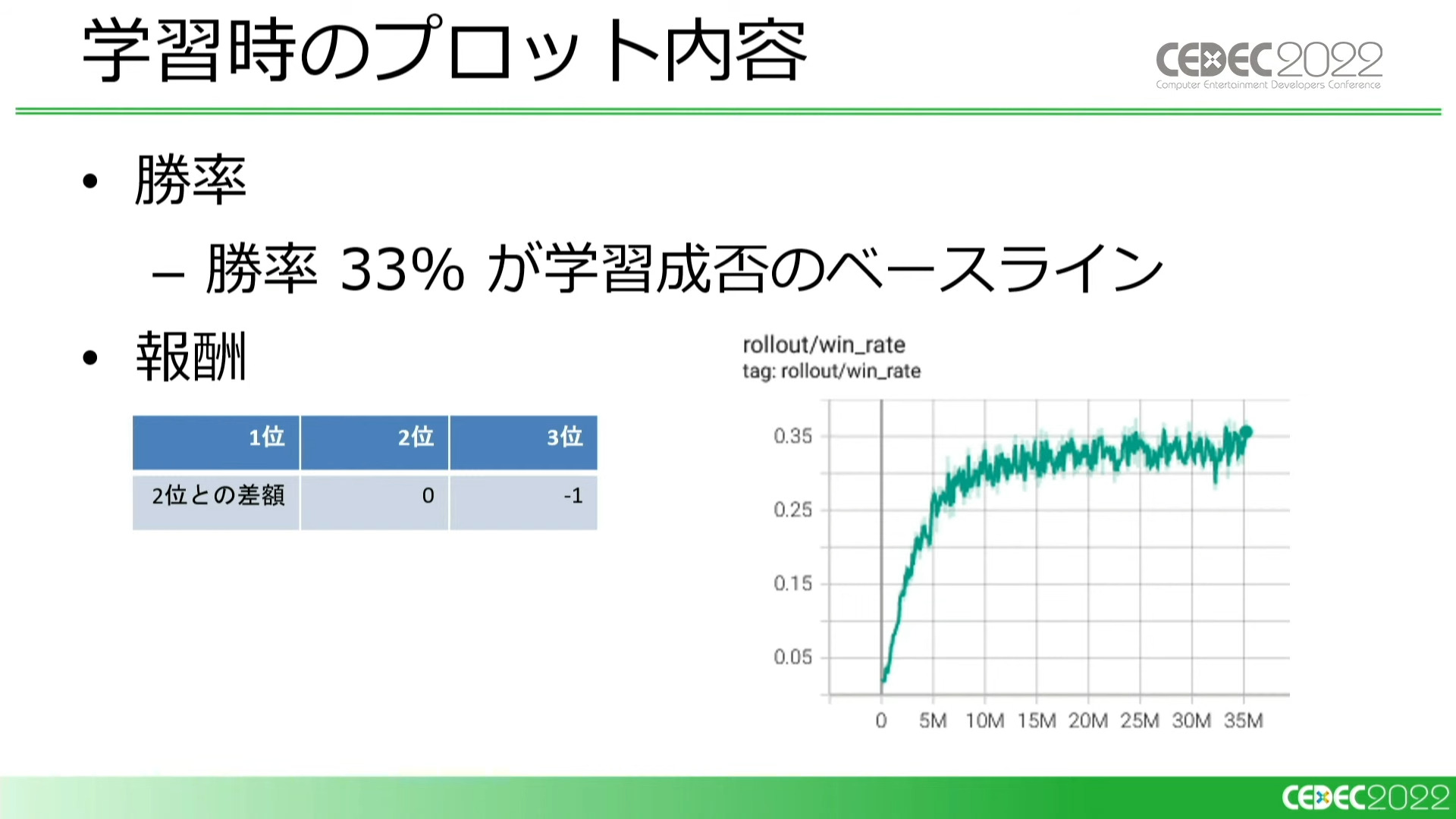
学習時に見ているのは、主に「勝率」と「報酬」です。3人対戦なので、勝率33%以上であれば学習が成功していると判断できます。報酬については、2位との差額だけでは学習が失敗するパターンが出てきてしまったので、2位と3位に順位ベースの報酬を設定することになりました。
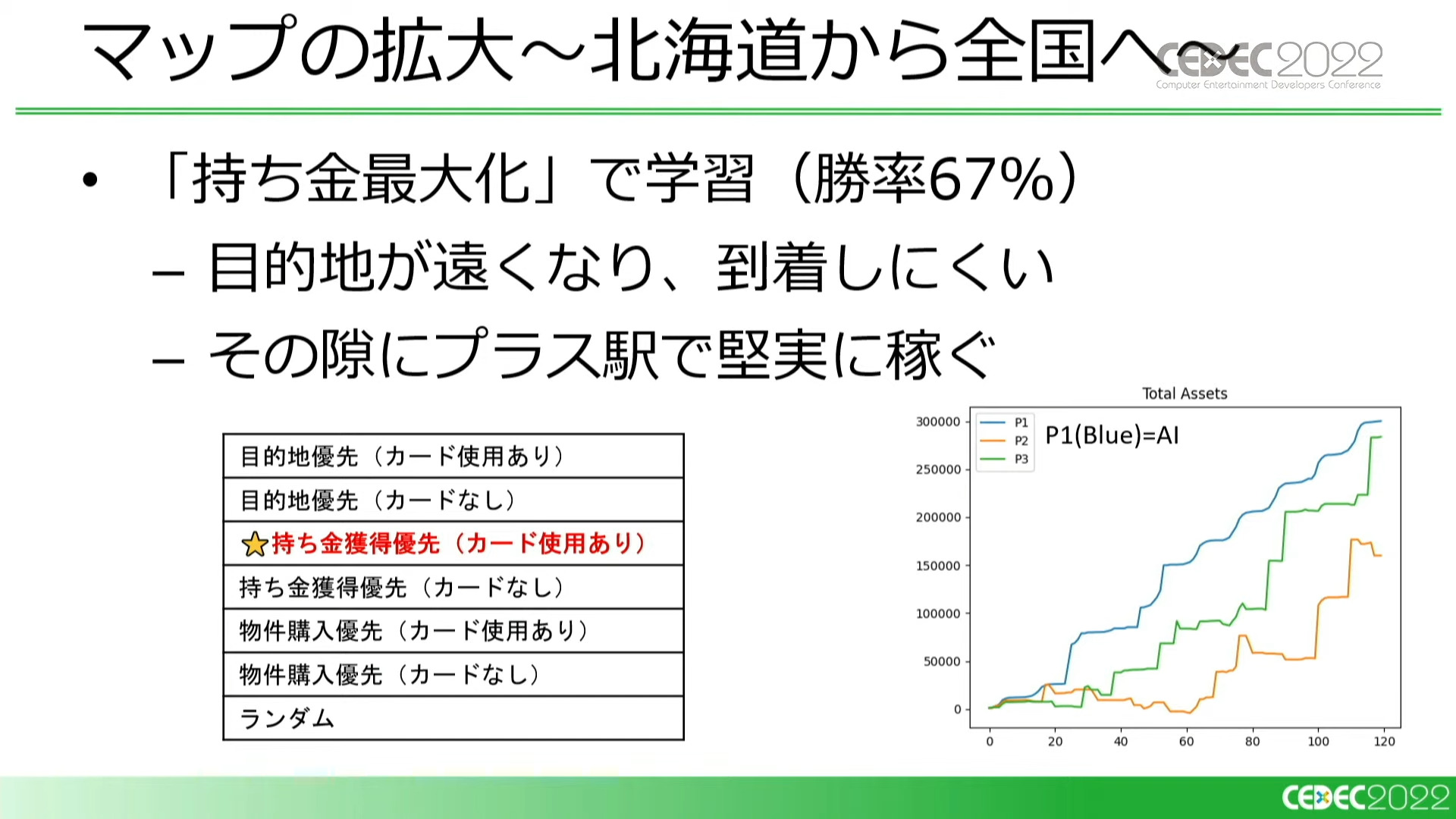
基本の仕様のみで作成したシミュレータで試験的に学習を行なったところ、AIは「目的地優先」で学習しました。「持ち金優先」「物件購入優先」のCOMに対して、ほぼ全勝しています。つまり、この時の仕様では、「最短ルートで目的地に向かうプレイスタイルが最も強い」ということになります。

学習可能であるという目処が立ったため、ここからは『桃鉄』開発チーム協力のもと、実際のゲームの仕様を移植しながら学習を続けることになります。
北海道のみだったマップを全国に拡大すると、一転してAIは「持ち金優先」で学習するようになりました。
原因として、マップが広くなったことで目的地が遠くなり、それでいて終了までのターン数は同じであるため、目的地到着による援助金を得られる機会が少なくなったことが考えられます。そのため、この仕様では周囲のプラス駅(お金がもらえる駅)をフラフラと巡りながら堅実に稼ぐ、すごろくらしくないプレイが最善になったと言えます。
そこに「目的地連続到着ボーナス」(他プレイヤーより早く到着し続けるともらえる援助金が増えていくシステム)という仕様を追加すると、「目的地優先」が有利に戻りました。
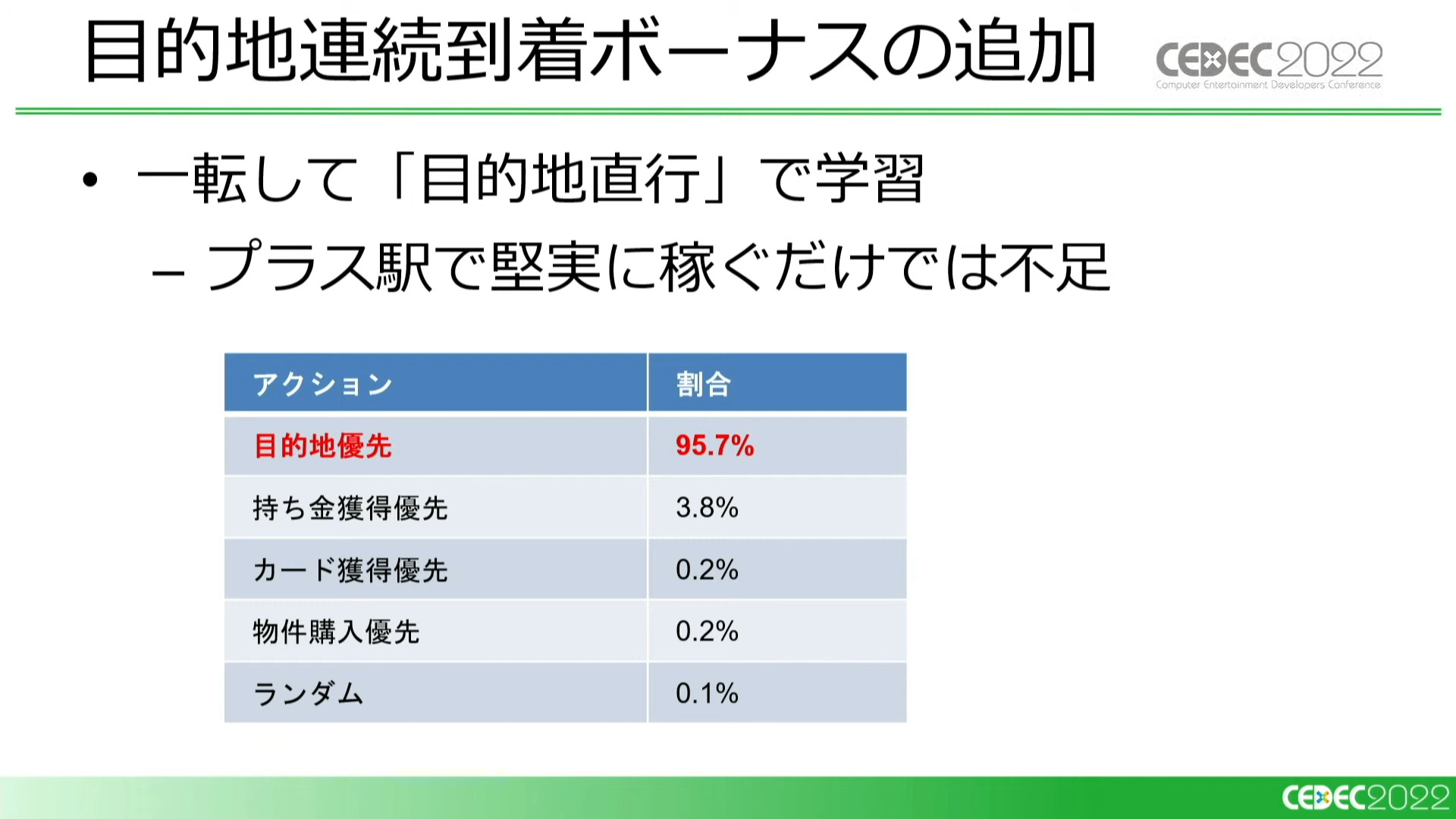
さらに、「宝くじ駅」などの駅種を追加しました。このタイミングでアクションのリストも一新することにし、移動先に駅種の概念を加え、物件購入の有無との組み合わせで27種のアクションを定義しました。
この時点でのAIはプレイスタイルに大きな変化はなく、「目的地に向かう」、次点で「宝くじ駅に向かう」重視で学習しています。

駅種によって止まった際に固有のイベントが発生する
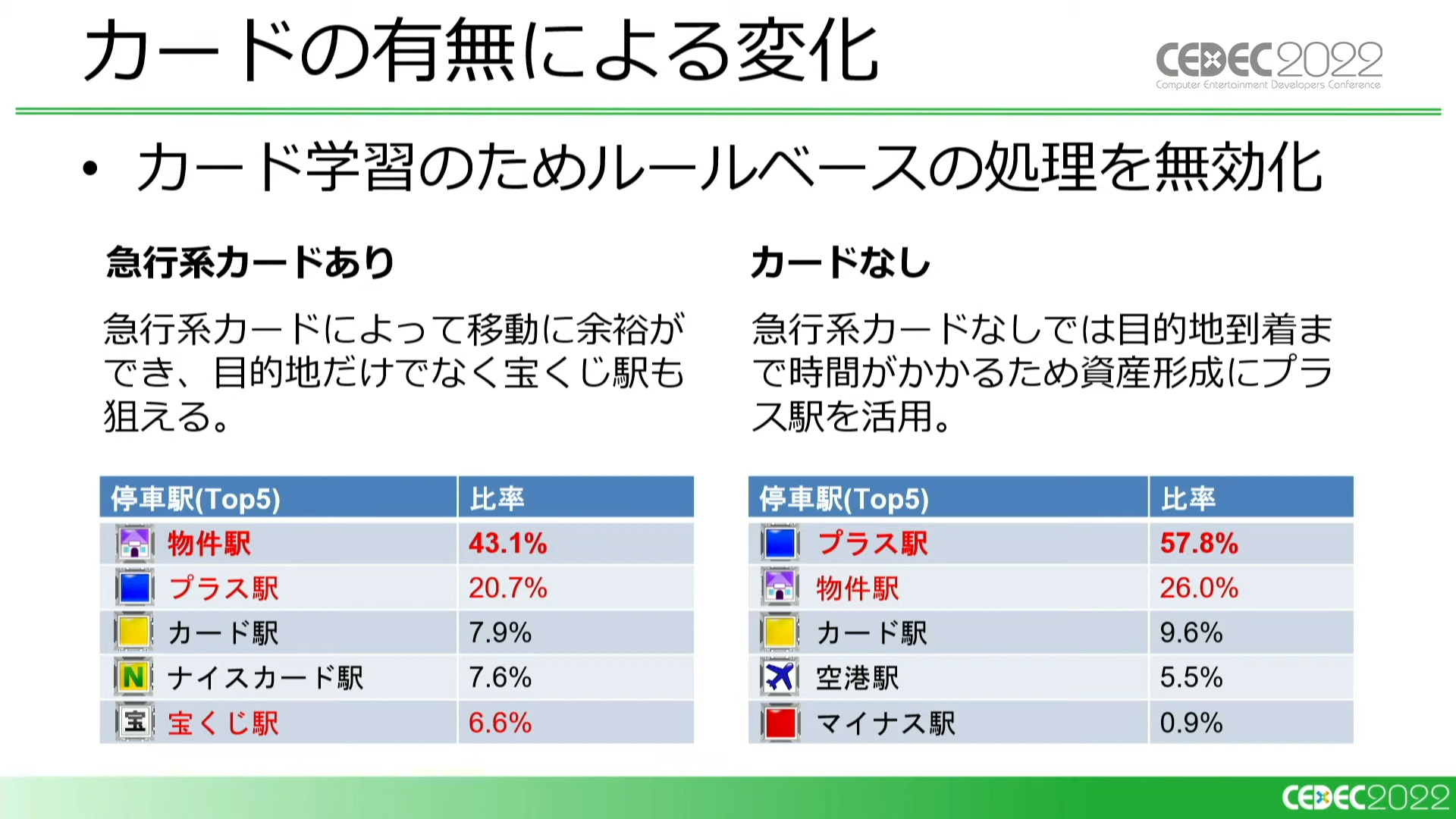
次に、カードの学習のためカードの追加を行うのですが、その前にルールベースでのカードの使用処理を無効化したところ、急行系カードの使用ができた時よりも物件駅や宝くじ駅などに寄り道しなくなるという結果が得られました。
ここで、急行系だけだったカードを全106種すべて実装しました。

カードは最大8枚までしか持てないため、「使用しない」というアクションを含めた107アクションから最大9アクションが有効になる
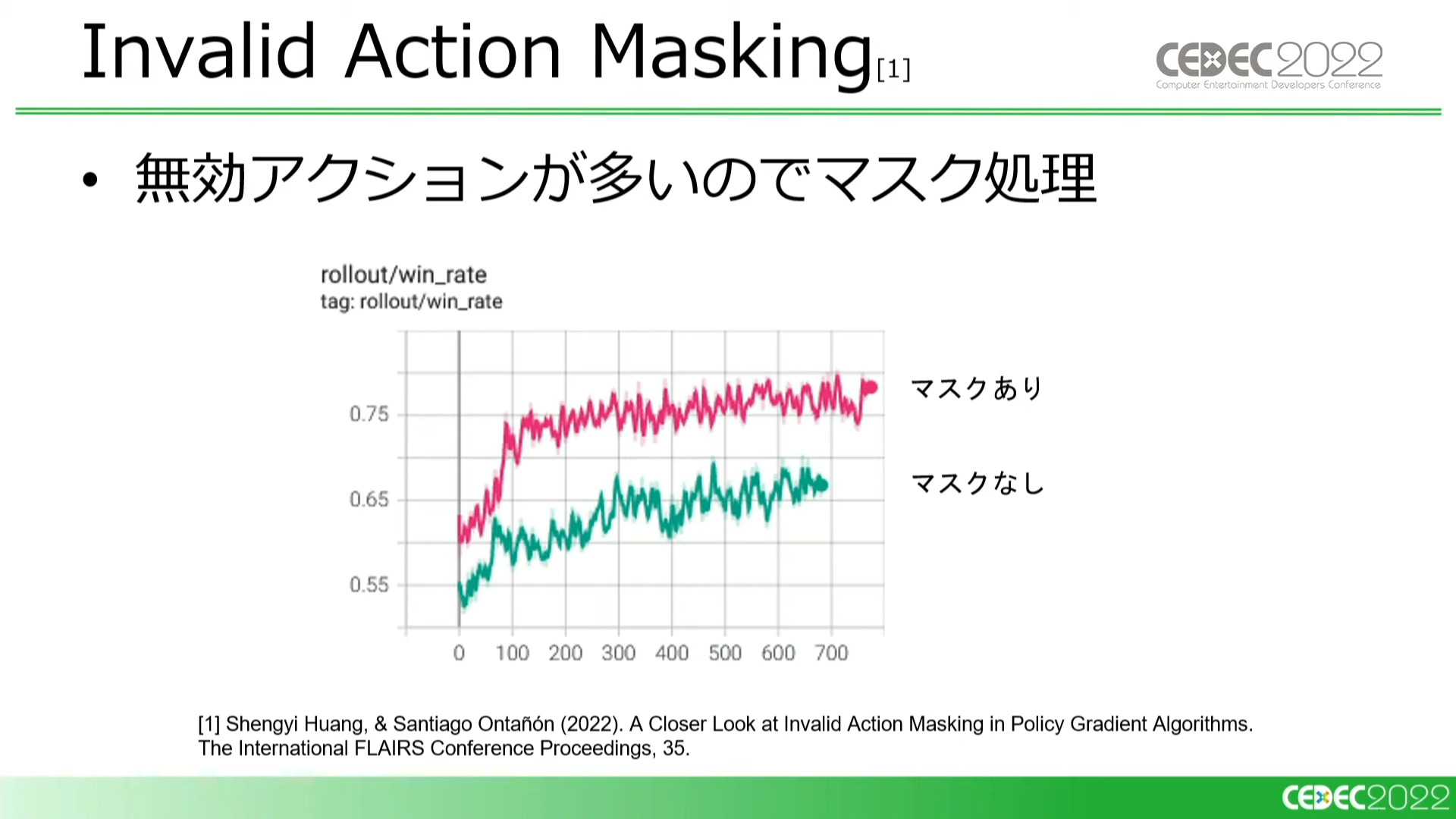
持っていないカードに関する大量の無効なアクションに対してマスク処理を入れたところ、効率がよい行動の探索が可能となり、勝率も目に見えて上がった。「アクション数が多いが無効なアクションも多い」ケースにはオススメ
カードを追加したシミュレータで学習したところ、他プレイヤーと持ち金を交換するカードを使い、目的地に向かったCOMから資産を奪うという新しい戦略を取るというようにプレイスタイルの変化が起こりました。

ここで入手カードの消化率を確認すると、手に入れたカードは満遍なく使われていることが分かります。

ここで、『桃鉄』の重要な要素の一つである「貧乏神」を追加します。貧乏神は目的地に向かうのが遅れたプレイヤーに強力なデメリットを与えます。

貧乏神にどう対処するかはこのゲームの醍醐味とも言える
すると、学習初期ではAIプレイヤーに貧乏神がつくことで勝率が著しく下がる問題が発生してしまいました。勝てないと報酬が見つけられないため、学習が止まってしまうという事態に陥ります。
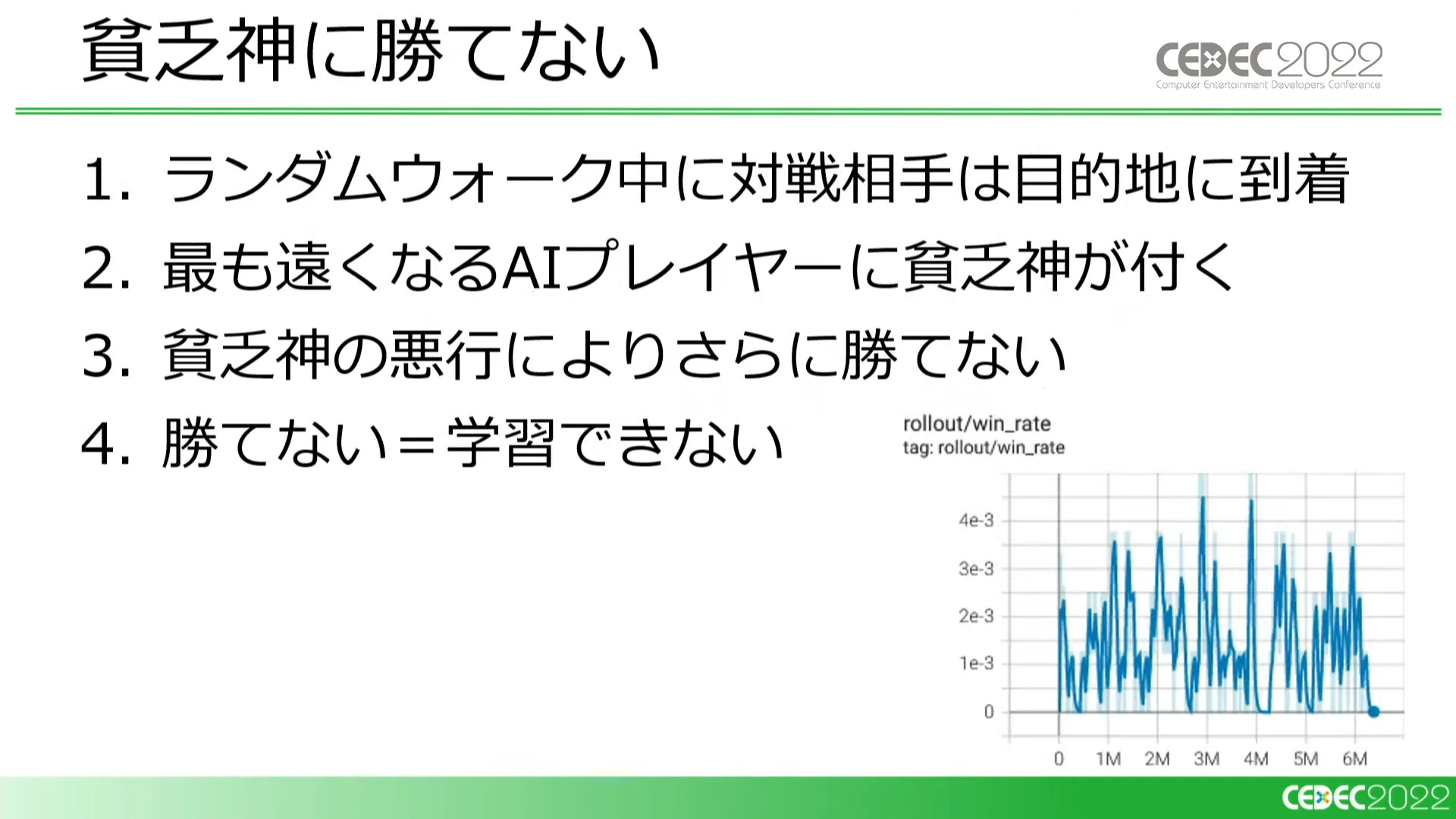
学習初期では対戦相手に先を越されてしまい、AIプレイヤーに貧乏神がつくことが多い
そこで、カリキュラム学習と自己対戦学習を取り入れることによって、これを克服しました。カリキュラム学習では、ルールベースのCOMに一定の割合でランダム行動をさせることで強さを調節。弱いCOMで勝ち筋を学ばせたあとに、COMを強くしていくことで学習を進めました。

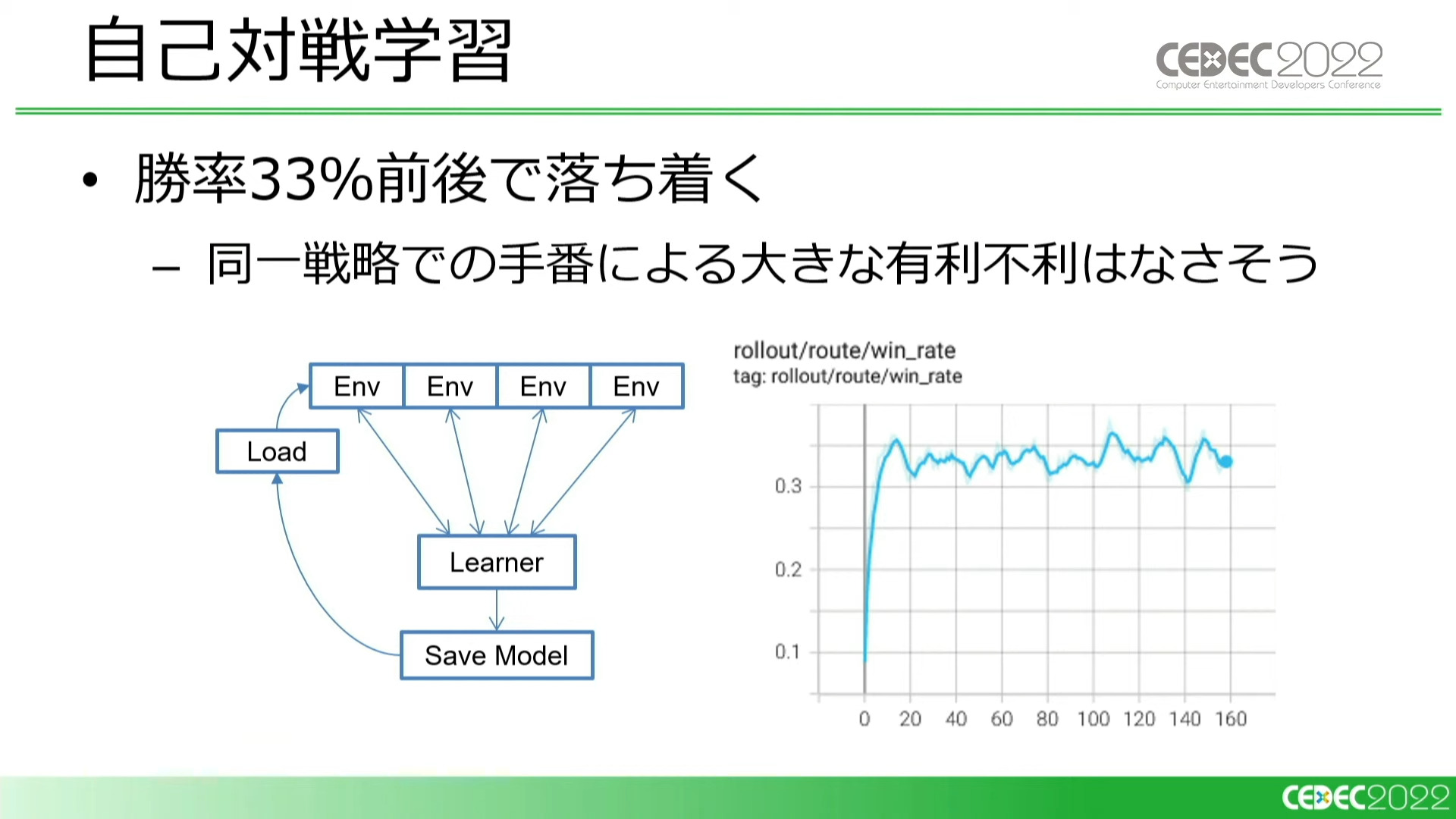
また、学習中の自分自身と対戦する「自己対戦学習」、つまり対戦相手も含めた全員が同一の戦略で行動する形でも学習を行いました。この場合の勝率は約33%で、これは手番によって有利不利が発生していないことを示しています。
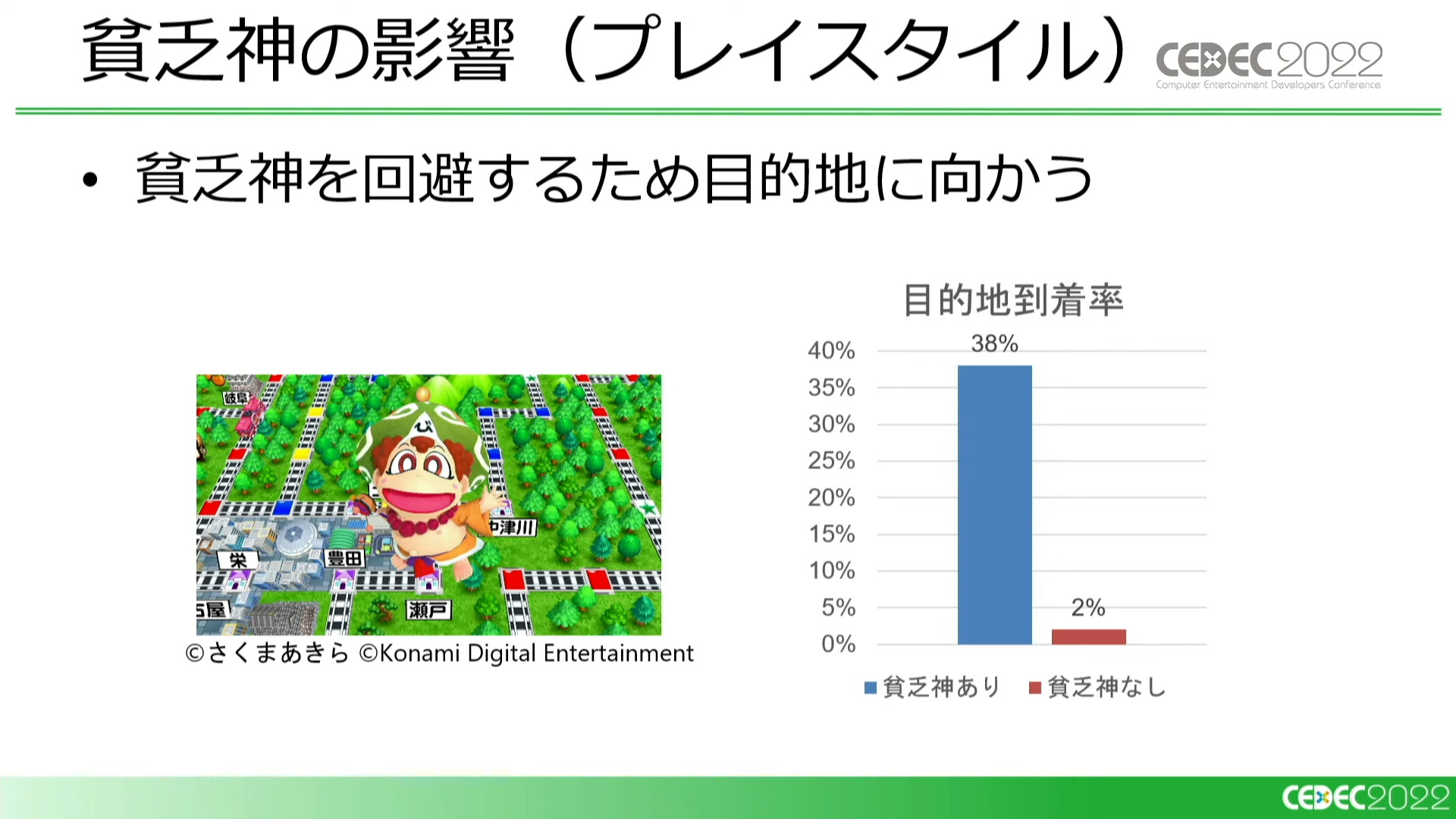
こうした学習を繰り返したことで、貧乏神の影響も明らかになりました。貧乏神がいなければ勝率9割をキープできていた「目的地直行」型の対戦相手に対し、貧乏神がつくことで7割まで勝率が低下しています。
このことは、ただ目的地に向かうだけのプレイヤーでも3割は勝てるような、適度な運要素も絡むバランスに変化したことを示しています。また、一人負けするようなケースが減り、プレイヤーの勝利バランスが取れるようになったことも大きな効果と言えるでしょう。

実力要素が強すぎると、弱いプレイヤーはいつまでたっても勝てないという現象を引き起こすため、ゲームデザインにおいて実力要素と運要素のバランスは重要視される
また、プレイスタイル(学習)については、貧乏神を回避するために「目的地に向かう」が有力になるという変化が起こりました。
ゲームの仕様を客観的に見るツールとしての強化学習AI
ここで再び岩倉氏が登壇。これまで見てきたように、『桃鉄』にはゲームプレイに影響を与える様々な要素が混在しています。それらの組み合わせやバランスによって、これまで見てきたように「最適なプレイスタイル」の定義は変化します。

開発初期はプランナー間で開発方針を統一できていても、仕様が追加されていくにつれ、メンバーが想定するゲームのイメージはバラバラになりがちです。例えば、100種類ものカードのバランスを人間が正しく判断するのは難しいでしょう。
強化学習AIは、新しい仕様がどれくらい強いのか、定量的なデータを出してくれます。強化学習AIがよく使うカードなど、バイアスのかかっていないデータは「いまはこんなプレイスタイルのゲームになっている」というのを判断するにあたって強力な材料になります。
このように、開発に際して強化学習AIが検証用のツールになるのではないかという提案をして、岩倉氏は本パートを締めました。

『パワサカ』サクセスにおけるバランス調整支援の事例
続いて、実際の開発において強化学習AIを活用した件として、『パワサカ』でのバランス調整支援の事例が紹介されました。
『パワサカ』は、コナミの『実況パワフルプロ野球』(パワプロ)シリーズでお馴染みの選手育成シミュレーションである「サクセス」モードが採用されたモバイルサッカーゲームです。シナリオを何度もクリアし、より強い(=選手能力の高い)選手を育成することがプレイヤーの目標となります。

『パワサカ』における強化学習AIは、バランス調整活用の研究開発に1年、運用フェーズでも2年間以上の実績がある

サクセスの紹介。最大50ターン、コマンド選択式で選手を育成していく

ゲーム開始前に育成シナリオを選択する。選択するシナリオごとにユニークなシステムがあり、それぞれ最適な育て方も異なる
『パワサカ』は定期的に新規コンテンツがリリースされますが、リリースの際は「育成環境」に及ぼす影響を考慮して慎重な調整が求められます。非常に精度の高いテストプレイが必要ですが、このバランス調整は経験豊富なテスターであってもなかなか難しいものです。

しかし、「サクセス」は一回のプレイに15分以上かかる上にランダム要素が多く、何度もプレイする必要があります。加えてプレイ自体にも豊富な経験と知識が必要であるため、テストプレイでの高精度な検証は難しい状況でした。

テストプレイの検証の難しさは「想定外」のバランス調整ミスを引き起こしてしまい、ユーザーのゲームプレイに悪影響を及ぼす結果となってしまいます。そこで、自動的にトッププレイヤー並みのプレイ方法を発見できる強化学習AIにサポートしてもらうことで「想定外」発生の可能性を抑えることを期待しました。

「サクセスは有限ターン制のゲームであるため、状態やアクションを定義しやすい」「人間には発見しきれなかった最適な攻略方法を見つける可能性もある」ことも、強化学習AI導入の後押しとなった
『パワサカ』における強化学習の紹介
『パワサカ』でも『桃鉄』と同様に、ゲームのロジックを移植したゲームシミュレータに対して学習を行いました。
アルゴリズムは、別々の担当者がそれぞれPPO(Proximal Policy Optimization)とDQN(Deep Q Network)を採用。そのほかに、成果の指針としてルールベースAIも使用しています。
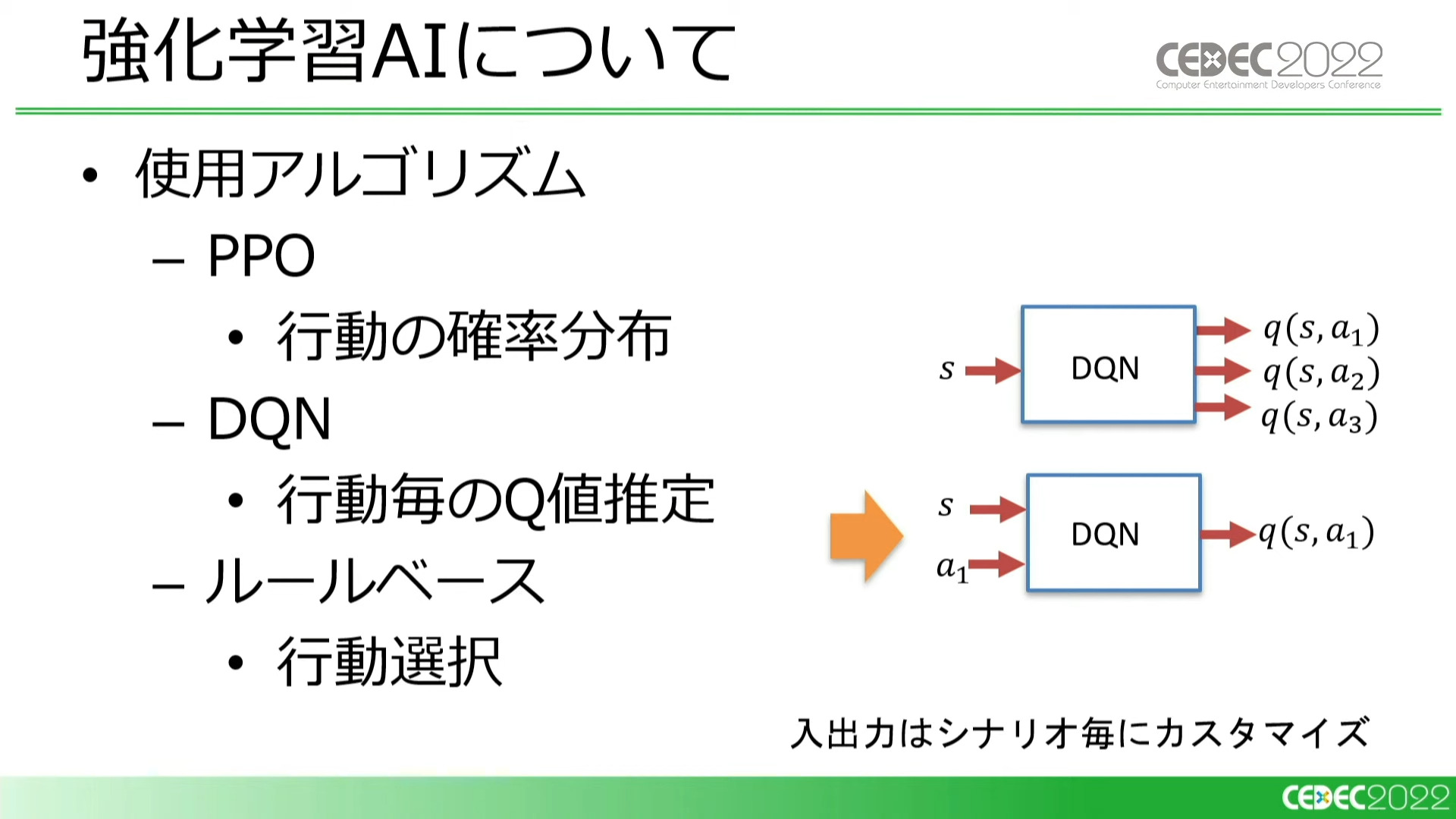
DQNに関しては、ステートとアクションの組み合わせに対してQ値を出力するアルゴリズムを採用した(画像右下の図)。入力次元が多いが実際にとれる行動が少ない場合、こちらのほうがうまく学習できるのではないかという考えに基づく
一つの課題に対して二つのアルゴリズムで取り組むのは冗長と思うかもしれませんが、双方のアルゴリズムに得手不得手があり、互いに不足を補いあうことでよい結果が得られたため、今回の事例においてはこの方針で正解だったとのことでした。

『パワサカ』はシナリオによってゲームの内容が大きく異なり、片方のアプローチでうまく学習できなかったシナリオももう片方のシナリオではうまくいくこともあった。また、AIがどの程度うまく育成できているかわからない段階でも、互いに結果を比較しあい改善につながった
学習方法については、試行錯誤の末に毎日ゼロから学習するシンプルな方法を取ることに。事前準備の必要な学習方法だと、シナリオの再チェックや大きな仕様変更に即座に対応できないからです。なお、毎日学習する方法を取ったため、結果として学習速度優先でチューニングすることになったそうです。

キャラクターの強さには経験点や超特殊能力の数といった複数の要素が絡み、非常に複雑な関係となっています。そのため、報酬はシンプルに育成後の選手能力の高さ一本に絞りました。

一点、問題として、1ターン内で行えるアクションを別々に定義しているため、割引率を1未満に設定していると、多くの行動をしたパターンが低く評価されるケースがありました。割引率とは、将来の価値がどれほど現在の行動に影響を及ぼすかという値(0~1)です。これに関しては、簡易的な対策として割引率を1にすることで正しく評価できるようになりました。
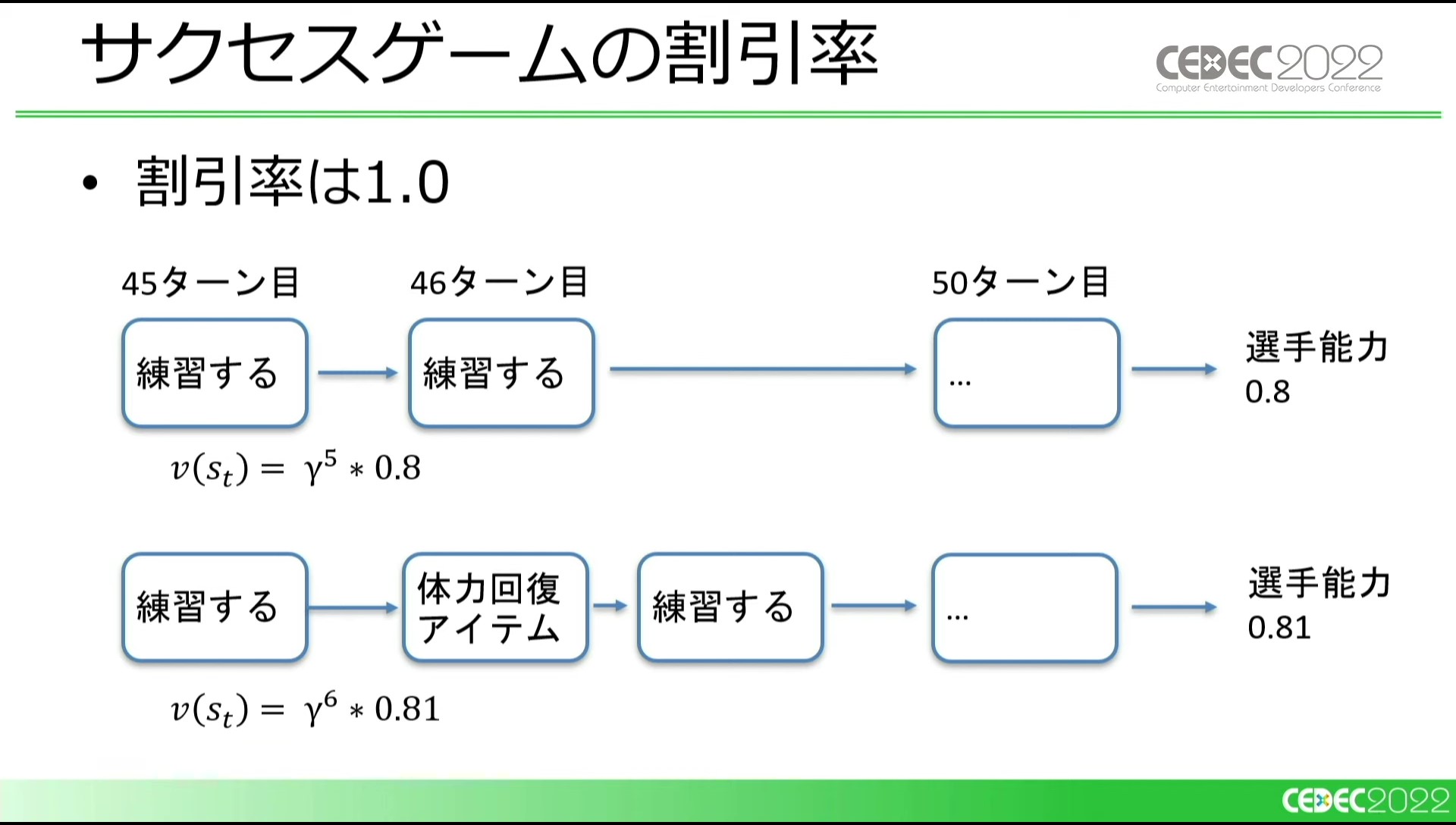
ターン内の行動をひとまとめにしたアクションを定義するのが正しいやり方かもしれないが、学習時間優先のチューニングと相反するためこのような対応にしたとのこと
結果として、苦手なシナリオもありましたが、おおむねトッププレイヤーと同等の選手を育成できました。

開発終盤になると、チーム内におけるAIの注目度も高まり、様々な用途に使えないかという意見が出てきました。そのような場合、各用途の目的を明確にしないと使い勝手の悪いAIができてしまいます。

各チームとの意見の擦り合わせには「Machine Learning Project Canvas」フレームワークを活用し、ステークホルダー間で共通認識を持てるようにした
また、従来のフローに新しくAIに関するタスクが追加されると、はじめてAIに触れる人にとっては心理的なハードルが高く受け入れてもらえないこともあったそうです。そこで、「非常に強い選手が育成できた」というわかりやすい成果を提示することで信用を得たとのこと。このように、第三者からAIが信用されるためには簡単でわかりやすい指標を作ることが大切ということも説明されました。

強化学習AIと人間の共同作業によるQA
次に、現在行われている運用時におけるAI活用のワークフローについて説明されました。強化学習AIは、新規シナリオなどをリリースする前のQAチェックに活用されています。
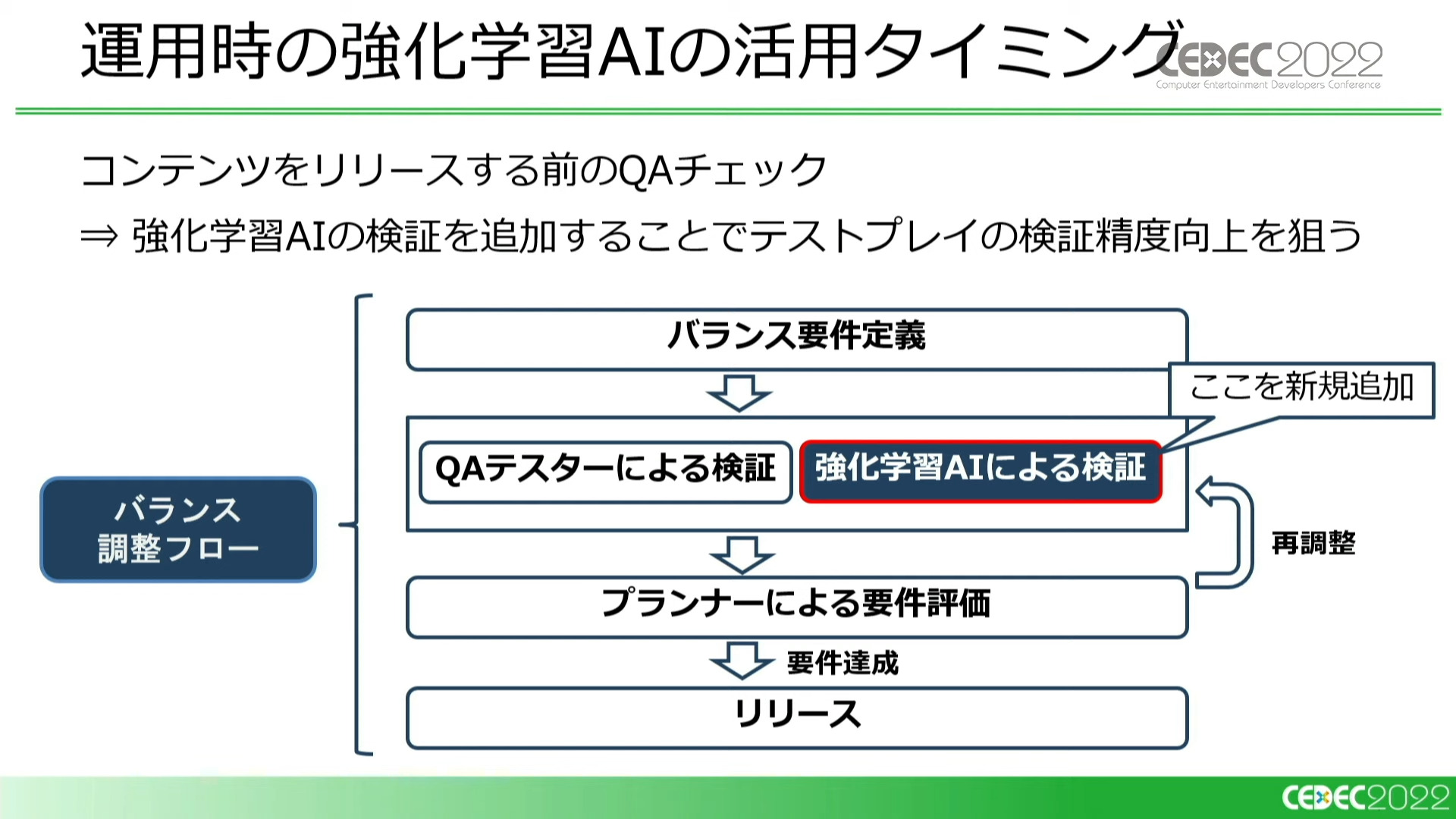
QAチェックは、QAテスターによる検証と並行して行われる
現在のAIフローの運用体制は「パワサカチーム」「QAチーム」「AIチーム」の3つのチームに分かれています。
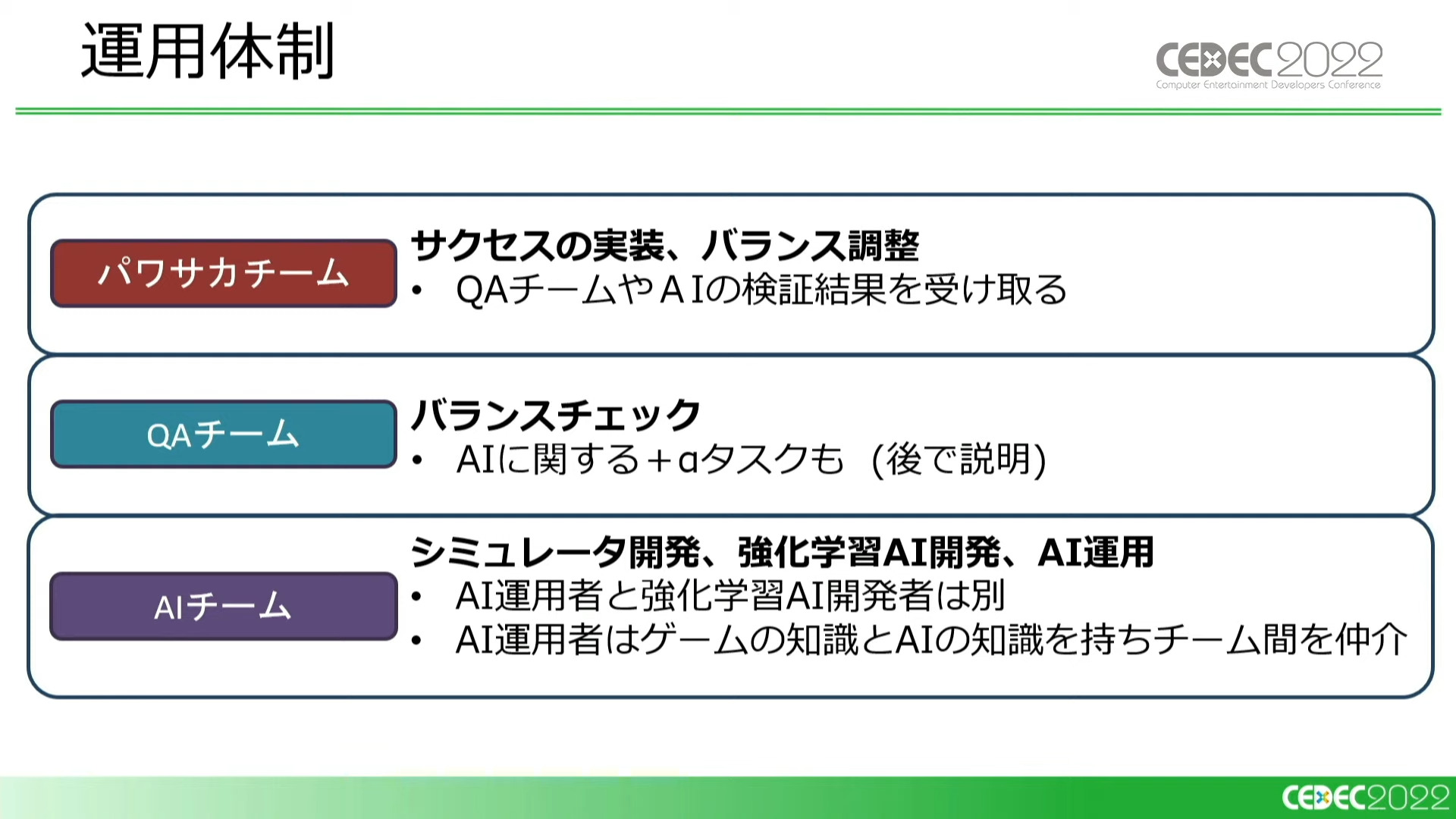
「サクセスの実装とバランス調整」をパサワカチームが、「テストプレイによるバランスチェック」をQAチームが、「シミュレータ及び強化学習AIの開発、運用」をAIチームが受け持っている。QAチームは後述する「特殊なタスク」も担当
新規シナリオ追加時において、AIチームは以下のようなスケジュールで動いています。
①新規シナリオの仕様が固まったタイミングで仕様把握を行ない、課題の洗い出しや解決策など今後の作業計画を立てる
②新規シナリオに対応するシミュレータを開発する
③シミュレータの完成次第、強化学習AIのシナリオ対応を進める
④その後、AIによる検証をQAチームのチェックと並行して行う
※チェック期間中はオリジナルの変更箇所をシミュレータに毎日反映している
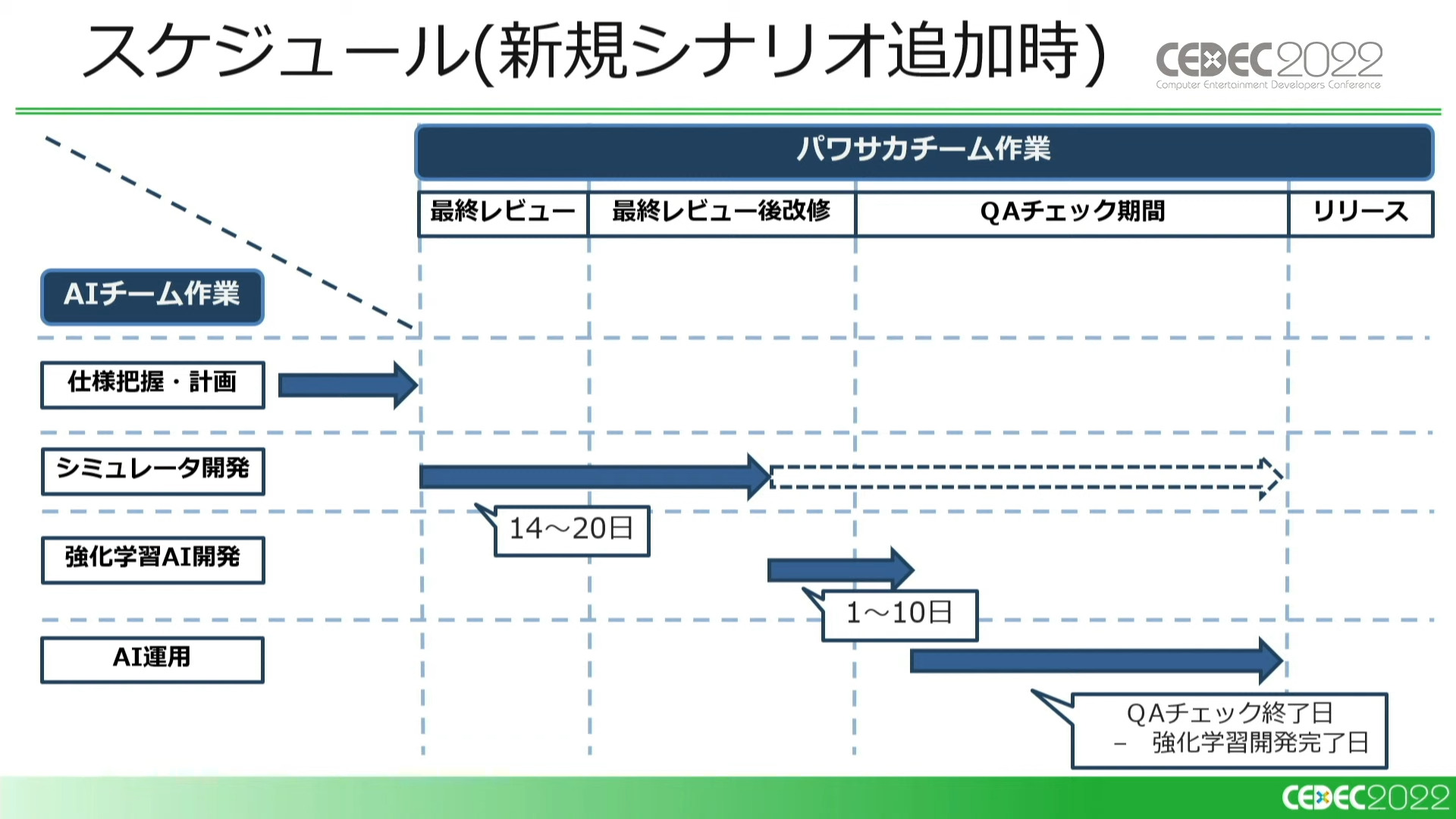
基本的にAIチームが対応する新規コンテンツはシナリオのみとなっているため、運用コストは低く抑えられています。

QAチェック期間中は上記の流れを毎日繰り返す
強化学習AIは、QAチームが検証したものと同一パターンに対してダブルチェックを行います。これにより、人間によるテストプレイの弱点である「試行回数の少なさ」と「知識による先入観」をカバーします。
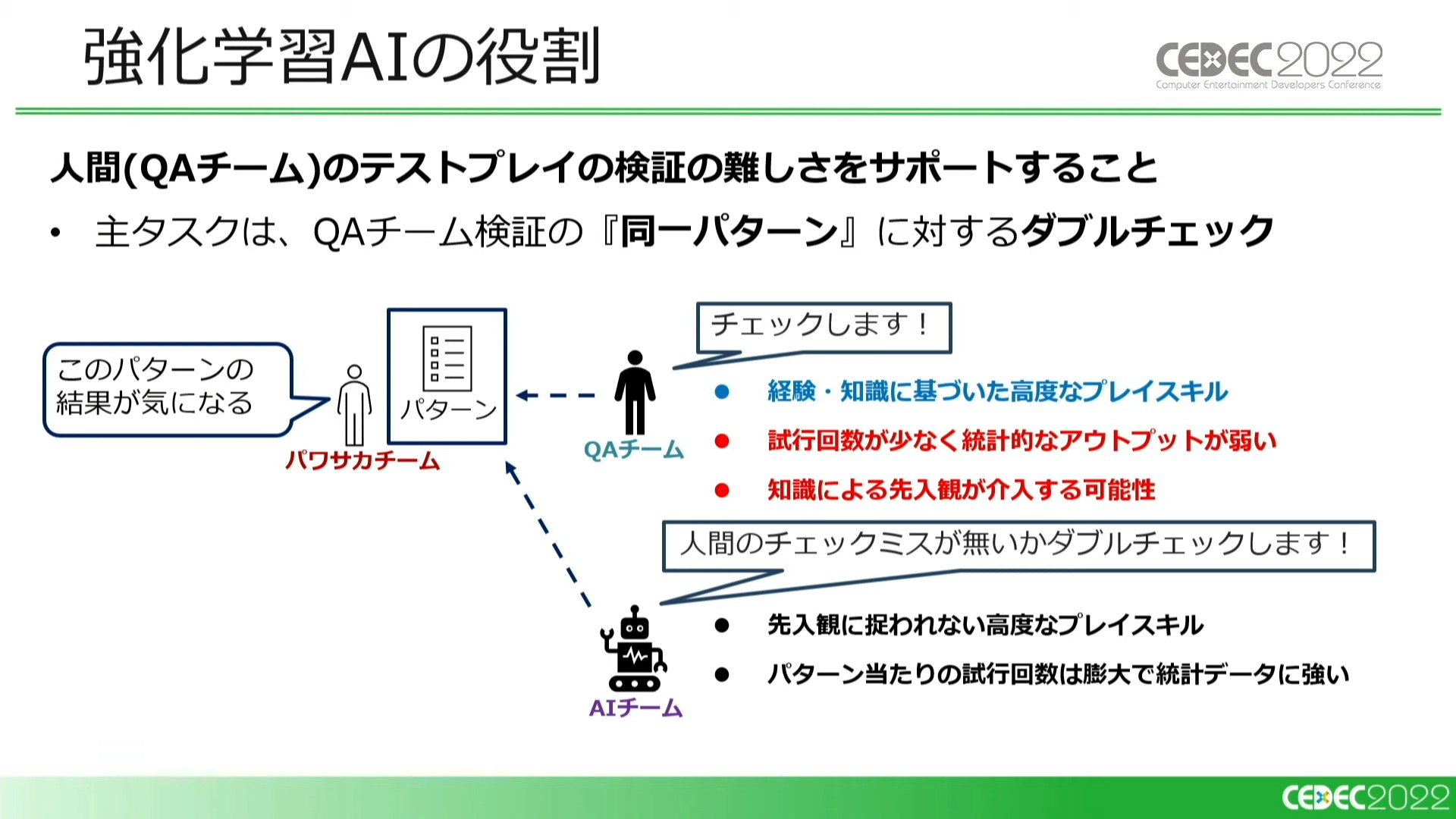
「性能が十分なAIがあれば人間のチェックは必要ないのでは?」と期待されるかもしれませんが、強化学習AIにも下記のような明確な弱点があるため、人間によるチェックは欠かせません。
- シミュレータに不具合があった場合。また、強化学習の攻略が最善ではないケース
- AIは高いスコアは出せるが、何故高いスコアが出せたかは説明してくれない
- サクセスのユニークなシナリオでは、安定した結果が得られない場合がある

AIの弱点は運用中にも問題となっていました。そこで、「QAチームにもシミュレータの挙動をチェックしてもらう」「ゲームの仕様や詳しい攻略方法を深く理解しているQAチームの目線でAIのプレイ内容を評価することで、結果の信頼性と解釈性を補う」「安定しないシナリオにおいては無理せずQAチームにテストを任せる」という、QAチームがAIを補助するようなタスクを追加することでこれを改善しました。これが、先述の「QAチームの特殊なタスク」です。

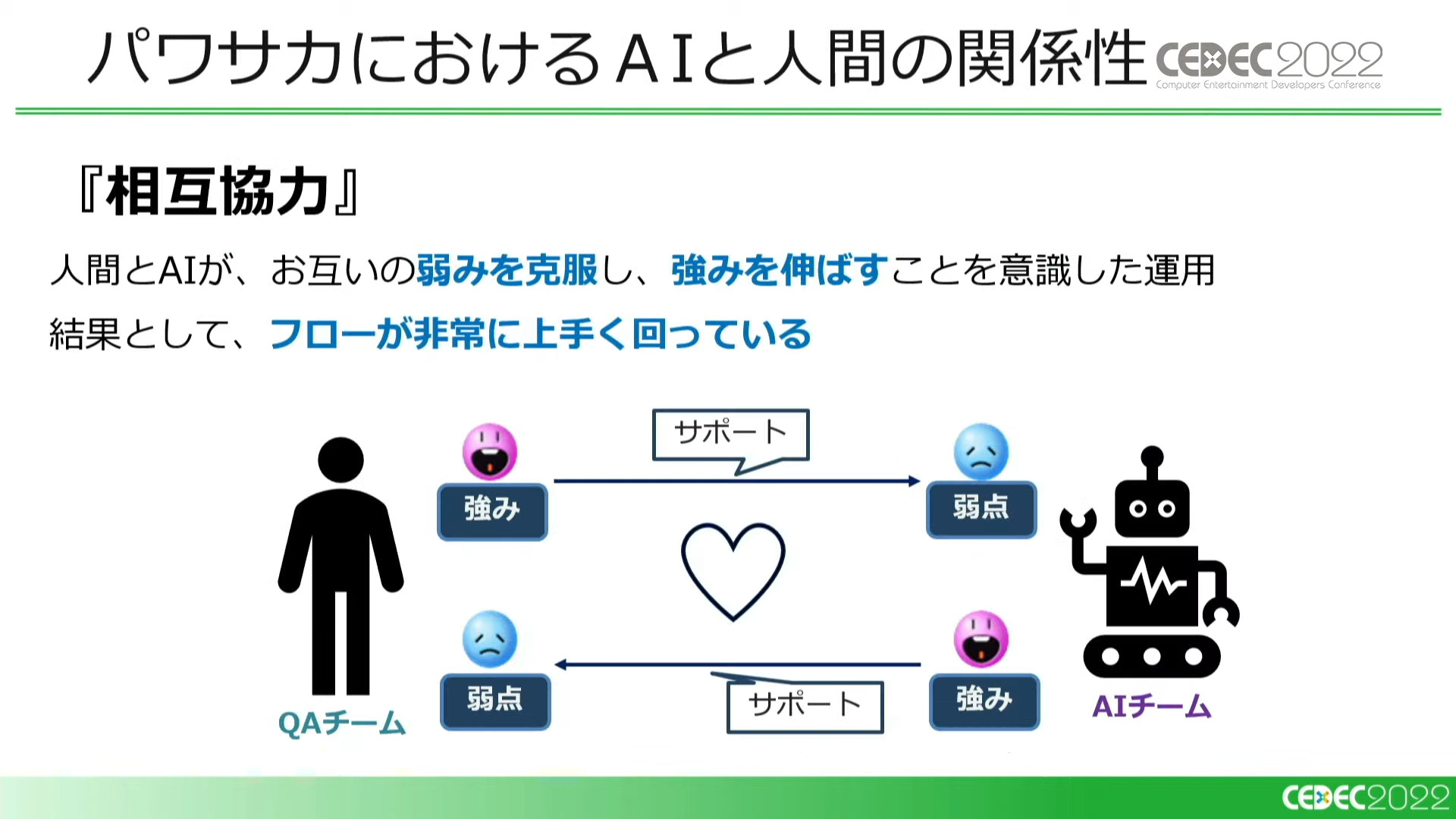
『パワサカ』におけるQAチームとAIは「相互協力」の関係にあると言えます。
互いの弱みを補いあうことが、フローがうまく回っている理由であると語られました。
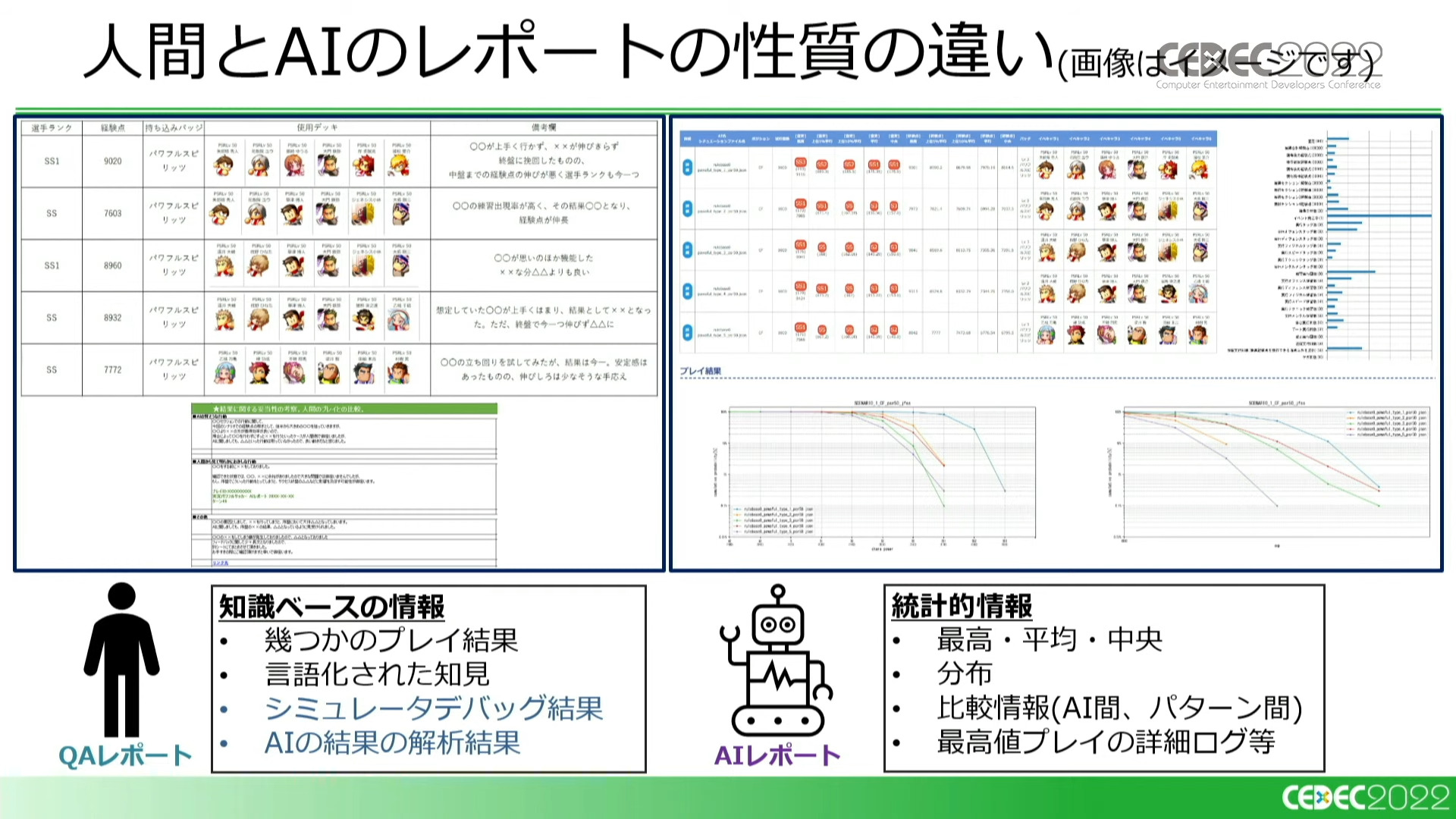
テストレポートにも違いがみられる。QAテスターの内容は知識に基づく、言語化された知見が記載されている。一方でAIが出力するのは、人間が持っている感覚を高めるような統計的なデータである
ここで、強化学習AIの実際の運用ケースが3パターン紹介されました。どのパターンも、QAチームとAIチームが相互協力しています。

『パワサカ』チームがシナリオ性能を弱体化したことで、バランスチェックが必要になったというシチュエーション。QAチームとAIチームの結果が同じような傾向を示している場合、チェックは信頼できると判断できる。QAチームの結果をAIが後押ししたような形になった

同じようなケースで、QAチームよりもAIの方がスコアが高い場合、QAチームがAIの結果の深堀りを行なったところ、AIはQAチームが見つけていないような攻略方法を使っていた。実際のユーザーがとったのはAIの攻略方法と同じであり、攻略方法の見落としによる「想定外」が防げた例

QAの方がスコアが高い場合も、QAチームが深掘りを行なう。今度はQAが考慮できていたがAIは考慮できていなかった部分があり、AIのどこを調整すべきかがわかった。AIの性能を向上できず、ミスリードにつながる結果を出力してしまう危険を回避できた例
このように、QAテスターにAIのサポートを付けることで、人間のみのバランスチェックと比較して「想定外の挙動」の減少が実現できました。

今後の課題としては、シミュレータの開発コストや、AIフローで求められるスキルが特殊であるための属人化などが挙げられています。今すぐに解決することは難しいものの、将来的に他プロジェクトへの転用を見据えて解決策を模索している状況とも説明されました。

バランス調整に対するAI活用で特に大切なこと
講演の総括として、AIのバランス調整活用で特に大切な点として以下の四つが挙げられました。
①妥協すべき点は妥協することが大切
- AIにも苦手な部分があるため、性能が出ないケースは無理にコストをかけず素直に諦める
②AIの役割を具体化して、認識のズレの余地がないようにする
- AIの性質・役割に対する認識を、AIチームと開発チームで早期に共通化することが大切
③強化学習は最初からある程度『勝算がある』題材を選んで適用する
- 相性が悪いものに強化学習を活用しようとすると、様々な観点でコストが跳ね上がる
④実運用を見据えるなら開発チームを絡めた体制を最初から構築する
- 「コストをかけたけれど結局使われない」といった事態を回避するために、開発チームに当事者意識を持ってもらうことが大切


国立情報学研究所との共同研究
同社は強化学習AIを用いてゲームをプレイするという試みで国立情報学研究所と共同研究を行っています。研究内容は「複数のAIが異なる行動をとるとき内部では何が違っているのか」というもの。研究成果は「ASE4Games 2022」で発表されるとのことです。

異なる二つのAIで結果が違うのはわかるが、何が違いを生んでいるのかを比較するために行動ログを追っていくのは大変

複数エージェント(AI)の行動比較
同じシチュエーションで異なる行動をとる場合、そのAIにおいて何の値が大きい(小さい)のかを分析

最後に、岩倉氏は「今回の講演を受けて強化学習AIの導入を検討される方は、開発するAIによって得手不得手があることを受け入れ、AIを制作チームの一員として一緒にゲーム開発していくイメージを持ってほしい」と語り、講演を締めくくりました。


コーヒーがゲームデザインと同じくらい好きです
関連記事



注目記事ランキング
1
2
3
4
5
1
2
3
4
5
1
2
3
4
5
1
2
3
4
5
1
2
3
4
5
1
2
3
4
5
1
2
3
4
5
連載・特集ピックアップ
西川善司が語る“ゲームの仕組み”の記事をまとめました。
Blenderを初めて使う人に向けたチュートリアル記事。モデル制作からUE5へのインポートまで幅広く解説。
アークライトの野澤 邦仁(のざわ くにひと)氏が、ボードゲームの企画から制作・出展方法まで解説。
ゲーム制作の定番ツールやイベント情報をまとめました。
CEDECで行われた講演のレポートをまとめました。
UNREAL FESTで行われた講演のレポートやインタビューをまとめました。
GDCで行われた講演などのレポートをまとめました。
CEDEC+KYUSHUで行われた講演のレポートやイベントレポートをまとめました。
GAME CREATORS CONFERENCEで行われた講演のレポートをまとめました。
Indie Developers Conferenceで行われた講演のレポートやインタビューをまとめました。
ゲームメーカーズ スクランブルで行われた講演のアーカイブ動画・スライドやレポートなどをまとめました。
東京ゲームショウで展示された作品のプレイレポートをまとめました。
BitSummitで展示された作品のプレイレポートをまとめました。
ゲームダンジョンで展示された作品のプレイレポートをまとめました。
日本と文化が近い中国でゲームを展開するための知見を、LeonaSoftware・グラティークの高橋 玲央奈氏が解説。
インディーゲームパブリッシャーの役割や活動内容などを直接インタビューします。




今日の用語
法線
Xで最新情報をチェック!




