「推論」、そして「AI」とは
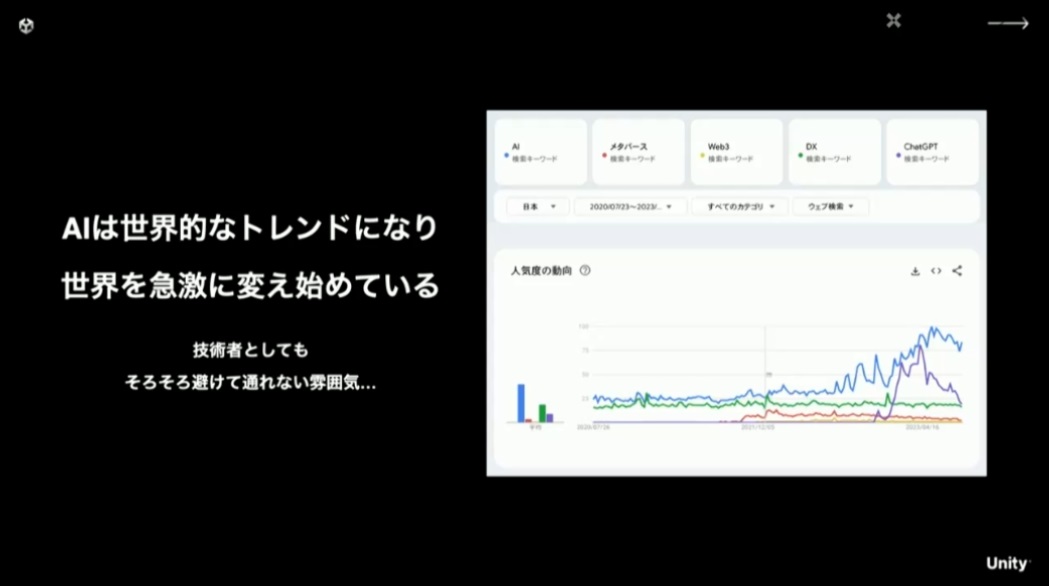
2022年までのAI技術の発展にもめざましいものがありましたが、2023年になって一気にAIへの関心が高まったというのは実感がある方も多いと思います。本講演では「推論」というワードが頻繁に使われていますが、講演内においてはAIと読み替えても問題ありません。
AIが専門外のエンジニアに対しても「AI使って良い感じにしてよ!」と言われかねないこのご時世、既に技術が積み上がっていて何から始めればいいのか分からない人も少なくありません。本講演の目的は、こうした層に対しても「AIは怖くない」と思えることを目標に行われたとのこと。
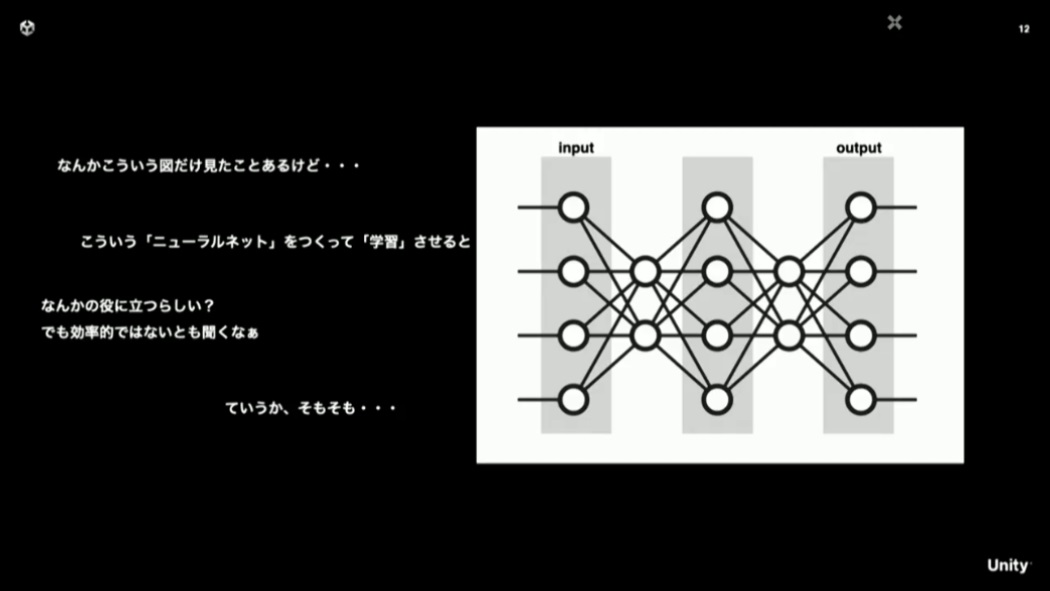
少し前まではAIというとニューラルネットのような画像が登場する解説が多く見られましたが、それで何をどう学習させると「顔を認識したり、ChatGPTのように適切な答えを返してくれるのか?」というところには大きなギャップがあります。
機械学習の基本
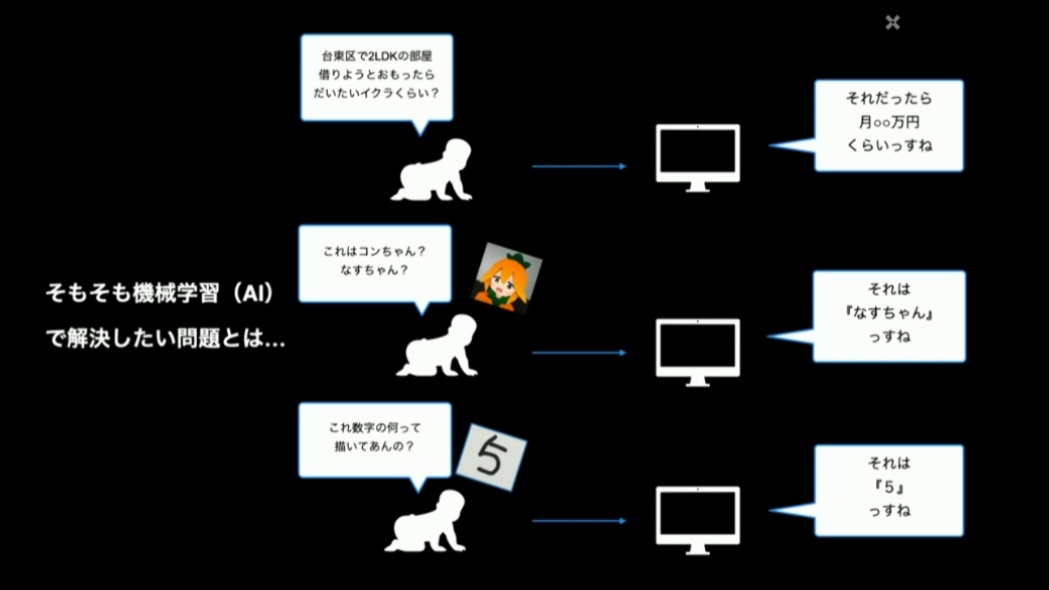
そもそも機械学習で解決したい問題は、プログラミングで普通に解こうとすると大変なものばかりです。入力に対して適切な出力を返す処理を、個々の問題ごとに作り込んで行くのは、非現実的な労力を要します。
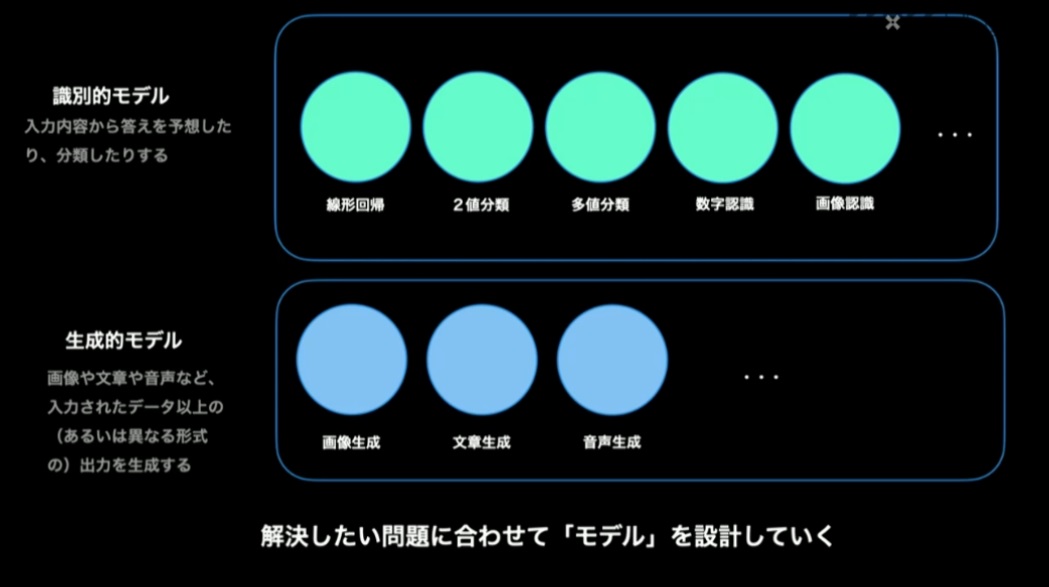
この労力を、大量のデータを学習させることで代替するのが「機械学習」です。機械学習を行うには、解決したい問題に合わせて「モデル」を設計して利用していく、というアプローチが基本となります。
機械学習のモデルはざっくり2つに分類すると「識別的モデル」と「生成的モデル」に分けられます。識別モデルは、入力された情報の予測的な分類結果を返します。生成モデルは、入力された情報以上の出力結果を生成して返します。生成モデルの有名なものとしては、Stable Diffusionのような画像生成モデルが該当します。
補足になりますが、生成的モデルを利用したシステムにおいても、入力を処理する時点で識別的モデルは利用されています。つまりAIを利用したシステムとは、処理の各段階ごとで解くべき問題に対する適切なモデルを選択し、それらの入出力を繋げることで、最終的に得たい出力が得られるように作られている、と理解するのが良いでしょう。
機械学習モデルの作り方
続いて、機械学習のモデルの中でどのようなことをしているのかに踏み込んで具体的な解説が行われました。ここでは比較的シンプルな事例として、勾配降下法と呼ばれる手法を使って、識別モデルの一種である2値分類を行うモデルを作ることを考えてみます。
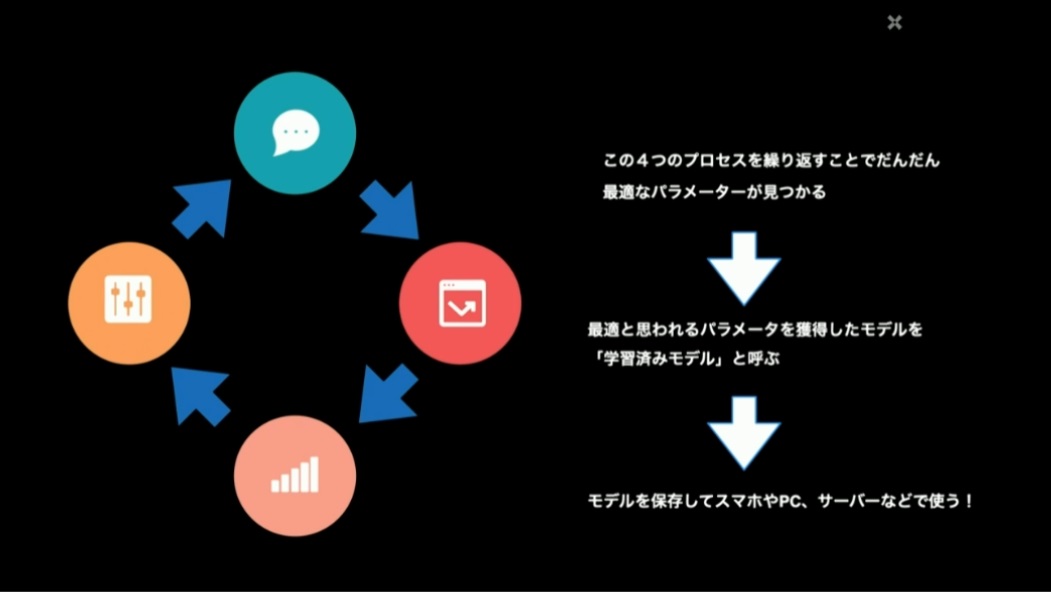
勾配降下法を用いた識別モデルのプログラムでは、入力となる学習データと正解データを基にして、予測計算・損失計算・勾配計算・最適化の4要素からなる計算処理を行います(この4要素については後述します)。
この計算の繰り返しにより、予測結果と正解データの勾配(≒差分)が小さくなっていくことで、予測計算の精度を上げることが「学習」であると言えます。
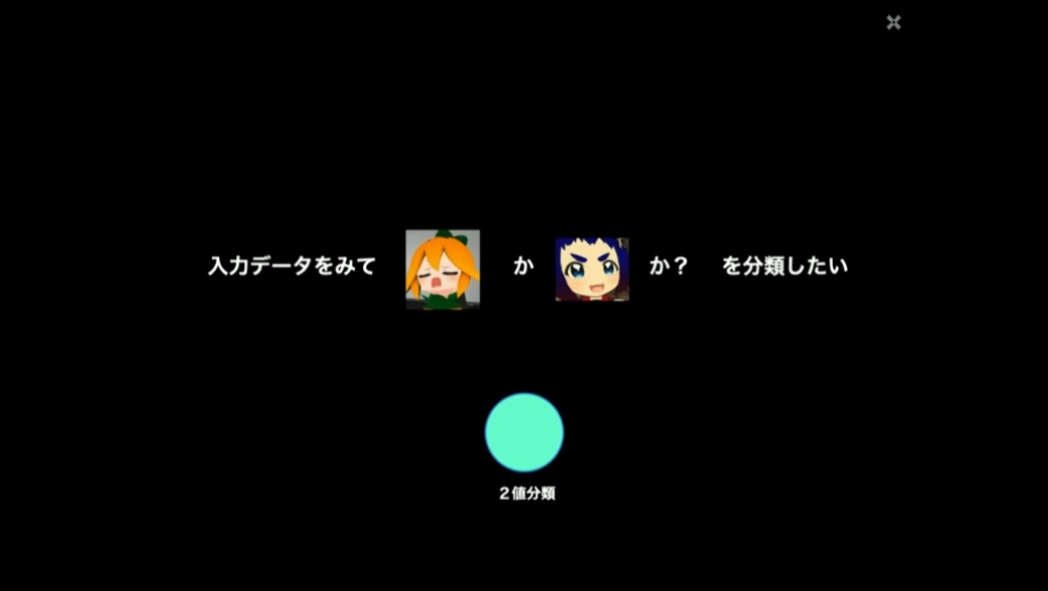
勾配加工法について、あるデータをAかBかどちらかに分類する二値分類を例に見ていきましょう。
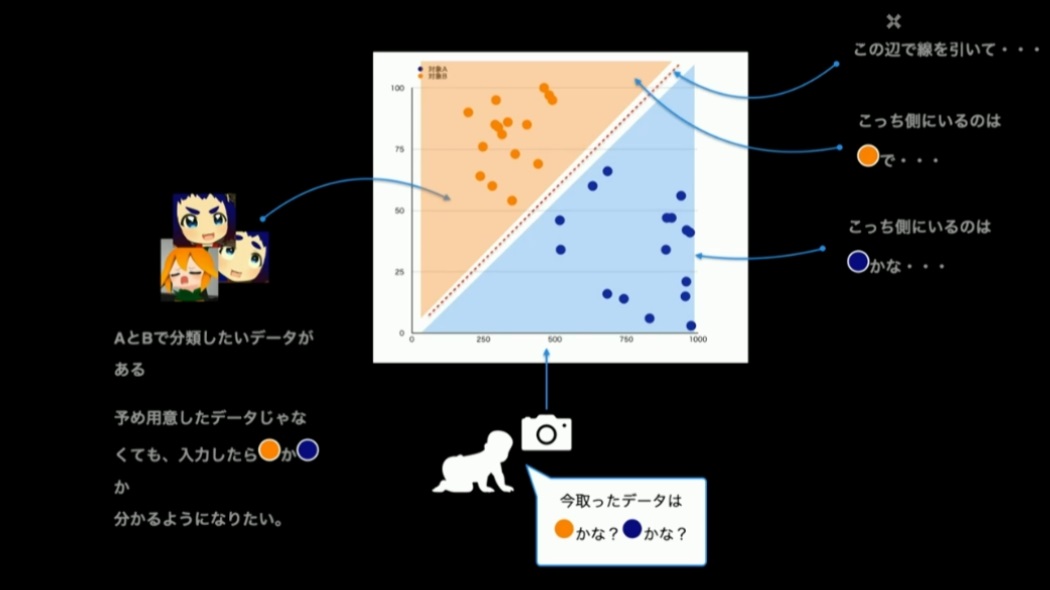
まず、ここでの入力データは「Aに分類して欲しいデータ」「Bに分類して欲しいデータ」になります。下記画像では例示としてキャラクターの画像を使っていますが、実際にモデルを構築するにあたっては、入力データをベクトルに変換して利用します。
データがこのように2次元座標にプロットできるのであれば、AとBはそれぞれに集合を形成するはずです。ならば、この平面上に集合の境界となる線を引ければ、正解が分からないデータでも、線で隔てされた領域のどちらにプロットされるのか、で二値分類ができるという寸法です。
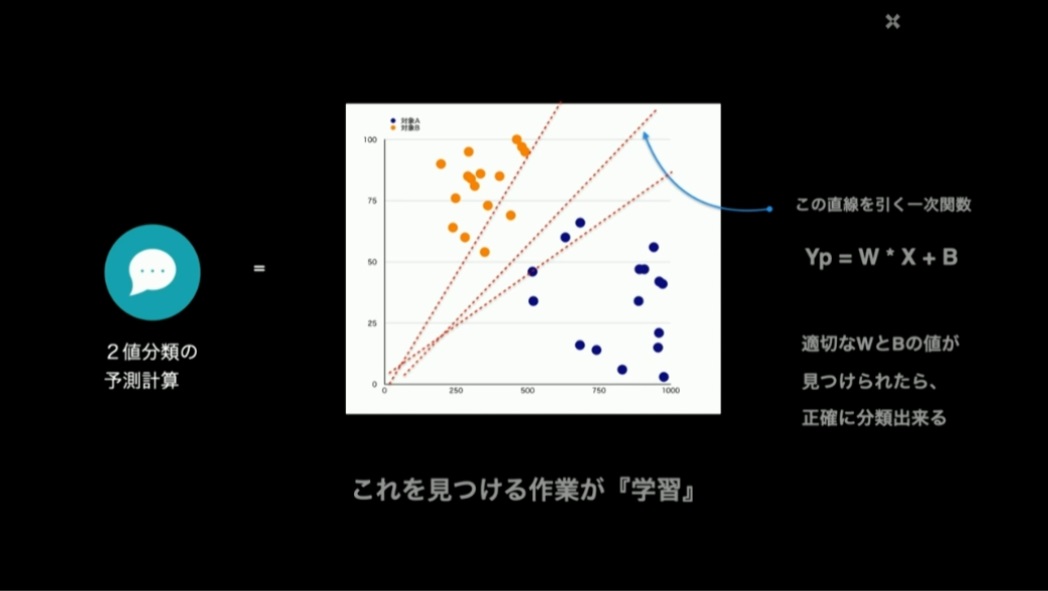
この分類するための線を表す一次関数に登場するパラメータ(傾きと切片)を見つけるために、反復計算によって適切な値を見つけていきます。この作業が「学習」です。予測計算と言われると複雑で難しいことをするような印象を受けますが、一次関数のパラメータをいじくるだけの作業、と言われると、そんなに難しく無さそうな気がしてきます。
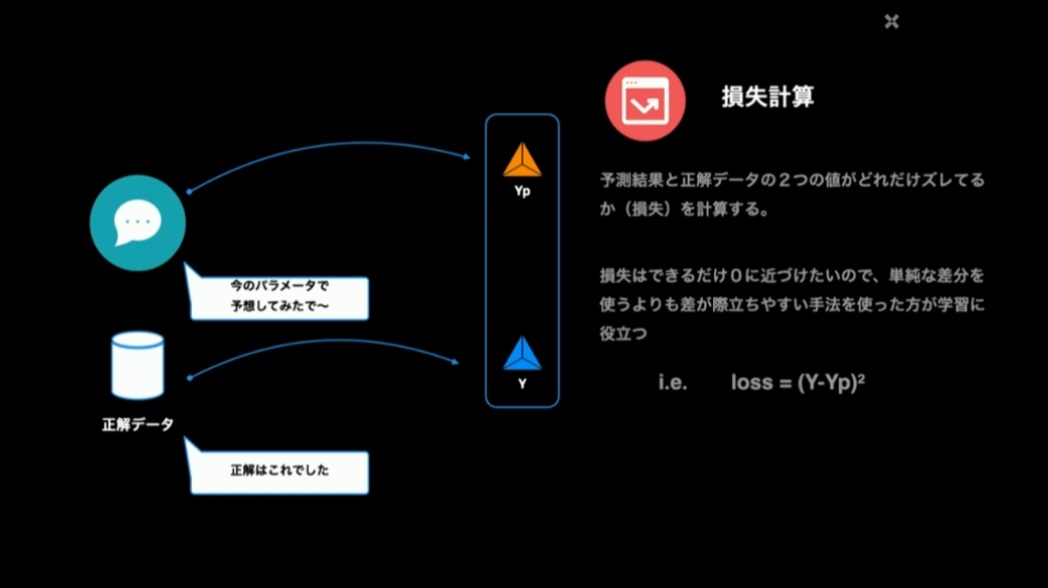
では、勾配降下法による学習の流れを追っていきましょう。学習開始時点では、分類をするための関数(予測関数)の傾きと切片にはランダムな初期値が入っています。その状態で予測計算を行う、すなわち予測関数に入力データを投入して予測結果を求めます。この予測結果と正解データを比較し、両者のズレを「損失」として求めます。これを損失計算といいます。なお、この差分値はそのまま使わずに、差が際立つように数値として大きくなるような工夫(ここでは2乗)をしています。
予測関数に入力データを入れて予測結果であるYpを求めるのが予測計算。その結果Ypと正解データYとのズレ(損失)を求めるのが損失計算
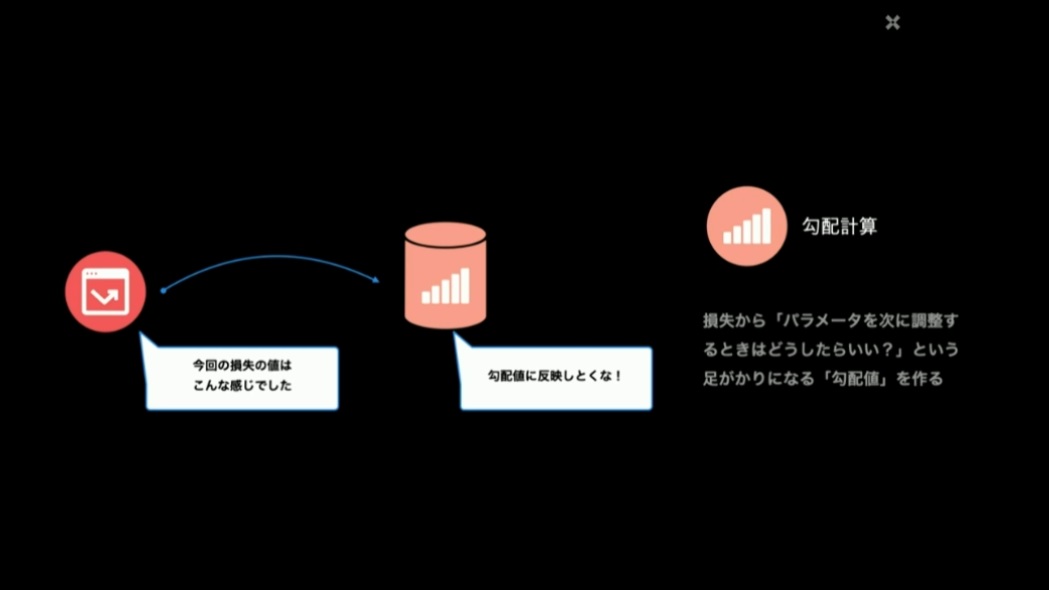
こうやって損失の値が求まったら、次の計算においてパラメータを調整する際に、どちらの方向に調整すればいいのか、を示す値として「勾配値」を求めます。これが勾配計算です。
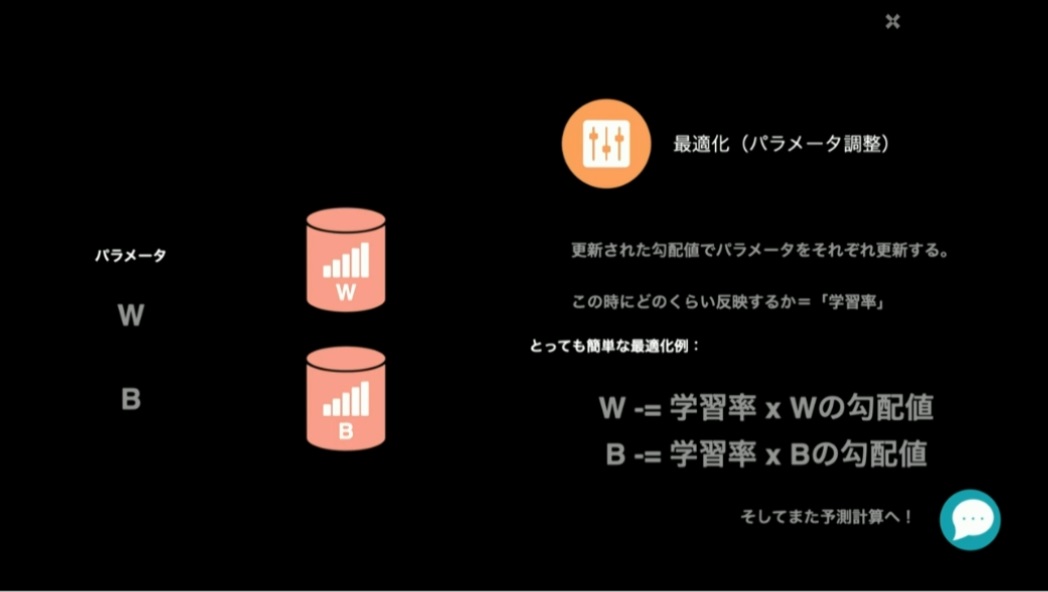
勾配を求めたら、その値を使って最適化、つまりパラメータを調整しますが、毎回勾配値をそのまま適用してしまうと、いつまで繰り返しても損失が0に収束しない場合もあります。そのため、学習率という極小さな係数を掛けて、1ループの計算で求めた勾配値を真に受けすぎないようにします。
このプロセスを繰り返して最適なパラメータが見つかったら「学習済みモデル」のできあがりです。学習済みモデルであれば、調整されたパラメータとそれを利用する計算処理さえ移植すれば、スマートフォンやPC、本番用のサーバーなどで利用できる物量になります。
このループを何周すれば学習済みと言えるのか、についではケースバイケースとなるので、モデル設計者の試行錯誤の結果によりそうです。
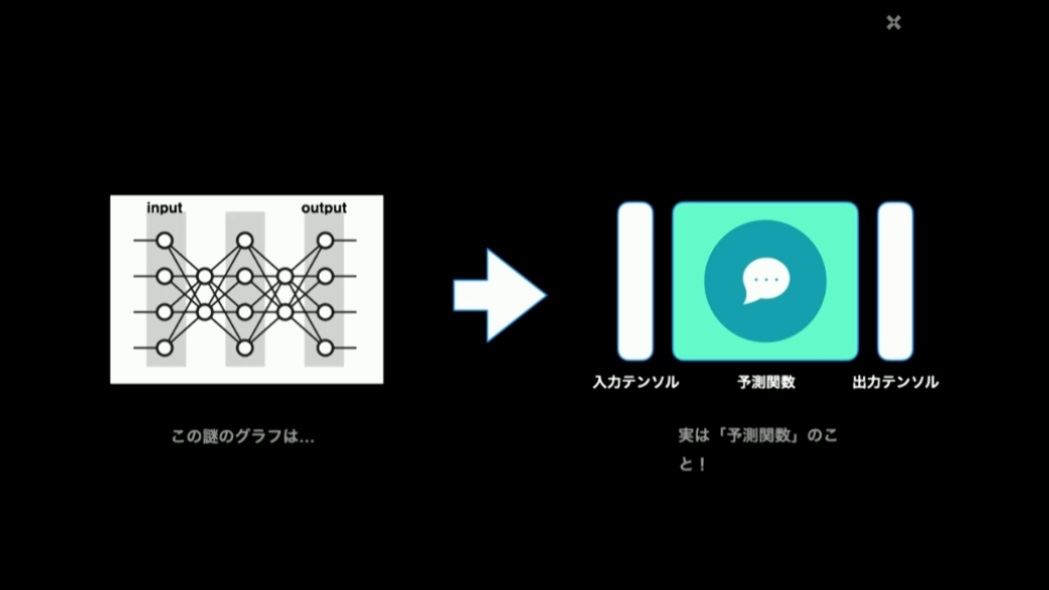
こうして「予測関数」が得られる過程を理解すると、先ほど出てきたニューラルネットの図は、予測関数がいくつか繋がっている状態を表しているに過ぎない、と言えます。複雑度の違いはあっても、何かしらの数値を入力として、いくつかの関数を経て、数値の入力を得ている、ということには変わりありません。
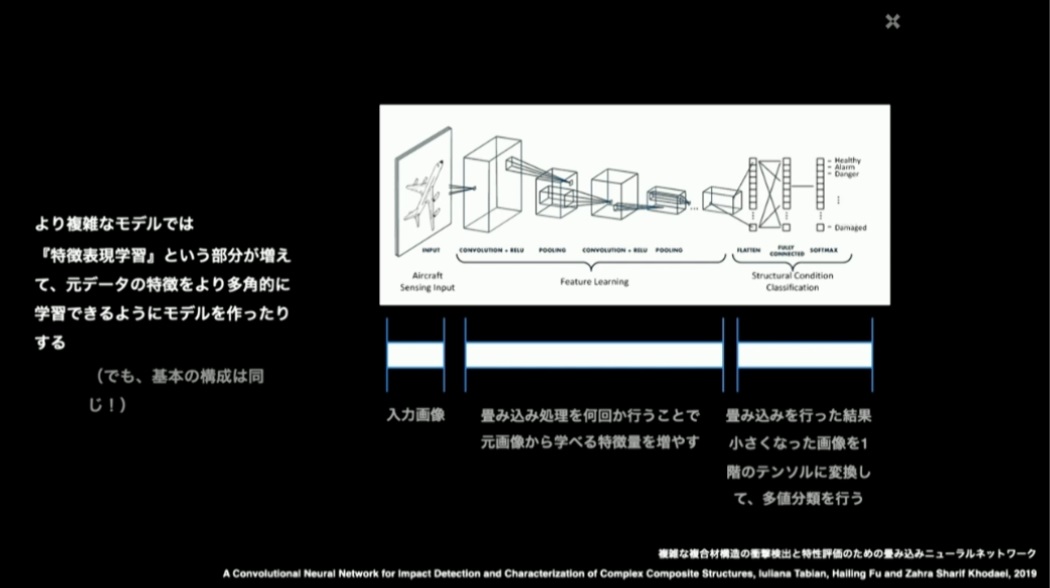
より複雑なモデルでは「特徴表現学習」という部分が増えて、元データの特徴をより多角的に学習できるようにモデルを作ったりするアプローチが採られます。しかし、基本的な構成は同じで、処理の段階ごとにモデルが入れ子になっていたり、複雑化しているだけと認識することができます。
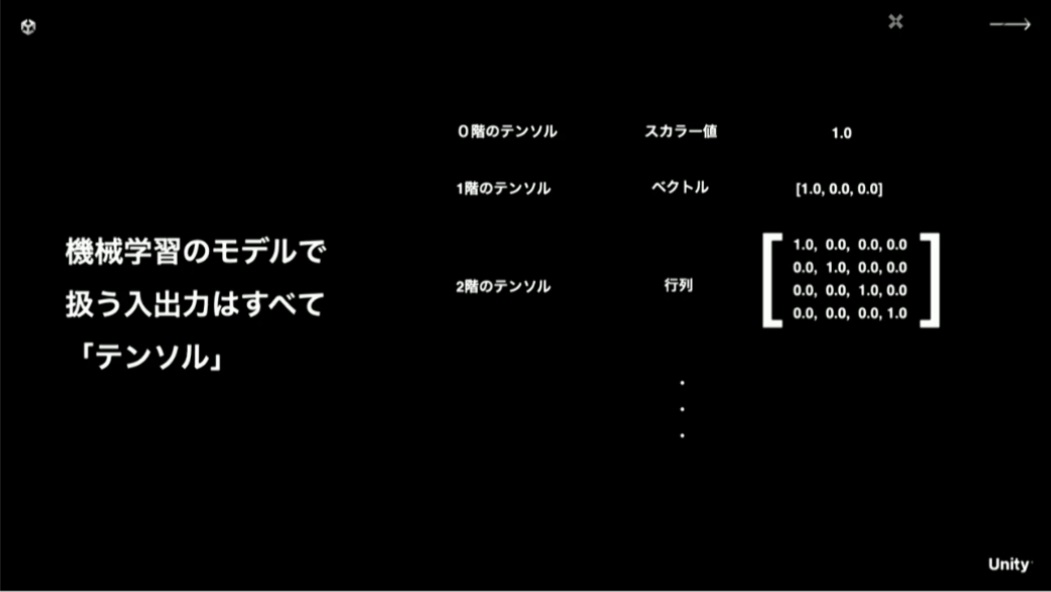
機械学習のモデルで扱う入出力はすべてテンソルと呼ばれます。これも難しさを誘発する要因となっていますが、実体としては難しいものではなく、スカラー値・ベクトル・行列……といったように、複数の軸を持つ数値の集合のことを指しているに過ぎません。テンソルでは階という用語が用いられますが、0階のテンソルはスカラー値、1階のテンソルはベクトル、2階のテンソルは行列のことを表し、3階から先はさらに軸が増えた数値の集合を表します。これらの要素の基本的な演算処理は、大抵の機械学習ライブラリで実装済みなので、モデルを作る際にわざわざ実装する必要はなく、簡単に扱えます。
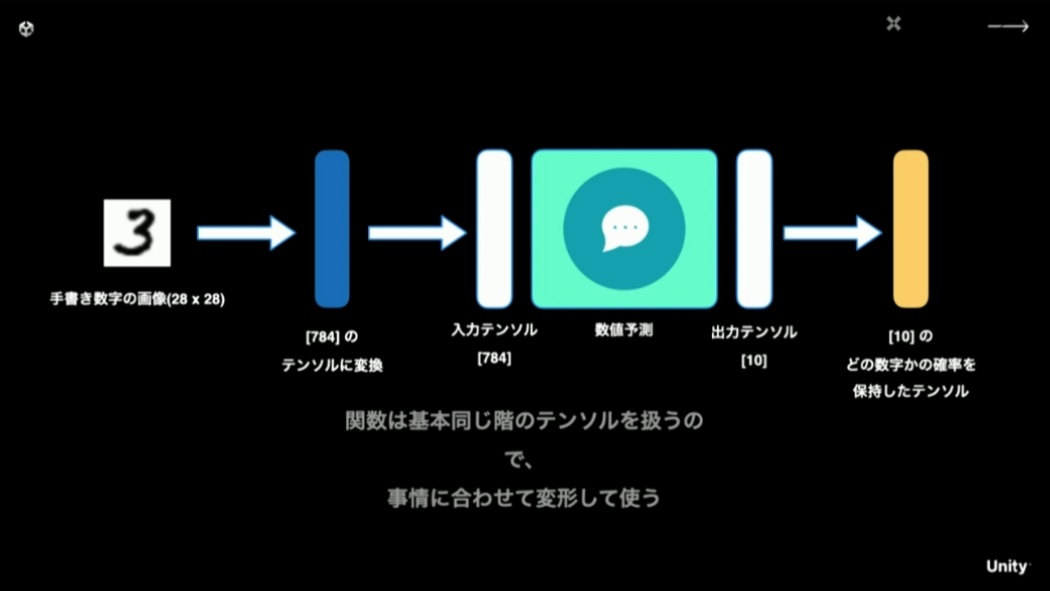
機械学習における予測関数は、入力と出力で同じ階のテンソルを扱います。画像認識を行いたい場合は入力はX,Y軸からなる画像データになりますが、認識結果をベクトル(1階のテンソル)で得る予測関数を扱うならば、入力データもベクトルに変形して扱うようにします。このプロセスはフレームワークによって、シェイプと呼んだりトランスフォームと呼んだりします。
28ピクセル×28ピクセルの手書き数字の画像を入力して0-9のうちどの数字かを出力させる際、出力テンソルが[10]という1階のテンソルなので、それにあわせて入力テンソルも[784]という1階のテンソルに変形する(28×28=784)
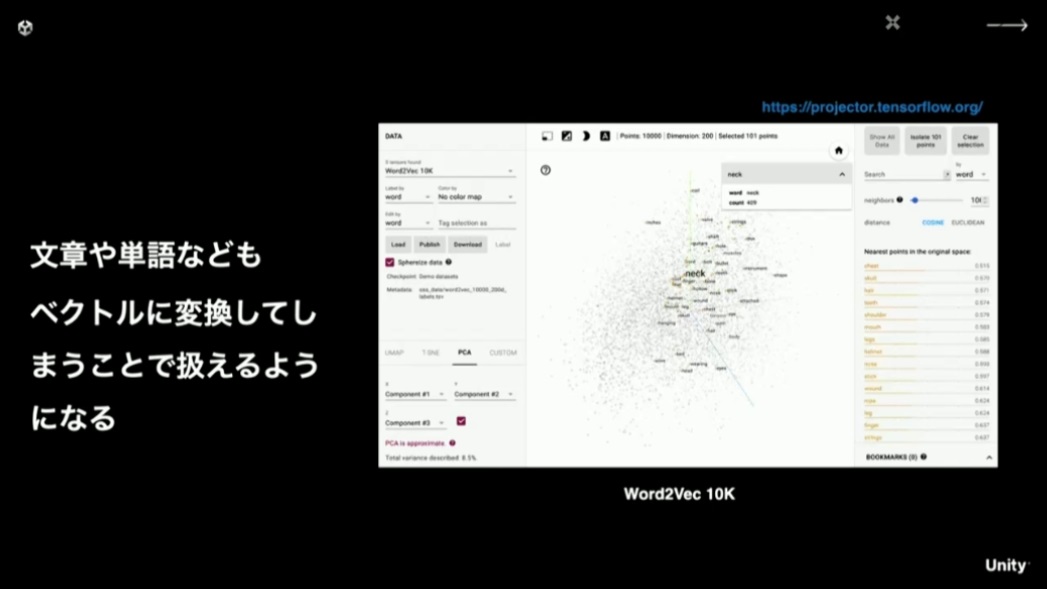
どんな入力であってもベクトルに変換してしまえば機械学習で扱えるため、様々なベクトル化の手法が考案されています。特に文章や単語をベクトル化するもので有名なのがWord2Vecです。文章や単語の相関関係を座標上にマッピングすることで、ChatGPTのように質問に近い関係性の回答を出力できるようになります。
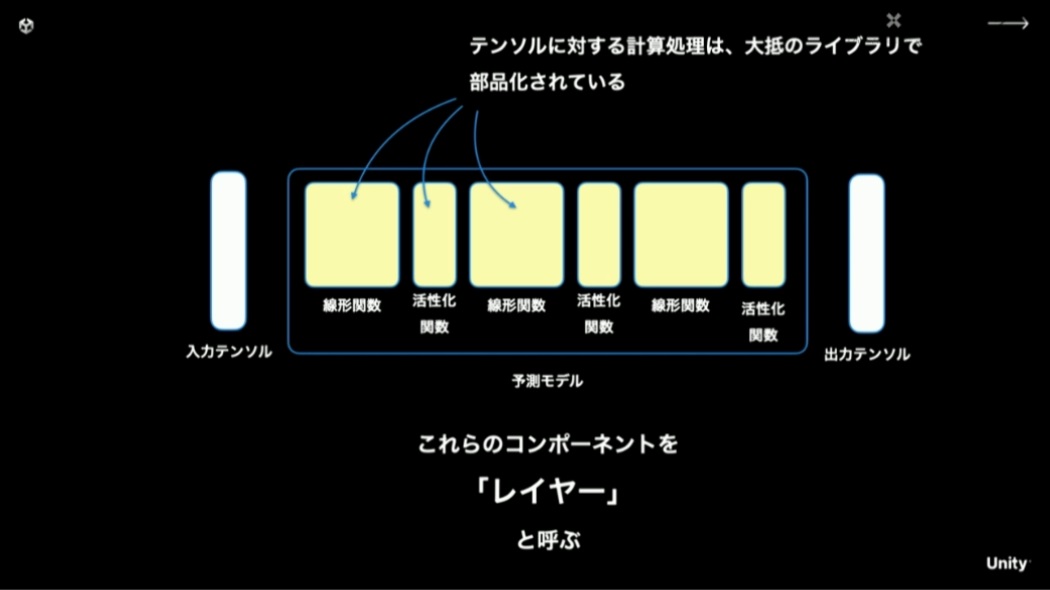
大抵の機械学習ライブラリにおいて、テンソルに対する計算処理は「線形関数」「活性化関数」といった単位で部品化されています。これらの部品を「レイヤー」と呼びます。このレイヤー化されているということが重要で、このおかげで予測関数を「推論ライブラリ」として、ゲームの実行環境に持ち出すことがやりやすくなっています。
※活性化関数:あるレイヤの計算結果に対して、特徴的な結果を増幅する処理を行う関数のこと。「0より大きな数値に対して線形的に増加する値を返す」といったシンプルな実装で表現でき、繰り返し学習を重ねた際の傾向を際立たせることができる
機械学習モデルの持ち出し方
機械学習のモデル構築にはPyTorchやTensorFlowといったライブラリを用いることが多いですが、当然作られたモデルはこういった実行環境に依存したものになります。そのままではスマートフォンやゲーム機上で動かすことは困難です。
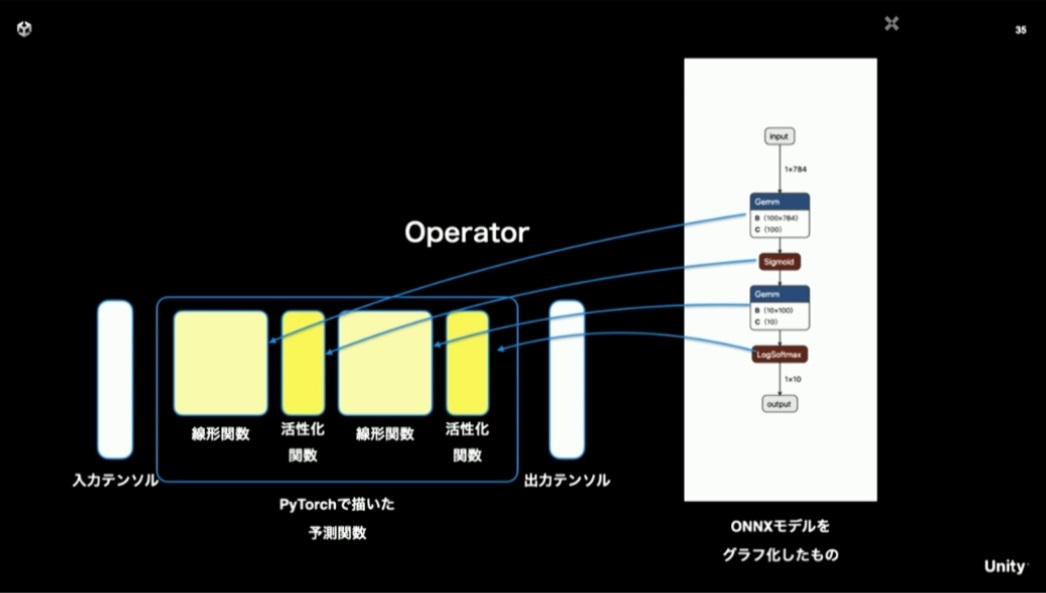
そこで「ONNX」と呼ばれるフォーマットが登場しました。これは推論モデルを表現する共通フォーマットで、多くの機械学習ライブラリがサポートしています。これを使えば、モデルの構造やパラメータなどを効率的に持ち運ぶことができます。
モデルの設計と学習は好きな環境で行い、「ONNX」形式で出力すれば、後は実機上での実行環境を整えるだけです。
「ONNX」では前述したレイヤーに対応するオペレーターが数多く定義されています。
そして、「ONNX」形式のデータは、機械学習ライブラリ上で部品化されているレイヤーの構造が、オペレーターに対応する形で出力されます。つまり、定義されているオペレーターの実処理が実行環境上で実装できれば、学習済みのパラメータとモデルによる推論が再現できる、ということになります。
Unity上で推論ライブラリを実装する
Unityには「Sentis」という名前で、「ONNX」形式のモデルをUnityがサポートしているプラットフォームで実行するためのライブラリがあります。
「Sentis」は以前は「Barracuda」という名前であった。まだ実験的機能なので、今後大きく内容や方針が変化する可能性がある点にはご注意ください(大前氏)とのこと
「Sentis」では「ONNX」のオペレーターを数多く実装することで、「ONNX」モデルをUnity上で実行できるようにしています。Unityで「ONNX」を利用する上では、「ONNX」のオペレーターの実装が、推論ライブラリの実装とほぼ同義といえます。
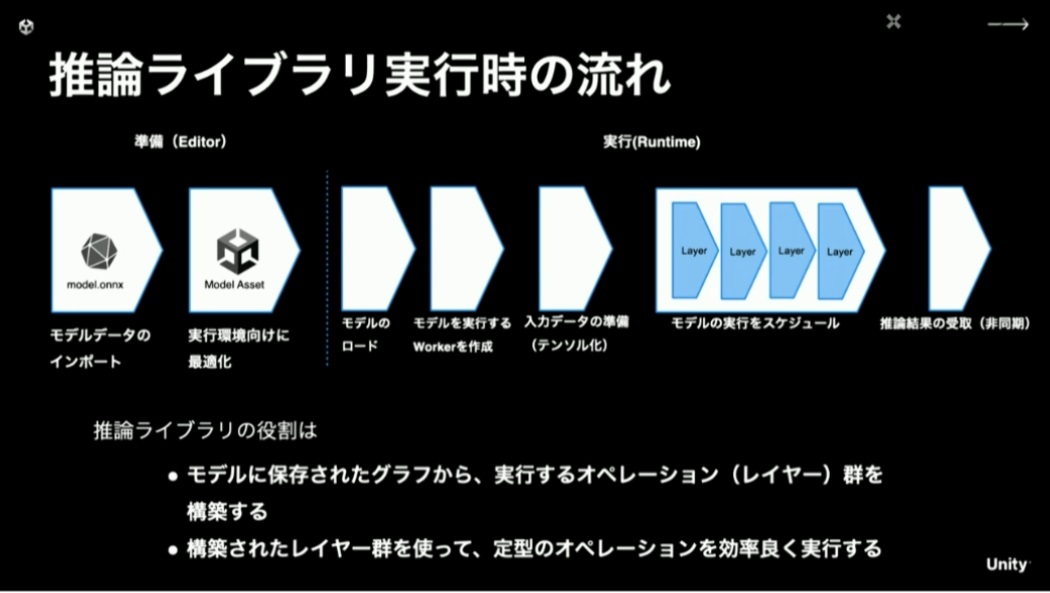
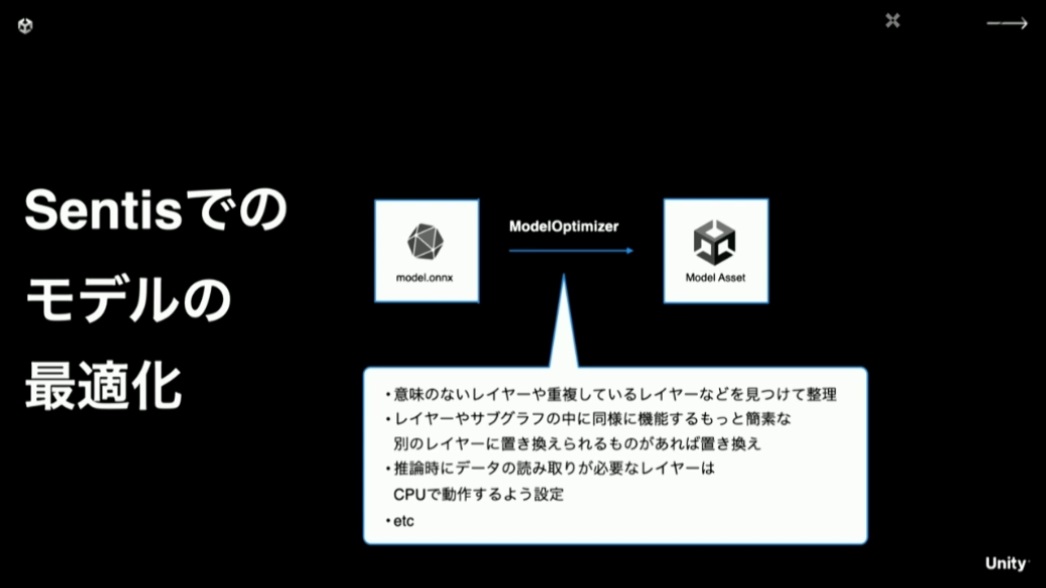
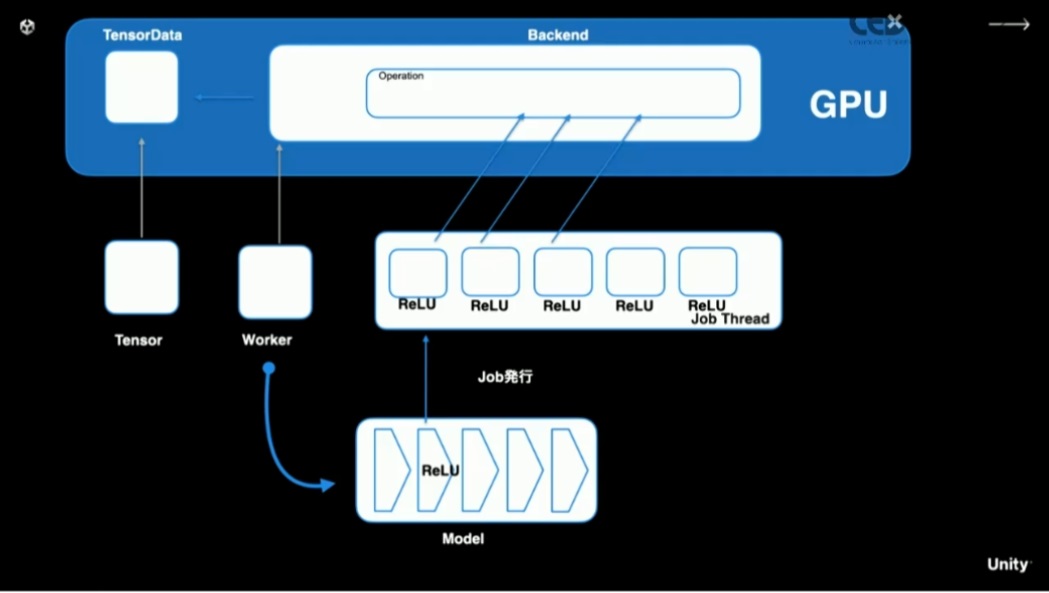
実際に実行するにあたって推論ライブラリが行うことは、データのインポート時に最適化を行いつつ、実行するレイヤー群を構築して効率の良い実行を行う、ということになります。
最適化にあたっては、無駄なレイヤーを省いたり、効率の良いレイヤーに置き換えたりといったことまで行います。また、基本的にはGPU上での実行を狙いますが、データの読み取りが必要なレイヤーがある場合はCPUで動かすように振り分けます。
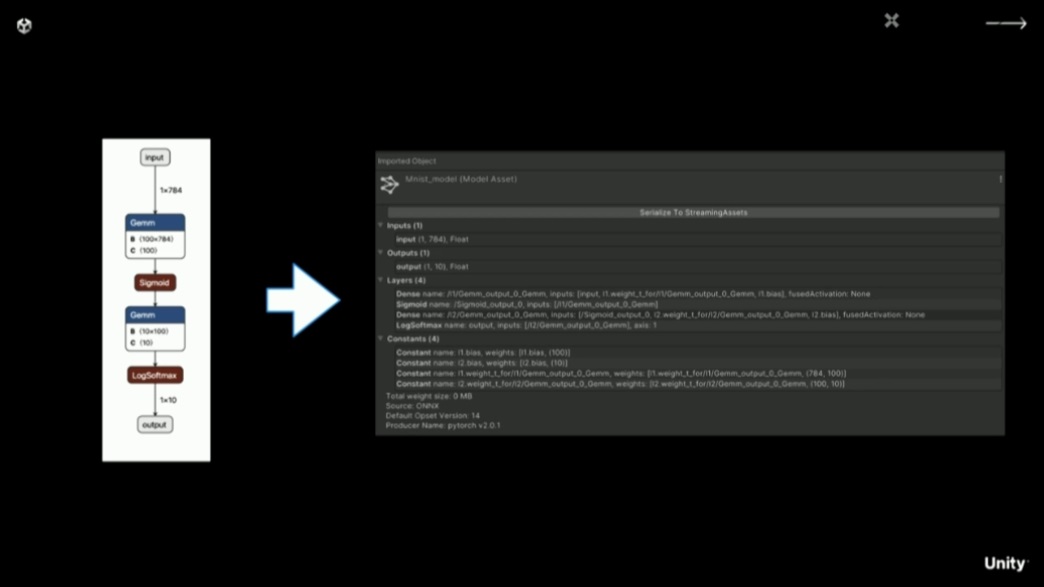
「Sentis」にて「ONNX」モデルをインポートしている様子
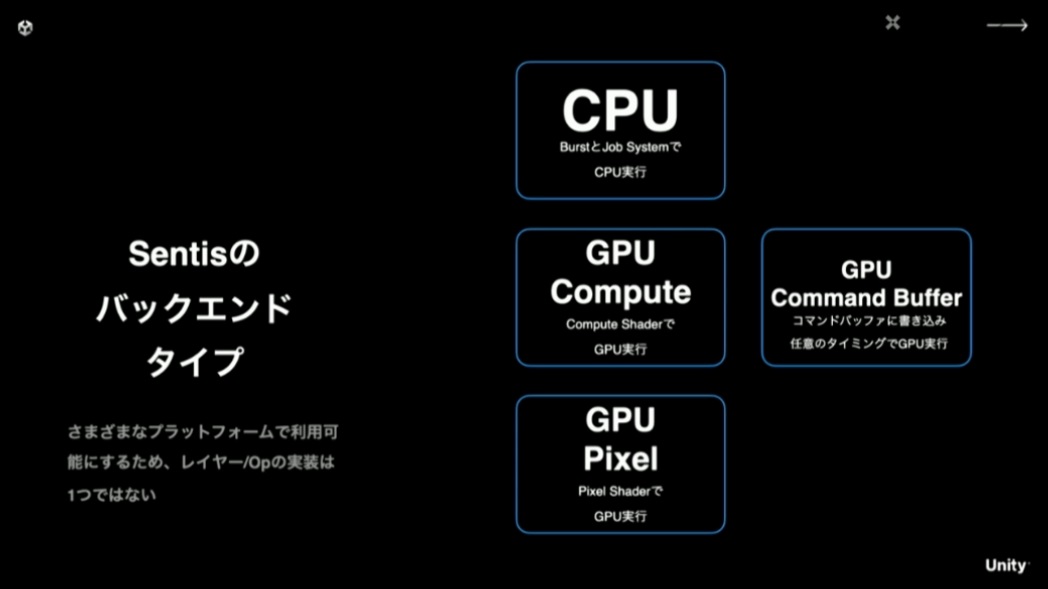
また、様々なプラットフォームで最大限効率良く実行するために、オペレーター(レイヤー)の実装を複数持っています。CPU上では、BurstとJob Systemを利用して、最大限CPUのパフォーマンスを活かすことを狙った実装になっています。GPU上においては、コンピュートシェーダーが利用できない環境向けに、ピクセルシェーダーによる実装もあります。
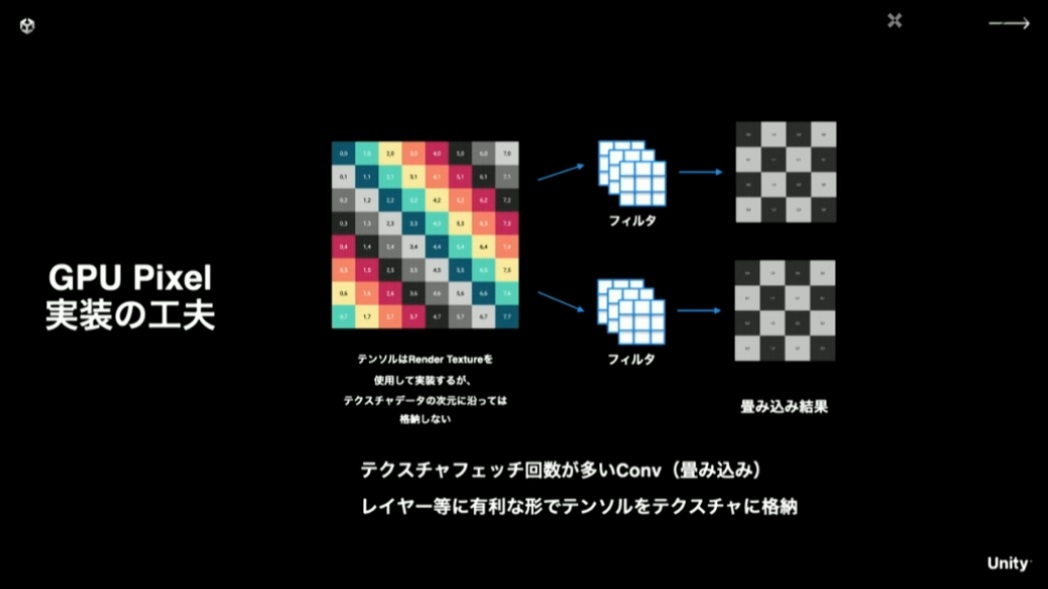
ピクセルシェーダー上での実装は、テクスチャフェッチ回数が多くなってパフォーマンスを下げないように、速度的に有利になるようテンソルの値を並べ替えてテクスチャに格納するといった工夫をしています。
モデル実行時は、レイヤー群に対応するJobを発行します。このJobは関数自体の処理はそう重くはないのですが、入力されるデータの量が膨大になったりします。これをできるだけ並列で捌くために、CPU上でのBurstによる実装や、GPU上でのシェーダーによる実装に振り分けられます。
最後に具体的なオペレーターの実装例として、活性化関数のコードを紹介し、講演は終了となりました。Unityとしての招待セッションではありましたが、機械学習の入り口に立つために必要な知識や考え方が、非常に分かりやすくまとまっていると感じられました。これをきっかけに、推論モデルの構築にチャレンジしてみるのも面白いのではないでしょうか。
推論ライブラリを実装する | CEDEC2023
ゲームエンジンプログラマ。シリコンスタジオ、ゲームフリークを経て、現在はフリーランス的に活動中。低レイヤ・描画などのランタイムから、ツール・アセットパイプラインまで、ゲームに関する技術はなんでも守備範囲です。RPG・音ゲー・格ゲー・紳士ゲー・お馬さんなどなど幅広く嗜みます。新作を待ちわびているのは『世界樹の迷宮』『ブレイズアンドブレイド』『バーチャロン』など。