
3年振りのリアル開催となった福岡で例年行われるゲーム開発者向けのカンファレンス「CEDEC+KYUSHU 2022」が、2022年11月12日(土)に開催されました。スクウェア・エニックス AI部のAIリサーチャー 森 友亮氏が登壇し、『意味が分からないからこそ、リアル ~「架空言語」音声合成による、没入感の高いボイス付きコンテンツの実現~』と題した講演が行われました。見慣れた母国語のテキストから聞いたことのない架空言語の音声を生成する手法について語られた本講演をレポートします。

スクウェア・エニックスによる、リアルな「架空言語」音声の作り方。Text-to-speechの機械学習モデルで生成した没入感の高いボイスコンテンツ【CEDEC+KYUSHU 2022】




TEXT / じく
EDIT / 酒井 理恵
目次

登壇したのはスクウェア・エニックスAI部のAIリサーチャー 森友亮氏。東京大学 大学院情報理工学系研究科にて博士課程を修了し、現在はエンタテインメントAIに自然言語処理の技術を応用するための研究開発に従事しています。
合成音声の違和感から着想された「架空言語」
テキストからリアルな合成音声を生成するText-to-speech(以下、TTS)の技術は日々改良が進んでいますが、それでも実際に聞くとわずかな違和感を覚えます。
その合成音声の違和感の一因が「普段から聞きなれている母国語であること」ではないか? というところに、この取り組みは着想を得ているといいます。例えば、日本語の合成音声に違和感を覚えやすいのは、日本語を母国語にしているからなのでは、と考えたのです。
そこで、合成音声を生成するのに母国語を使わないことで、「違和感のない架空言語」を産み出そうとアプローチしました。

機械学習を用いたText-to-speechとは?
従来のTTSの扱いには、テキストの処理・音声信号の処理など複合的な専門性が必要とされていました。しかし、専門知識が必要な部分を機械学習で置き換える手法の研究が進み、TTSはより活用しやすくなったといいます。
機械学習において「学習」はデータからルールを学ぶことで、喩えるなら例題を通して学ぶようなものです。「推論」は学んだルールを使用することで、実力テストのようなものだといえます。今回の架空言語音声の合成にあたっては、TTSの「推論」に関する工夫が行われています。

TTSの「推論」を工夫し架空言語音声合成ができるまで
一般的なTTSは以下の3つのステップを経て行っています。
①入力したテキストをテキスト特徴量(※1)に変換
②テキスト特徴量を音声特徴量(※2)に変換
③音声特徴量から音声を合成
※1:テキストを「トークン」に変換し、それをさらに変換したベクトル。
※2:音声の内容を表現するベクトル。
これを日本語から日本語合成音声を生成するパイプラインで表すと以下のようになります。
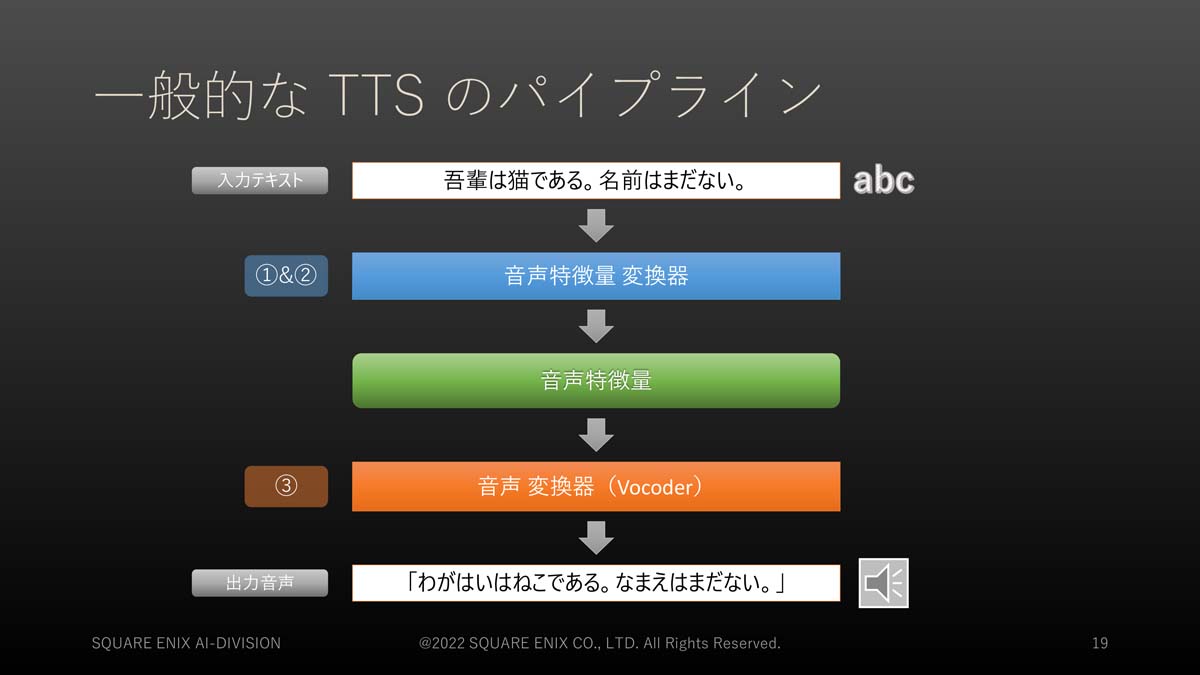
①&②の過程で「テキスト→テキスト特徴量→音声特徴量」と変換され、③で音声特徴量から音声変換器によって音声が合成される
文字列から「架空言語」の音声を生成する手法は次のような流れが考えられます。先ほどの①&②の音声特徴量変換、それによって得られる音声特徴量が、架空の言語のものになればいいのです。
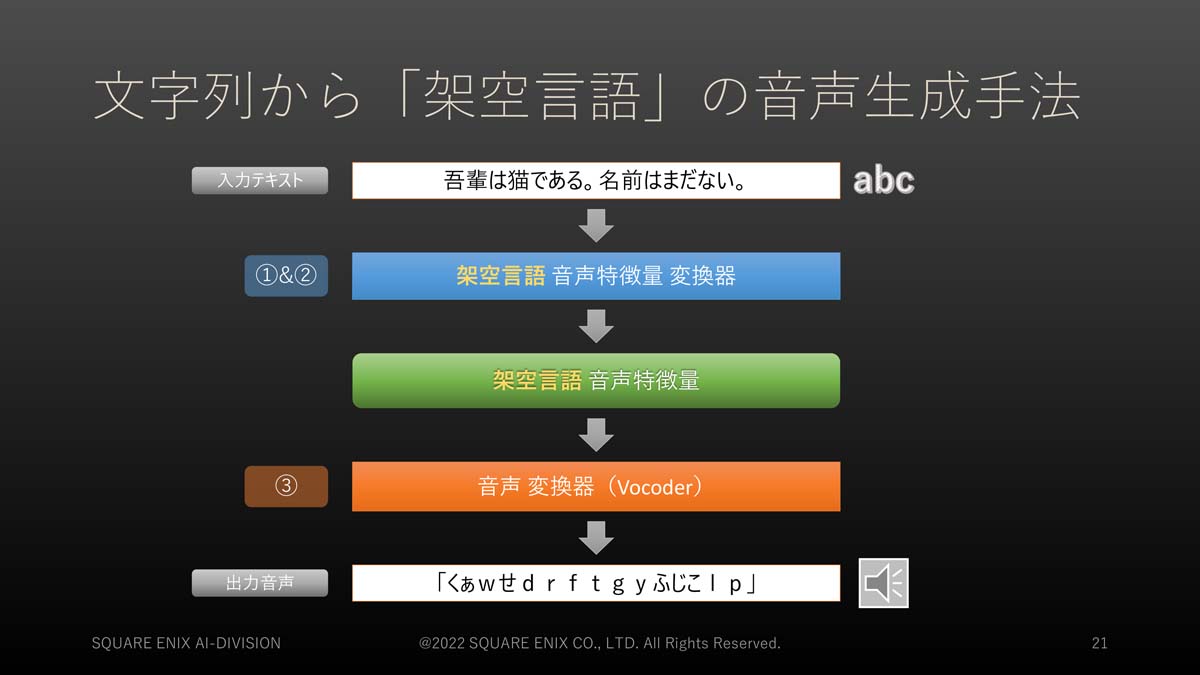
架空言語音声を出力する場合のパイプライン
しかし、ここで架空の言語の音声特徴量変換器をどうしたら作れるかが問題となります。森氏は、機械学習を用いたTTSにテキストを入力する際、テキストをコンピューターが扱える形式にするために、言語依存性がある変換が行われていることに注目。「テキストを音声特徴量に変換する(3つのステップの①と②)」際に、最初に入力したテキストの言語と異なる言語に対応したモデルで変換することで実在しない言語による音声特徴量のデータを生成することにしました。
例えば、日本語で入力されたテキストを、英語モデルを用いて音声特徴量を得た上で英語の音声変換器により音声を出力すると、英語に似た架空言語による音声出力が期待できます。
日本語テキストから英語風架空言語音声を合成する手順
入力したテキストと異なる言語の音声特徴量を得る「音声特徴量変換器」には工夫が必要です。この工夫を説明するために、「テキストをコンピューターが扱える形式に変換する」部分について、改めて説明がありました。テキストをトークンに分割してから、さらに、各トークンをベクトルに変換するという、2つの処理が行われます。
まず、トークンへの分割については、Open JTalkのPythonラッパーであるpyopenjtalkでの分割が例として挙げられました。日本語テキストの分割の例であり、日本語に特化した処理が行われていると言えます。
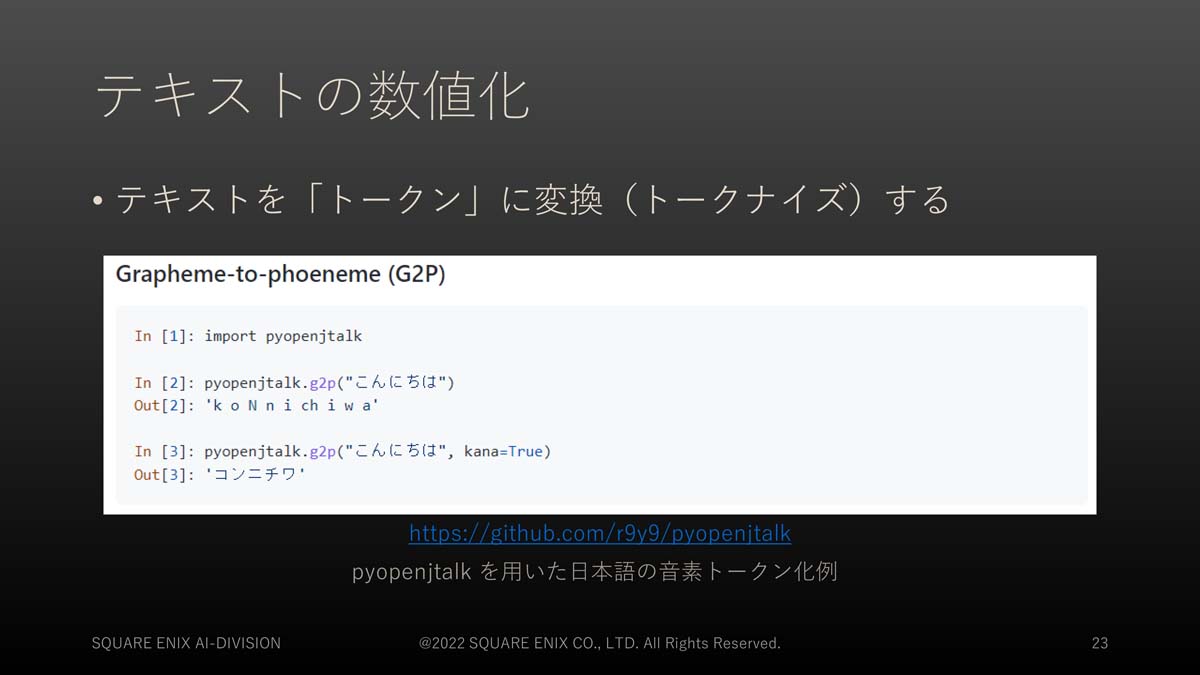
トークン化の例。pyopenjtalkで日本語テキストを音素表記に変換する
そして、トークンのベクトルへの変換については、Tacotron2の内部での処理が例に挙げられています。
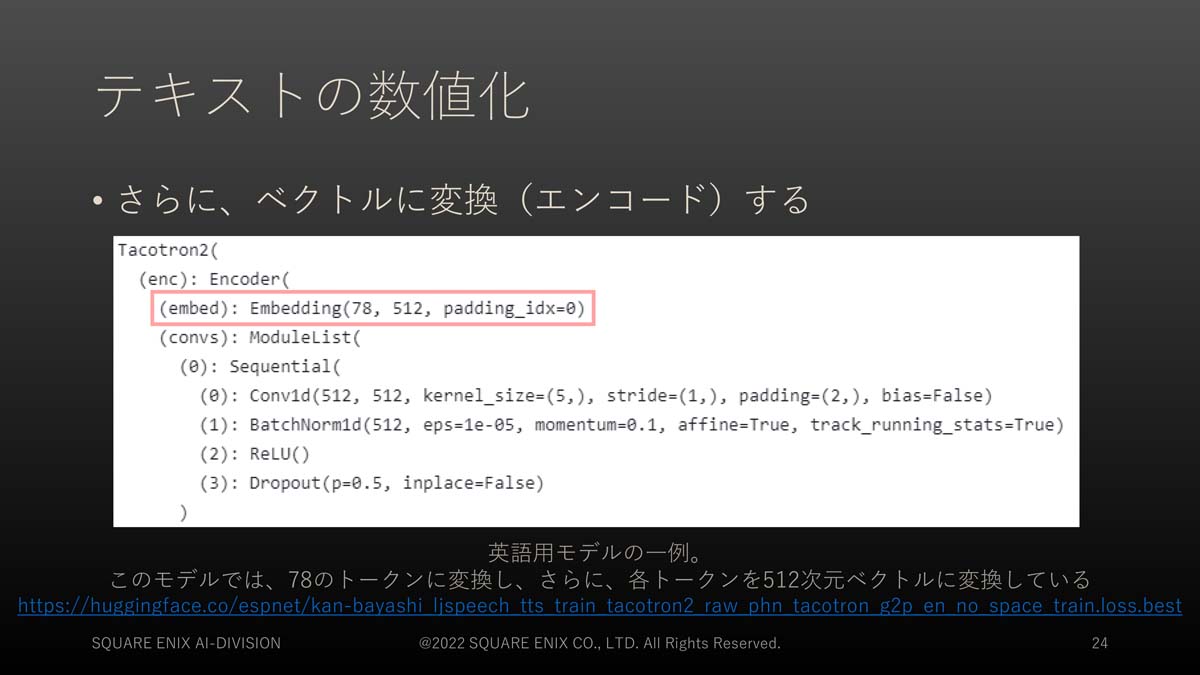
Tacotron2はGoogleが開発しているTTSアルゴリズム。GitHubではNVIDIAが実装した、音声変換モデルにWaveGlowを用いたPyTorchが公開されている
このモデルは英語の音声合成モデルの一例として挙げられたもので、英語テキストを78種のトークンに変換してから各トークンを512次元ベクトルに変換して、音声特徴量への変換を行っています。もしも、入力した日本語テキストを、Tacotron2の78種のトークンに対応付けることができれば、その後の処理は英語入力と同様に適用することができ、Tacotron2 を用いた架空言語の生成が行えます。つまり、日本語テキストを、他の言語のTTSモデルで使われるトークンに結び付けられるかどうかが重要なのです。
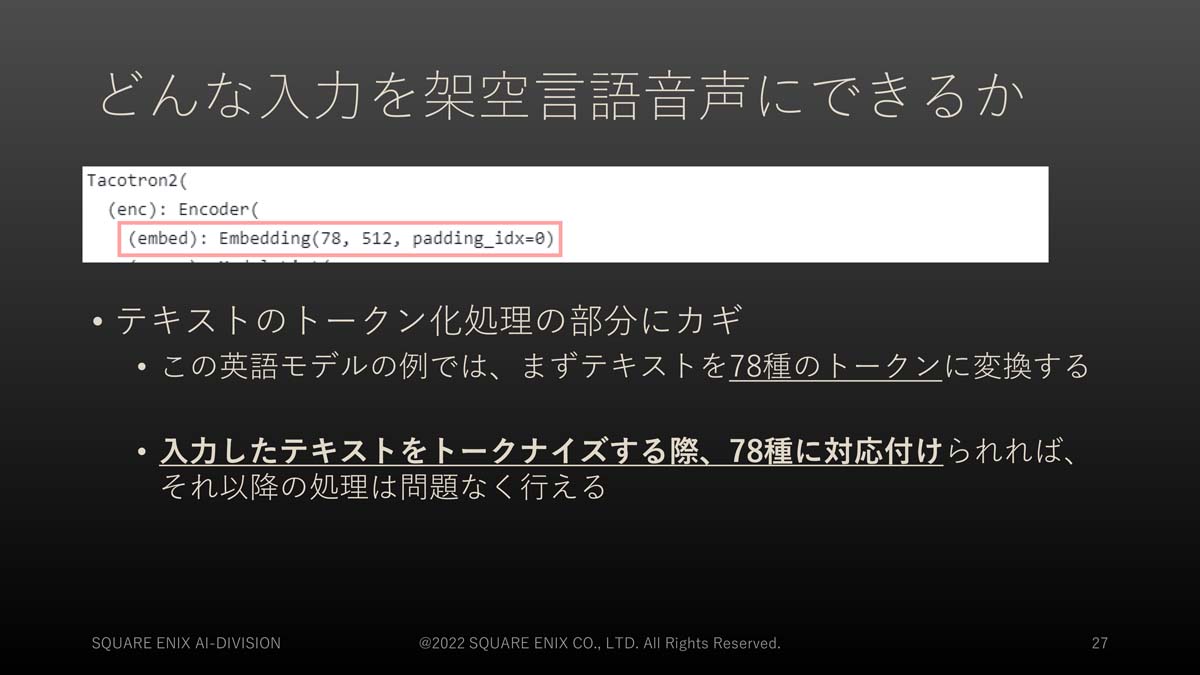
トークンを対応させる際に英語ではない要素「Out Of Vocabulary(OOV)」に対する処理も定義されていれば、架空言語音声生成にTacotron2など英語用の音声合成モデルを使用できる
架空言語音声のサンプル
以上の工程で生成された架空言語音声が、講演でも実際に再生されました。それでは実際の音声をお聞きください。
※再生ボタンをクリックすると音声が再生されますのでご注意ください。
これはある日本語の小説の冒頭を読み上げたものです。では、実際のテキストを見ながらもう一度お聞きください。
こちらは夏目漱石「吾輩は猫である」の冒頭です。
もう1例、架空言語による音声合成の例をお聞きください。
こちらは太宰治「走れメロス」の冒頭です。
筆者の主観ではありますが、どちらも一つ一つの単語が架空言語でありながら日本語を聞いているような「間」を持っており、合成音声としての違和感が少なく「聞きなれない架空の言語」のように聞こえました。
生成された架空言語音声の特徴や用途
こういった機械学習によって生成された架空言語音声には、これまでにない特徴や用途があります。
従来の手法では字幕と音声の長さに違いがあり言語によっては意図した“間”を表現できないことがありましたが、この架空言語音声では可能になります。
また、ゲームのプレイヤーの行動次第で新しいテキストが発生した際に、そのテキストに合わせた音声を動的に生成することが可能になりコンテンツに組み込めます。
そして、ここまでの説明にあった通り、聞きなれない言語であることから合成音声としての違和感が感じにくくなります。

さらに、多言語対応タイトルにも活用できます。今回の生成手法が「○○○語のテキストを×××語風の架空言語として生成する」方法なので、プレイ言語によって架空音声の内容を変えたり、複数の架空言語に対応させたりすることが可能です。

これによりインタラクティブなコンテンツをフルボイスにできるメリットがあります。プレイヤーの入力次第でゲームの内容が動的に変化していく場合にすべてのボイスを収録するのは大変です。しかし、音声合成を使うことで、動的に生成された部分にもボイスを付与することができます。
さきほど特徴として「動的生成が可能」とありましたが、フルボイスのコンテンツの場合にゲームの内容が動的に変化してもすべてのボイスを収録する必要が無くなります。
そして「フィクションの世界で話されている言語」を実際に耳にすることができる、というまったく新しい体験を得られます。
おわりに
以上が森氏による講演内容となりますが、その冒頭に語られた言葉が今回紹介された技術の大きなメリットとも言えます。
「この技術では人工的に言語を作る必要はない」、「言語に関する専門的な知識がなくても、日本語の文章を入力するだけで、ゲームの世界に本当に存在するかのような音声を作り出せる」ということです。
変換モデルの組み合わせにより無限ともいえる架空言語を産み出せること、それらが大きな工数やスペックを必要とせずに可能となること、これらのゲームコンテンツを豊かにしてより没入感を高める手法として今回の講演は非常に貴重なものでした。
スクウェア・エニックス 公式サイト意味が分からないからこそ、リアル ~「架空言語」音声合成による、没入感の高いボイス付きコンテンツの実現~-CEDEC+KYUSHU 2022
ゲーム会社で16年間、マニュアル・コピー・シナリオとライター職を続けて現在フリーライターとして活動中。 ゲーム以外ではパチスロ・アニメ・麻雀などが好きで、パチスロでは他媒体でも記事を執筆しています。 SEO検定1級(全日本SEO協会)、日本語検定 準1級&2級(日本語検定委員会)、DTPエキスパート・マイスター(JAGAT)など。
関連記事



注目記事ランキング
1
2
3
4
5
1
2
3
4
5
1
2
3
4
5
1
2
3
4
5
1
2
3
4
5
連載・特集ピックアップ
西川善司が語る“ゲームの仕組み”の記事をまとめました。
Blenderを初めて使う人に向けたチュートリアル記事。モデル制作からUE5へのインポートまで幅広く解説。
アークライトの野澤 邦仁(のざわ くにひと)氏が、ボードゲームの企画から制作・出展方法まで解説。
ゲーム制作の定番ツールやイベント情報をまとめました。
CEDECで行われた講演のレポートをまとめました。
UNREAL FESTで行われた講演のレポートやインタビューをまとめました。
GDCで行われた講演などのレポートをまとめました。
CEDEC+KYUSHUで行われた講演のレポートやイベントレポートをまとめました。
GAME CREATORS CONFERENCEで行われた講演のレポートをまとめました。
Indie Developers Conferenceで行われた講演のレポートやインタビューをまとめました。
ゲームメーカーズ スクランブルで行われた講演のアーカイブ動画・スライドやレポートなどをまとめました。
東京ゲームショウで展示された作品のプレイレポートをまとめました。
BitSummitで展示された作品のプレイレポートをまとめました。
ゲームダンジョンで展示された作品のプレイレポートをまとめました。
日本と文化が近い中国でゲームを展開するための知見を、LeonaSoftware・グラティークの高橋 玲央奈氏が解説。
インディーゲームパブリッシャーの役割や活動内容などを直接インタビューします。




今日の用語
ワイヤーフレーム(Wire Frame)
- 3Dモデルのエッジ情報のみを表示するレンダリング手法。ゲーム開発においては、3Dモデルやシーンのポリゴン構造を確認することに用いることが多い。
- UIやWebページなどのレイアウトを決めるための設計図。
Xで最新情報をチェック!




