
国内最大規模のゲーム業界カンファレンス「CEDEC2023」が、2023年8月23日(水)から8月25日(金)までの日程で開催されました。初日となる8月23日には、STORIA法律事務所 パートナー弁護士 柿沼太一氏が登壇し、「コンピューターエンターテインメント領域における生成AIの利用と法律・知財・契約」と題した講演が行われました。生成AI(画像生成AIを主たる対象とし、それ以外の生成AIについても必要に応じて触れる)をコンピューターエンターテインメント領域にて利用する場合の法律上の留意点について解説した本講演をレポートします。

「生成AI」は著作権を侵害するか?AI生成物に著作権は発生するか?コンピューターエンターテインメント領域における生成AIの利用と法律【CEDEC2023】




TEXT / じく
EDIT / 酒井 理恵
目次
【編集者注】講演内容に入る前にAIが関連する「著作権」の領域を知る
本講演は、そもそも著作権とはどのようなもので、どのようなとき著作権侵害とみなされるかの基本的な知識を持っているほうが理解しやすい講演となっています。特に、文化庁が動画と講演スライドを公開している『AIと著作権』の内容をおさえておくと良いと考えます。
文化庁『令和5年度著作権セミナー「AIと著作権」の講演映像及び講演資料を公開しました。』著作権法は著作物や著作者、そして著作物の実演など幅広い領域の権利を扱う法律です。そのなかでも、AIの文脈では「後発の作品が既存の著作物と同一、又は類似していること」という「類似性」、「既存の著作物に依拠して複製等がされたこと」という「依拠性」に着目し、著作権侵害の有無について論じられることが多いです。
また、著作権法には著作権侵害にあたらない「権利制限規定」があります。権利制限規定にあたるものには「私的使用のための複製/引用/学校や教育機関における複製/非営利・無料・無報酬での上演」などに加えて「情報解析」があり、AIに使われる学習データがこれに該当するかどうかも論点となるところです。
この「類似性と依拠性」「権利制限規定」の2点を念頭に、以降の講演レポートをご覧ください。
生成AIの何が問題か? 著作権に関する3つの論点

左が柿沼太一氏、右が本セッションをコーディネートしたバンダイナムコ研究所 髙橋誠史氏

経済産業省「AI・データ契約ガイドライン」検討会検討委員(2018年3月まで)の経験も
登壇したのはSTORIA法律事務所のパートナー弁護士 柿沼太一氏。専門分野はスタートアップ法務、AI・データ法務、ヘルスケア法務です。
講演において、柿沼氏は最初に生成AIと著作権に関する3つの論点から説明を始めました。それぞれの論点をAIによる学習と生成の流れに照らし合わせながら確認します。
1つ目は、AI開発・学習に既存著作物を利用することが著作権侵害になるか、という「AI開発・学習と著作権侵害」の問題です。
※ 本記事掲載のスライド画像内にときおり見られる赤い点は講演時に使用されたポインターで、画像の説明内容には含まれません
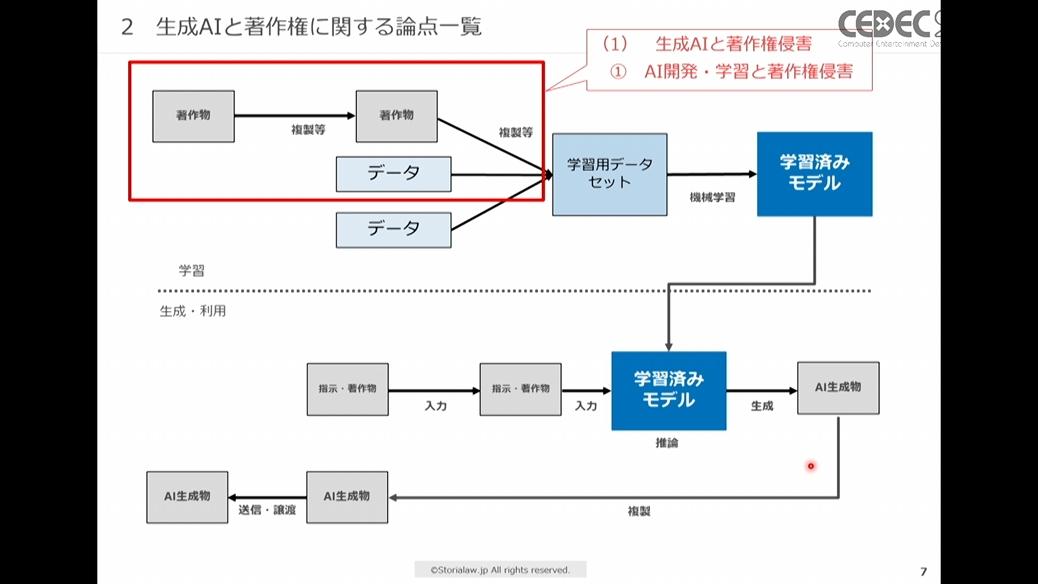
赤枠内がAI開発・学習と著作権侵害を考える際にかかわる領域
2つ目は、AI生成物の生成に際して既存著作物を利用することや、既存著作物と同一・類似のAI生成物を生成・利用することが著作権侵害になるか、という「AI生成物の生成・利用と著作権侵害」の問題です。
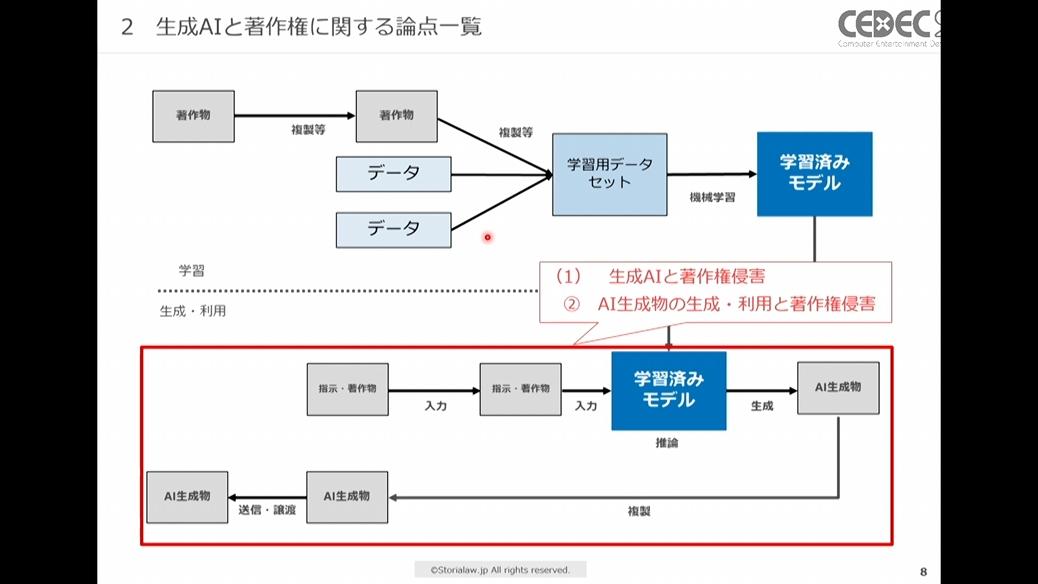
赤枠内がAI生成物の生成や利用の問題に関する領域
3つ目は、AIを利用して生成したAI生成物に著作物性が認められるのはどのような場合か、という「AI生成物と著作物性」についてです。
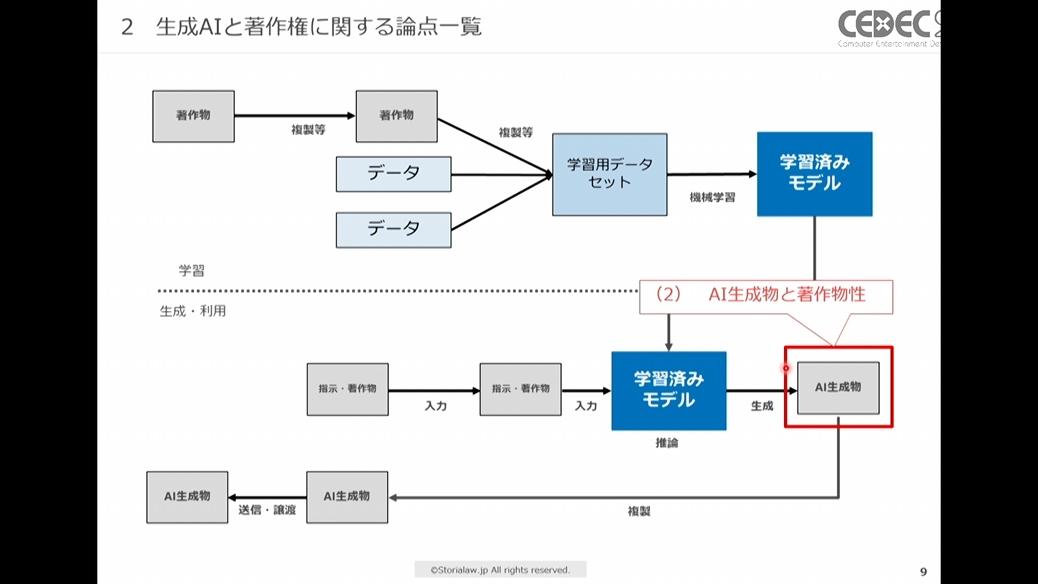
赤枠内がAI生成物に著作権が認められるかの問題に関する領域
それぞれの論点で、何が問題となっているのか具体的に見ていきます。
論点①:AI開発・学習は著作権を侵害するのか?
既存著作物をAI学習に利用する行為は、「デジタルデータのダウンロード」「入手したデータを学習用に加工」という点において複製行為を行なっていると考えられます。この複製行為が著作権侵害にあたるか、という論点があります。
まず、既存著作物を認識しながら複製行為を行っているので、著作権侵害の要件である類似性・依拠性は肯定されます。
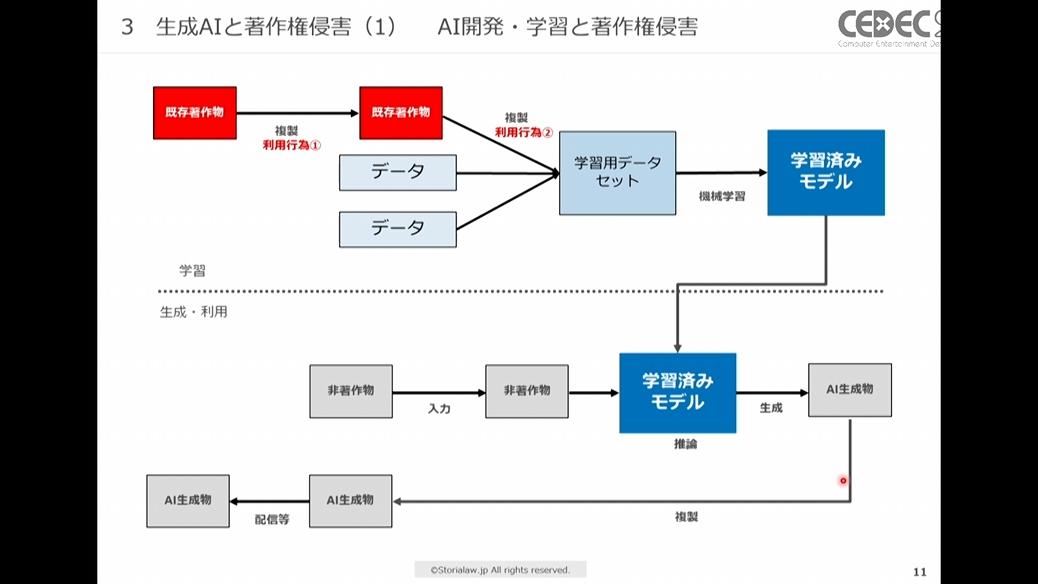
既存著作物をダウンロードする(利用行為①)のも入手したデータを学習用に加工する(利用行為②)のも複製行為にあたる
この複製行為は著作権法の権利制限規定(※)の1つである著作権法 第三十条の四 第二号により適法になります。
※ 権利者の了解を得なくても著作物を利用できる著作権の例外。たとえば、私的使用のための複製や報道・批評等の目的での引用、試験問題としての複製などがこれにあたる
AI学習に既存著作物の複製を認める「著作権法 第三十条の四 第二号」とは?
(著作物に表現された思想又は感情の享受を目的としない利用)
第三十条の四 著作物は、次に掲げる場合その他の当該著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない場合には、その必要と認められる限度において、いずれの方法によるかを問わず、利用することができる。ただし、当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。
一 著作物の録音、録画その他の利用に係る技術の開発又は実用化のための試験の用に供する場合
二 情報解析(多数の著作物その他の大量の情報から、当該情報を構成する言語、音、影像その他の要素に係る情報を抽出し、比較、分類その他の解析を行うことをいう。第四十七条の五第一項第二号において同じ。)の用に供する場合
三 前二号に掲げる場合のほか、著作物の表現についての人の知覚による認識を伴うことなく当該著作物を電子計算機による情報処理の過程における利用その他の利用(プログラムの著作物にあつては、当該著作物の電子計算機における実行を除く。)に供する場合
第三十条の四では、著作物に表現された思想や感情の享受(※1)を目的としない利用の場合に情報解析を認めています。これには一般的な大規模な情報解析やファインチューニング(※2)、LoRA(※3)といった追加学習、パラメーターの更新行為なども含まれます。
※1 文章の閲読・プログラムの実行・音楽や映画の鑑賞などの行為を通じて知的・精神的欲求を満たす効用を得ること
※2 事前学習済みのモデルに新たなデータセットを追加してモデルを再学習させること。モデルの再調整、精度向上の目的で行われる。パラメーターを微調整すれば、特定のタスクに特化した新たなモデルの作成が可能
※3 Low-Rank Adaptation。「追加学習」の手法の一種。モデルの複雑性を削減させる計算方法により、計算効率の向上や有用な特徴を抽出することができる 。例えば、画像生成に関して言えば、特定のポーズや服装を学習させることが可能
日本の著作権法 第三十条の四に関して、以下の点が特殊であると柿沼氏は言います。
(1)あくまで学習に関する規定で、AI生成物の生成や利用とは無関係
AIを使って他者が制作した著作物とそっくりのものを意図的に作った場合は違法となる可能性もあります。
(2)諸外国と比較して主体や利用目的に制限がなく緩やか
英国にも同様の規定がありますが「非商業的調査のためのテキストおよびデータ解析のための複製」と用途が限定的です。日本の場合は利用目的に制限がなく、営利目的でも利用が可能です。「世界的に見ても寛容な規定」と柿沼氏は言います。
(3)利用行為が行われる国(サーバ所在地など)の著作権法が適用される
「日本の著作権法が適用されるかどうか」は著作権法ではなく準拠法の管轄になります。
これによると、著作権法は「当該著作物が利用される地」の法律が適用されます。インターネット上のデータの場合はサーバーの所在地の法律に従うことになります。たとえば、日本のサーバーで、日本に作業者がいる場合は日本の著作権法が適用されます。しかし、サーバーまたは作業者のいずれかが海外の場合は日本の著作権法が適用されない可能性が高いので、注意が必要とのこと。
(4)準拠法の規定は利用行為を規定するもので、著作権者が誰なのかは無関係
海外の企業が権利を持つ著作物であっても、日本国内で利用する場合は日本の著作権法が適用されます。
(5)著作権表記(©)の有無と著作権の有無は現行の法律上はほとんど関係ない
著作権が発生する著作物であっても、日本国内での利用ならば第三十条の四が適用され、AI学習のための既存著作物の複製が認められます。
AI学習目的で既存著作物を複製する行為はなんでも許されるのか?
第三十条の四は、一見、AI学習のためならば既存著作物の複製がなんでも許されるように見えますが、この法律には2つの例外があります。
例外1:学習時に学習対象著作物の享受目的も併存している場合
情報解析(学習)のために対象対象著作物の利用行為を行うに際して、対象著作物の「表現上の本質的な特徴」を感じ取れるような著作物の作成目的(=対象著作物の享受目的)が併存している場合は、対象著作物の利用行為は第三十条の四の対象になりません。
では、どのようなものが「表現上の本質的な特徴」を感じ取れる著作物にあたるのでしょうか。柿沼氏はLoRAなどの技術を利用した「作風が似ている」というレベルでは享受目的の併存には該当しないと考えられると言います。該当するのはAIが生成するものが元の著作物そのものであるようなものの場合だそうです。
ただ、AI生成物がまだ生成されていない学習段階において享受目的の併存が認定されるケースがどれくらいあるのか、個人的には疑問だと柿沼氏は語りました。
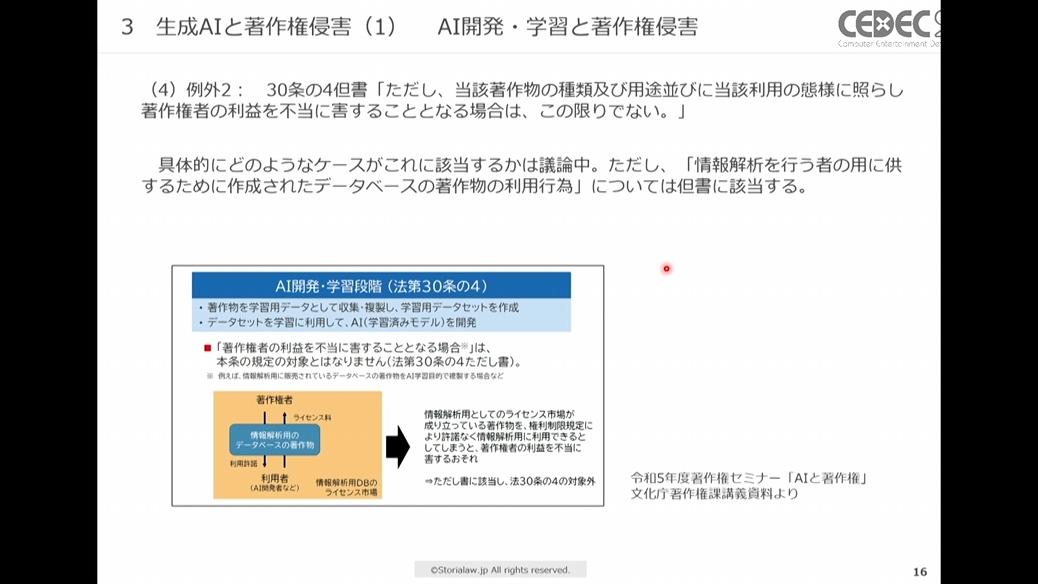
例外2:第三十条の四の但書「ただし、当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りではない。」
もう1つの例外となるこちらについては、法律でも具体的なケースの記載がなく、現在も論議がなされています。ただし、その段階でも「情報解析を行う者の用に供するために作成されたデータベースの著作物の利用行為」は、この但書に該当する行為と考えられています。
具体的には、ライセンス市場が成り立っている学習用データセット(※)を、許諾なくAI学習のためのデータとして複製することがこれに当たります。立法の趣旨と照らし合わせると、これ以外のケースで但書に該当することはあまりないだろう、とのこと。
※ 機械学習に必要なデータのセット。機械学習モデルはこのデータから新しいパターンや法則を見つけだし、予測や推論を行う
以上、一部の例外はありますがAI開発・学習のために著作物を利用するのは原則として適法と考えられます。
論点②:生成AIを使った出力は著作権を侵害するのか?
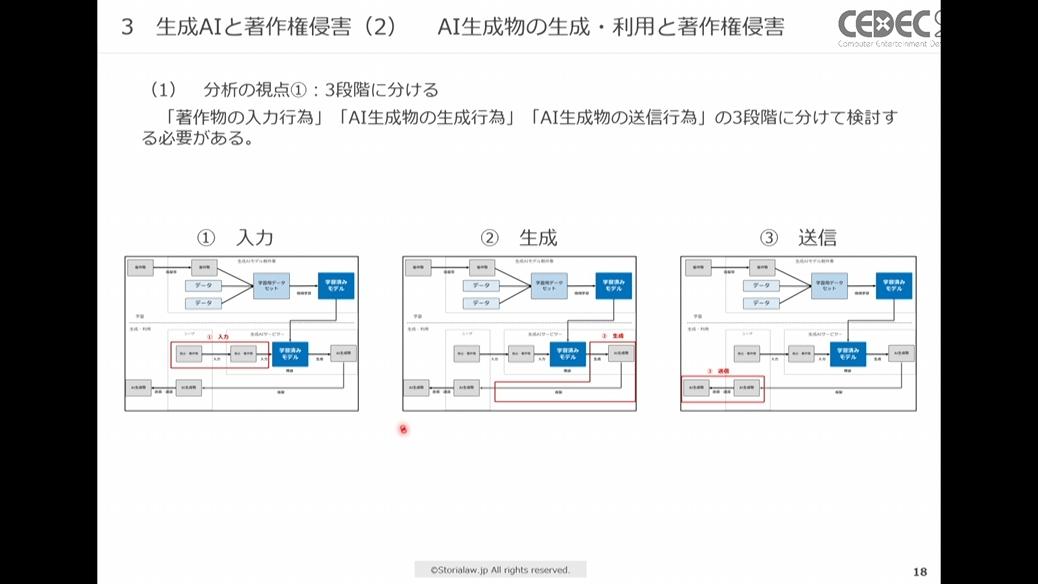
次に学習済みモデルによってAI生成物を生成・利用する行為を検討します。これらの行為は「著作物の入力行為(下図左)」「AI生成物の生成行為(下図中)」「AI生成物の送信行為(下図右)」の3段階に分けて検討する必要があります。
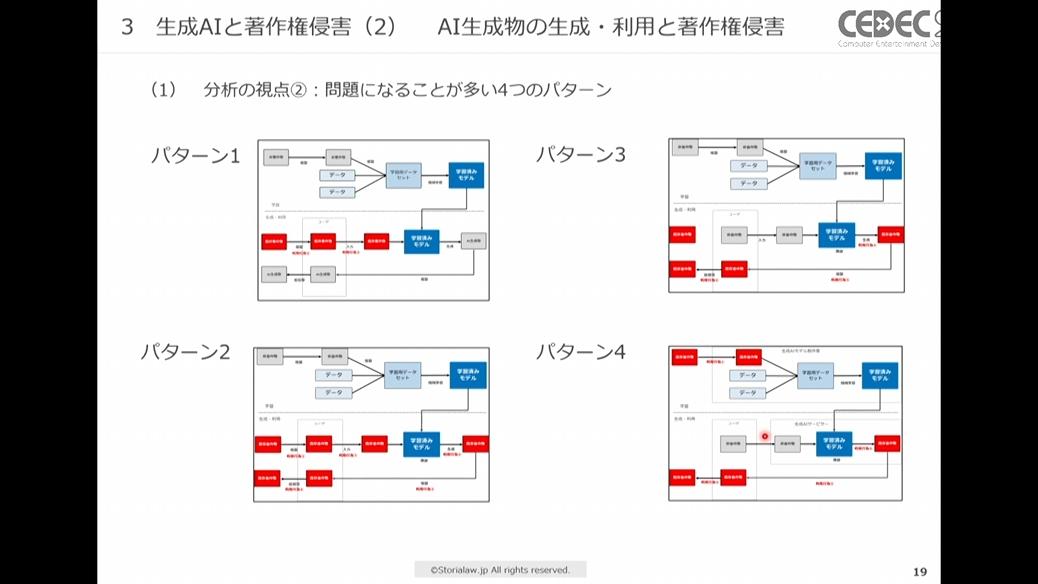
入力・生成・送信の段階に分けて著作権侵害になるかを検討していくと、問題になることが多いのは下図の4パターンになります。パターン1~3は学習時には既存著作物を使っていないケース、パターン4は学習時に既存著作物を使っているケースです。
それぞれのパターンについて詳しく見ていきます。
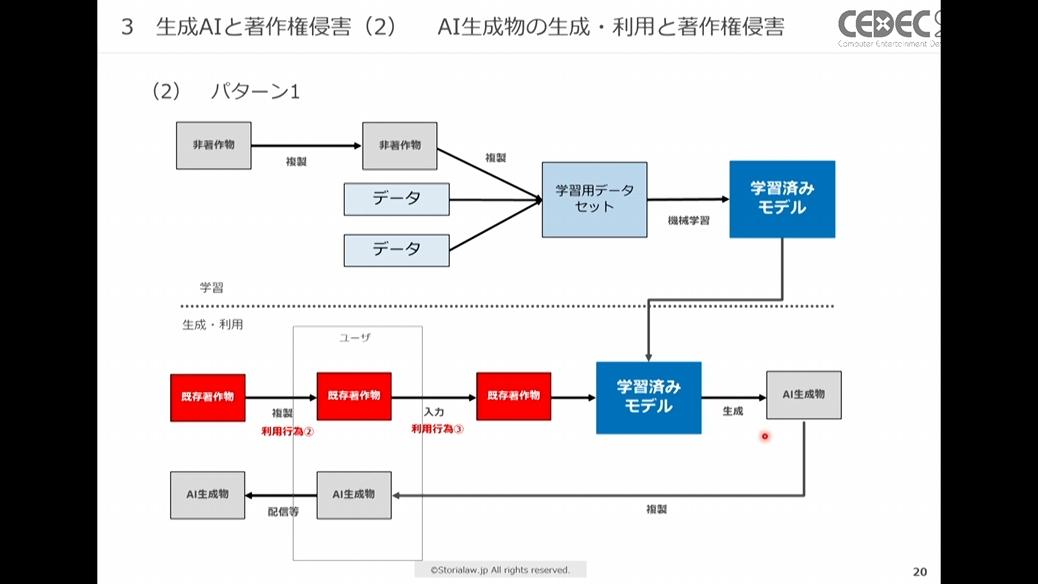
パターン1:入力時に既存著作物を利用し、出力時に類似著作物が生成されていない場合
プロンプトや指示の入力時に、既存著作物の絵や文章などを複製し(下図の利用行為②)、生成AIに入力したものの(下図の利用行為③)、AIの生成した物が既存著作物とは類似していなかった場合などがこのケースに該当します。
このケースで生成AIに入力する行為は、複製行為にあたります。また、類似性・依拠性も認められるため権利制限規定の適用がなければ著作権侵害に該当します。
はたして、このケースに該当する権利制限規定の適用はあるのでしょうか?
結論から述べると、この行為は前述の第三十条の四に挙げられた情報解析に必要な行為に該当するので、原則として適法になると柿沼氏は言います。生成AIは自身のモデル内で情報解析を行うツールと考えられます。そうすると、その前段階のプロンプトや指示の入力行為は、生成AIに必要な「情報解析」の準備行為と考えられるためです。
利用行為②③は学習段階と同じく、このケースでも適法
ただし、第三十条の四には権利制限規定が適用されない例外「対象著作物の享受目的も併存している場合」がありました。こちらは該当しないのでしょうか?
こちらについては、モデル学習段階よりも対象著作物の享受目的併存が認められるケースが多いだろうと柿沼氏は言います。
例えば、翻訳や要約などは、AIが生成した物が元の著作物の表現上の本質的な特徴を感じ取れるようになってしまう可能性があります。一方、先述した通りAIが生成した物が「作風が似ている」程度であれば享受目的の併存は認められないのでは、と柿沼氏は考えます。
このケースで享受目的が併存していると判断されるかどうかは、エンターテインメントの文脈だけでなく社内データベースの利用にも影響を及ぼします。
最近は、データベースに対し社内あるいは社外のデータを高度な検索にかけることが増えてきているといいます。このとき、検索のキーワードとしてプロンプトに既存著作物を入力した結果、検索結果として既存著作物と同じデータを得てしまうことがあります。Googleの対話型AIサービス「Bard」では、質問への回答作成時に、根拠となるWebサイトの内容を適宜加工して表示していますが、これも似たようなケースとして考えれると、柿沼氏は述べました。
パターン2:入力時に既存著作物を利用し、出力時に類似著作物を生成した場合
プロンプトや指示の入力時に、既存著作物の絵や文章などを複製して生成AIに入力し、AIの生成した物が既存著作物と類似していた場合などがこのケースに該当します。
AIによる生成行為そのもの(下図の利用行為②~⑤)とAI生成物を配信・譲渡する行為(下図の利用行為⑥)は分けて考えていきます。
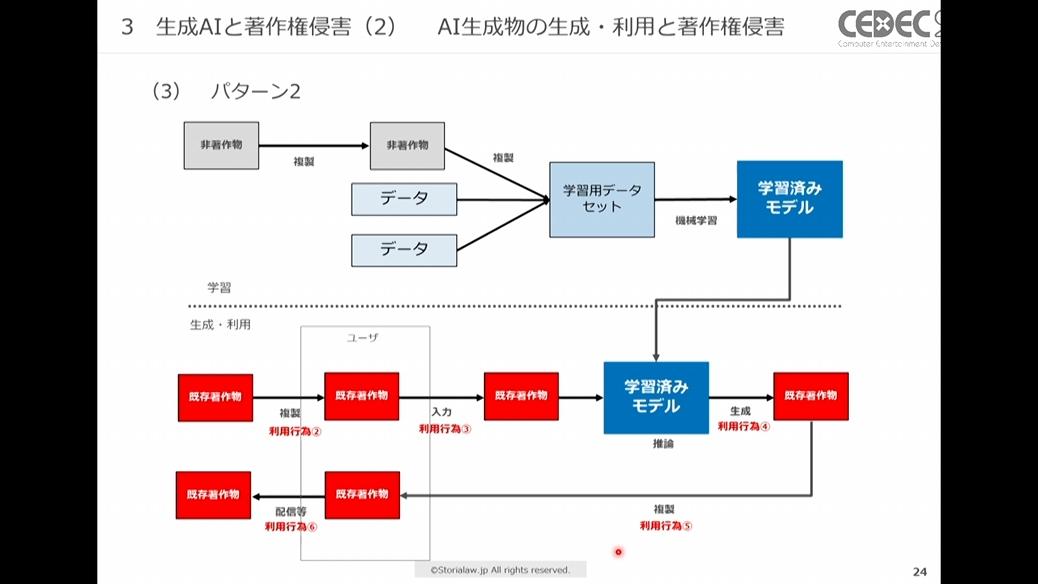
利用行為②~③が生成AI入力時、利用行為④~⑤が生成AI出力時、利用行為⑥が配信・譲渡時にかかわる箇所
【AIによる生成行為】
まず、生成前の入力に関する部分(上図の利用行為②③)について考えます。
このケースで生成AIに既存著作物を入力する行為は、パターン1と同じく複製行為にあたります。また、類似性・依拠性も認められるため権利制限規定の適用がなければ著作権侵害に該当することも同様です。
では、情報解析目的ならば既存著作物の複製を許していた権利制限規定の第三十条の四が適用されるかというと、このパターン2では適用されません。その理由は第三十条の四の例外「対象著作物の享受目的も併存している場合」に該当するためです。
よって、生成AIへの入力は権利制限規定は適用されず著作権侵害に該当すると思われます。
次に、生成AIによる出力に関する部分(上図の利用行為④⑤)について考えます。
生成段階では、権利制限規定が適用されるならば適法ですが、それ以外の場合の生成行為は著作権侵害に該当すると思われます。
この場合に適用できる権利制限規定には以下のようなものが考えられると柿沼氏は言います。
- 第三十条:私的利用目的の複製(※1)
- 第三十条の三:検討過程における利用(※2)
※1 家庭内で仕事以外の目的での使用であれば著作物の複製や翻訳・編曲・変形・翻案を認めるもの。例えば、自分で視聴する目的でテレビ番組を録画する行為など
※2 企業等で案の検討資料目的であれば著作権者の許諾がなくても利用を認めるもの。例えば、雑誌で使うイラストを検討するために著作権者に許諾を取る前の段階で企画書にイラストをコピーする行為など
なお、AIへの入力段階で適用された権利制限規定 第三十条の四「情報解析に必要な行為」はAI生成物の生成行為が「情報解析の結果」となるため適用されません。
【AI生成物を配信・譲渡する行為】
次は、AIによる生成物を配信・譲渡する行為(上図の利用行為⑥)についてです。
配信や譲渡といった行為はAIの入力・出力時とは異なり権利制限規定がありません。よって、パターン2「入力時に既存著作物を利用し、出力時に類似著作物を生成した場合」では、いずれの場合も著作権侵害に該当します。
以上がパターン2「入力時に既存著作物を利用し、出力時に類似著作物を生成した場合」の論点です。このパターン2の場合は、ユーザー自身が既存著作物を入力しているので「類似著作物が偶然生成された」という言い訳は通用しません。
パターン3:入力時に既存著作物を利用せず、出力時に類似著作物を生成した場合
既存著作物を利用せず簡単な指示や独自のプロンプトのみを入力した結果、既存著作物と類似した著作物が生成された場合です。この場合はユーザーが類似した元の既存著作物を知っていたかどうかに主眼が置かれます。
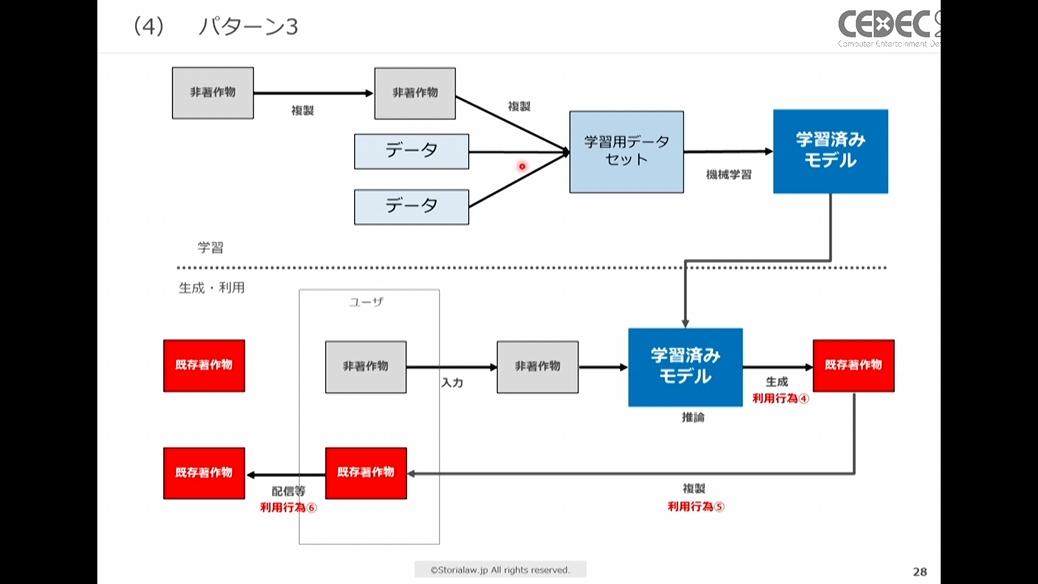
利用行為④~⑤が生成AI出力時、利用行為⑥が配信・譲渡時にかかわる箇所
【ユーザーが知っていた場合】
生成段階における類似性と依拠性が認められるため、著作権侵害になります。
前述のパターン2「AIによる生成行為」の場合と同様に、「私的利用目的の複製(第三十条)」「検討過程における利用(第三十条の三)」の権利制限規定が適用されるならば適法ですが、それ以外の場合の生成行為は著作権侵害になります。
また、その類似生成物を配信・譲渡した場合もパターン2「AIによる生成行為」の場合と同様に、類似性と依拠性は認められます。配信時に関係する権利制限規定もないと思われます。
【ユーザーが知らなかった場合】
学習用データに既存著作物の使用がなく、かつユーザーが既存著作物の存在を認識せずに利用していた場合、AI生成物は独自創作として偶然生成されたものとして扱われます。これは「既存の著作物に接していて、それを自作品の中に用いた」という依拠性がないためです。
この場合、独自創作として偶然生成されたものなので著作権侵害にはならず適法となります。配信行為についても同様です。
ただし、これは理屈上の話であり、その主張が通るかどうかはまた別の問題です。例えば、誰もが知っている有名な既存著作物の類似著作物が生成された場合、「知りませんでした」という言い分は厳しいと思われます。
パターン4:学習時にのみ既存著作物を利用し、類似著作物を生成・利用した場合
モデル学習時には既存著作物を利用した(下図の利用行為①~②)がAI生成のプロンプト入力には使用しておらず、結果的に類似著作物が生成された(下図の利用行為⑤~⑥)場合です。
このパターンでは、学習済みモデルの中に既存著作物に関連付けられたパラメーターが存在している可能性があるため、ユーザーがたまたまそのパラメーターを呼び出すような指示をプロンプトに入力した場合に、学習に使われた既存著作物が生成されてしまうことがあります。
この場合は、ユーザーが「学習に既存著作物が使われていたことを知っていたか」「出力された既存著作物を知っていたか」の2点が判断材料になります。

これまでのパターン1~3は学習段階で既存著作物が利用されていない場合だったが、このパターンでは既存著作物が含まれている
【ユーザーが知っていた場合】
ユーザーが、モデル学習時に既存著作物が使われていたことを知っていた、あるいは、AIから出力された生成物が既存著作物であることを知っていた場合です。
この場合は、類似性と依拠性が認められるため、著作権侵害となります。
【ユーザーが知らなかった場合】
このケースが最も難しい問題になると柿沼氏は言います。仮にこの場合が著作権侵害になってしまうと、モデルの学習用データセットの中身を知らないユーザーは著作権侵害を恐れて生成AIを使いにくくなります。ここで注視すべきは著作権侵害の要件の1つである依拠性(※)になります。
※ 既存著作物に接してそれを自己の作品の中に用いているかどうか
このケースに日本の裁判例はなく、依拠性は認められるという学説が多数を占めています。そのため著作権侵害を安全に避けるならば、モデルの学習用データセットの調査やWeb検索などでリサーチを行い出力された生成物の類似性がないことを確認する必要がありますが、実際にはリサーチはかなり困難だと考えられると柿沼氏は語りました。
では、AI生成物をコンテンツ制作に使うことはできないのでしょうか?
生成AIは新しいツールですが、実はこの状況は「外部事業者にコンテンツ制作を委託した場合と似ている」と柿沼氏は言います。委託した外部事業者がきちんと仕事をする人であれば、著作権侵害は発生しないでしょう。しかし、制作を依頼した側からその実態がわかるものではありません。
こうしたことを踏まえて、AI生成物をコンテンツ制作に使う場合の現実的な対応策を考えるならば以下の3つになるだろうと柿沼氏は述べました。
- 対応策1:できるだけ大規模な学習モデルを使用し、特定のキャラクターや作家のみで学習した特化型AIを使わない
- 対応策2:入力プロンプトに作家名・作品名・キャラクター名など著作権侵害を誘発するテキストを含めない
- 対応策3:可能な限りモデルの学習用データセットを調査したり、AI生成物について類似するものがないかWeb検索などでリサーチする
対応策3は先述の内容と同じですが、これだけを行うのではなく、対応策1・2のように生成AIの選定や使用の場面から注意を払うことが重要だと柿沼氏は述べました。
このすべての対応策を実施しても著作権侵害のリスクが0になるわけではありませんが、かなり低減することはできるだろうと柿沼氏は考えています。
論点③:AI生成物に著作物性はあるか?
著作権侵害とは別に、生成AIには「AI生成物に著作権は発生するのか」という問題があります。AI生成物に著作権がなければ模倣され放題となってしまい、事業領域によっては大きな問題となります。
現時点で法律上どのようなケースでAI生成物に著作権が発生するかを確定した基準はないため、日本国内での議論について解説します。
まず簡単な分類としては、「人による創作→著作権あり」「AIによる創作→著作権なし」「AIを道具として利用した創作→著作権あり」と考えられています。
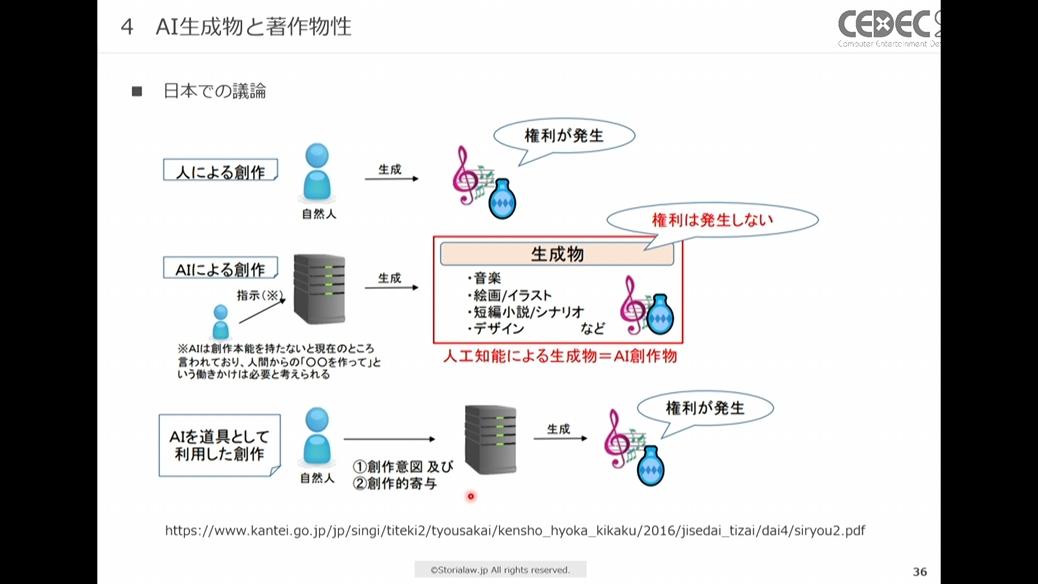
「○○を作って」という働きかけのみでは、単なるAIによる創作と見なされ著作権は発生しないと考えられている
以上のうち著作権の発生が認められるであろう「AIを道具として利用した創作」とは、人による創作意図(※1)があり、創作的寄与(※2)が行われた場合とされています。
※1 思想または感情を何らかの形式で表現しようする意図のこと
※2 創作を行うために具体的に起こした何らかの行動
「AIを道具として利用した創作」で創作意図および創作的寄与が認められるものとは具体的にはどのようなものなのでしょうか。この論点についてはアメリカで議論が先行しており、事例として直近で起こった「暁のZarya事件」(現地時間2023年2月21日に米国著作権局が結論)があります。
AI生成物に著作権は認められるのか?――「暁のZarya事件」の顛末
コミックブック『暁のZarya(原題:ZARYA OF THE DAWN)』という作品が米国著作権局に登録されました。その後、作者がSNSで本の画像は画像生成AI『Midjourney』を使用したものであると発表しました。

アメリカ合衆国において米国著作権局への登録は任意だが、さまざまなメリットがあるため登録する人が多い
すると、米国著作権局は期限までに作品を作った経緯の公開を求め、それがなされなかった場合は登録を却下すると通知を出しました。これに対し、『暁のZarya』の作者は弁護士を通じてツール名や制作経緯を説明した書面を提出しました。
この結果、『暁のZarya』の著作権は以下のような内容に決定しました。
- コミックで使用されている画像には著作権を認めない
- コミックのセリフ等に使われているテキストとコマ割等の構成には著作権を認める
この決定の背景には、アメリカで過去に行われた「写真が著作物と言えるのかどうか」の裁判結果があります。写真も「人ではなく機械が生成したもの」という点で生成AIの問題と構造が似ています。
この時は、写真の著作者は「実際に写真を形成した者」であり「独創的な人またはmaster mindとして行動する者(作品の実質的な支配をする者)」とされました。
これと比較して、『Midjourney』にテキストプロンプトを入力するユーザーは、生成された画像を「実際に形成」しておらず、「独創的な人またはmaster mind」にも当たらないと判断されました。『Midjourney』が作成した画像に対して「独創的な人またはmaster mind」として扱われるほどの十分な制御をしていないとみなされたのです。
このことから、ユーザーが結果を制御・予測できない『Midjourney』などの拡散モデルでは、著作物性が認められないと考えられます。裏を返すと、何らかの結果をコントロールできる仕組みを入れたり、生成物をさらに加工したりすることで著作物性が認められると思われます。
本件を踏まえて米国著作権局は「AI生成素材を含む作品の著作権登録ガイダンス」(現地時間2023年3月16日)を発表しました。

ガイダンスではAI生成素材を含む著作物性の一般論を記載しており、「伝統的な創作の要素(文学、技術、音楽の表現または選択、配置などの要素)」が人間ではなく技術によって考案、実行されたかを問題としています。
例えば、プロンプトのみで生成された素材は創造性における最終制御を行っていないので、人間の著作行為としては認められません。重要なのは、人間が作品の表現に対して創造的な制御を持ち、伝統的な創作の要素を実際に形成したかの程度であるとしています。
なお、日本にはこのような著作権登録制度はなく、裁判例もまだありません。
創作的寄与に対する検討
日本において生成AIを使用した場合の「創作的寄与」はどのように判断されるのでしょうか。
例えば、テキストプロンプトを入力して画像を生成するText2Imageタイプの画像生成AIでの創作的寄与の度合いは、主に以下の4パターンが考えられます。
①短いプロンプトで一発出力
②長く複雑なプロンプトで出力
③プロンプトの長さや構成要素を複数回試行錯誤して生成されたものの中から優れた画像を選択
④AIが自動生成した画像を人間が加工
①は創作的寄与がなく、著作権は発生しないと判定されるパターンです。
逆に④は創作的寄与があり著作権が発生する、と考えられます。ただし、この場合も著作権が発生するのは加工を加えた部分に対してのみであるため、加工は全体的に行う必要があります。
上記のうち問題になるのが②や③のようなケースです。著作権の有無についても人によって意見が分かれています。
これまでの人間の創作で言えば、ディレクターがアーティストに、編集者が作家に細かい指示を出して生まれた作品でも、著作者はアーティストや作家でした。それを生成AIのケースに照らし合わせると、生成AIに指示を出した人間は著作者ではないと考えられます。しかし、人間が人間に指示を出していた場合の考え方を、その先に著作者となる人間のいないAIの事例にそのまま当てはめていいのかは議論の余地が残るところです。
一方、プロンプトに入力したテキストからテキストを生成するText2Textの文章生成AIの場合は画像生成と比べて「出力をコントロールして思い通りの文章を生成する」という意図が少ないため、AI生成物に著作権が発生しないケースが多いと推測されます。
以上を踏まえ、AI生成物に著作権を発生させるのに最も確実なのは、人間が十分な加筆修正をして人間の創作性を付加することだと思われます。
自社用生成AI、コード生成AI、アイデア出しへのAI利用――3つの設例に対する検討
これまでの論点を前提に、ゲームを中心としたコンピューターエンターテインメント領域であり得る3つの設例を挙げ、その回答となる検討結果を提示しました。
自社専用の画像生成AIの構築
【設例】
第三者が提供する画像生成AIのOSS(オープンソースソフトウェア)を使い、他社の画像でファインチューニング(LoRA含む)を行って自社専用の画像生成AIを構築したいが、どのような点に注意する必要があるか。
【検討結果】
- 第三者の画像を収集する行為や、ファインチューニングに利用する行為は「情報解析」に該当して原則として適法
- ただし「特定キャラクターの生成を目的として、その画像のみを収集してキャラクター名と共に学習させる」のは享受目的の併存なのでNG
- 画風や作風の模倣のみを目的とする場合は適法
- 例えば、ポケットモンスターのキャラクター(複数種類)をポケットモンスター風の絵柄として学習させた場合は「作風」の学習となり適法になると思われる
- 対象が既存キャラクターではなく作家の作品であった場合も同様と考えられる
- ただし、その存在を知っている既存著作物と類似したAI生成物を生成した場合、それを配信等する行為は著作権侵害になる
- 例えば、ポケットモンスターのキャラクター(複数種類)をポケットモンスター風の絵柄として学習させた場合は「作風」の学習となり適法になると思われる
- 対象が既存キャラクターではなく作家の作品であった場合も同様と考えられる
コードの自動生成や修正
【設例】
自社システムを開発するに際して、コードを自動生成・修正するAIサービスを使って開発を進めているが、何か問題はあるか
【検討結果】
- 学習行為は行っておらず、当該AIサービスを利用しているだけなので「AI生成物の生成・利用と著作権侵害」のみを検討すれば良い
- モデル学習に利用されたコードと類似性のあるコードが出力された場合は、そのコードを利用すると著作権侵害になる可能性がある
- ただし、コードの著作物性には特殊性があり「短いコードやありふれたコード」「アルゴリズム(※)など特定の処理を実装しようとすると誰がコーディングしても同じようになるコード」の場合は、著作物性が否定される
- 同じアルゴリズムを異なるコードで表現している場合は、その類似性が否定される(コードの著作物性はコード表現の部分にあり、アルゴリズムは著作権で保護されないため)
- コードで著作権侵害になるケースは限定的。とはいえ、特徴的なコードが長く出力された場合は、Web検索などで類似したコードがないか調べる必要があると思われる
※ 問題を解決するための手順・計算方法。プログラミングで代表的なものにはソートアルゴリズムや検索アルゴリズムなどが挙げられる
既存著作物を利用したアイデア出し
【設例】
壁打ち(※)やアイデア出しのためにChatGPTのような文章作成AIに、他社が著作権を有するテキストを入力してアイデア出しをしてもらうことに問題はないか
※ 話を誰かに聞いてもらいその反応を返してもらうことで、自分の考えや悩みを整理すること
【検討結果】
- 既存著作物のプロンプト入力は「情報解析」に該当して原則として適法。アイデア出しのためなので享受目的の併存にもなり得ない
- 出力された回答に入力した既存著作物の表現上の本質的な特徴が含まれている場合は、著作権侵害になる可能性がある
- ただし、求めているのは表現ではなくアイデアであり、入力時の既存著作物を出力する目的で使うことはないため、結果的に著作権侵害になるケースは少ないと思われる
- 著作権法は表現を保護する法律であり、アイデア/知識/情報そのものを保護する法律ではない。アイデアが同じであっても表現が異なれば著作権侵害にはならない
- アイデア出しは「アイデアを抽出する」行為なので、著作権侵害になる可能性は低いと考えられる
【応用編】ゲーム内声優音声に生成AIを利用する場合の権利を考える
柿沼氏はゲーム内に収録する声優音声に関する権利についても、音声生成用AIの学習や利用を交えて説明しました。
このパートでは以下の3つの設例への回答をめざします。
- 設例1:さまざまなゲーム内の、さまざまな声優による音声を大量に収集し、音声生成用AIを作成したい。無断でそれらの声優音声データを収集してAIの生成(学習)に利用することは可能か
- 設例2:ある特定の声優の音声を再現するために、当該声優の音声を大量に収集し、音声生成用AIを作成したい。無断でそれらの声優音声データを収集してAIの生成(学習)に利用することは可能か
- 設例3:作成した音声生成AIを利用して、①特定のゲーム内の特定の声優による特定のセリフ音声と同じ音声を生成すること、または②特定の声優による、それまでに実演されたことのないオリジナルセリフ音声を生成することは可能か
声優によるセリフの実演で発生する3つの権利
あるセリフを声優が実演した場合、以下の3つの権利が発生します。矢印の先に示されるのが、それぞれの権利者です。
①セリフの著作権→セリフを作成した脚本家などの著作者
②声優の実演に関する著作隣接権(※)→実演した声優
③声優の声に関するパブリシティ権→声優
※ 実演家やレコード製作者、放送事業者などに与えられる権利。例えば、実演家には自分の実演の録音権・録画権・放送権などが認められており、実演・レコード発行は70年、放送または有線放送は50年、その権利が保護される
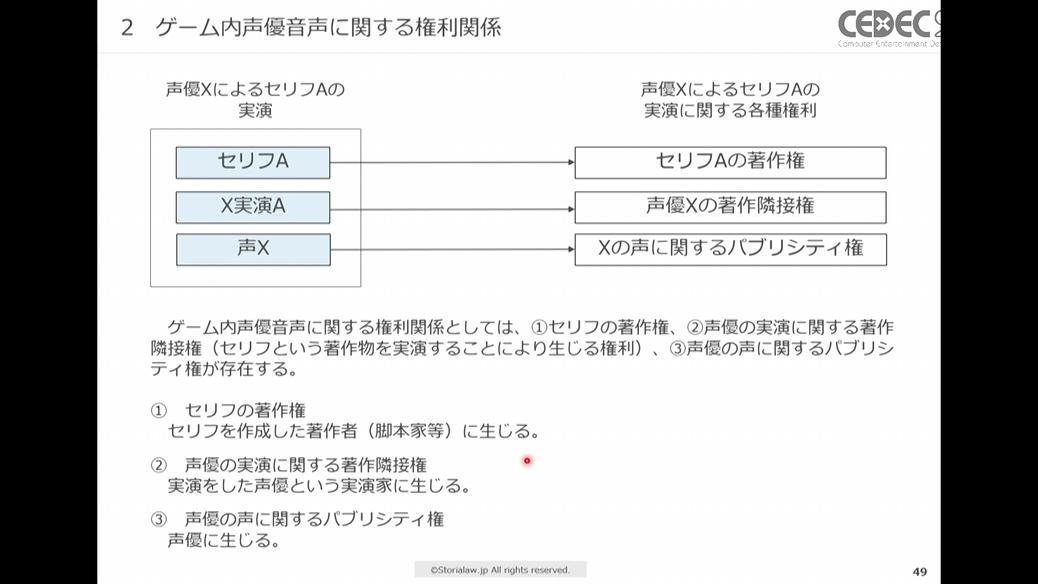
声優XがセリフAの実演をした場合の権利は「セリフA」、「声優Xが演じたセリフの実演A」、「声優Xの声」の3つの領域に分けて考えられる
法律にはない、人格権に由来する権利――パブリシティ権とは?
パブリシティ権とは「著名人の肖像や氏名のもつ顧客吸引力から生じる経済的な利益・価値を排他的に利用する権利」とされています。法律上明示的に認められた権利ではなく、人格権に由来する権利として裁判の判例上で認められてきた権利です。
最高裁判所が2012年2月2日に判決を出した「ピンク・レディー事件(※)」は、パブリシティ権をめぐるものでした。
※ 週刊誌がピンク・レディーのダンス振付を真似たダイエット記事掲載に際し、ピンク・レディー2人の過去の写真を無断で掲載。これをピンク・レディー側がパブリシティ権の侵害として訴えた事件。裁判では最終的にピンク・レディー側の主張が退けられた。
この時、裁判所は、著名人は時事報道・論説・創作物等に使用されることは正当な表現行為として受忍すべき場合もある、とした上で、パブリシティ権を侵害していると言える条件として以下の3点を挙げました。
- 肖像等それ自体を独立して鑑賞の対象となる商品等として使用(例:プロマイド写真としての使用)
- 商品等の差別化を図る目的で肖像等を商品等に付している
- 肖像等を商品等の広告として使用する
つまり、肖像を使用したら即パブリシティ権の侵害となるわけではなく、それが顧客吸引力の利用を目的として使われた場合にパブリシティ権の侵害が認められるということです。
この事件の調査官解説(※)では上記の3つの行為に登場する「肖像等」を「本人の人物識別情報をいうもの」とし、その具体例として「サイン、署名、声、ペンネーム、芸名等」を挙げています。
※ 民事篇平成24年度(上)18頁。調査官解説は、その判決に関わった人が判決に至るまでの過程などを解説している
これは声優やアーティストの「声」もパブリシティ権で保護されることを示しています。その声優の声であると認識できれば「何を喋っているか」とは無関係にパブリシティ権が発生すると考えられます。
声優の実演を使ってAIを利用する場合に生じる権利
前述の声優の実演に関するそれぞれの権利の範囲を踏まえた上で、声に関するAIの利用について考えていきます。
学習フェーズと生成フェーズに分けて考える点は、これまでの生成AIの論点と同様です。
声に関するAIの利用の場合は、声優Xが実演した際に生じる「セリフAの著作権」、「声優Xの著作隣接権」、「Xの声に関するパブリシティ権」の3つの権利をそれぞれ考える必要があります。
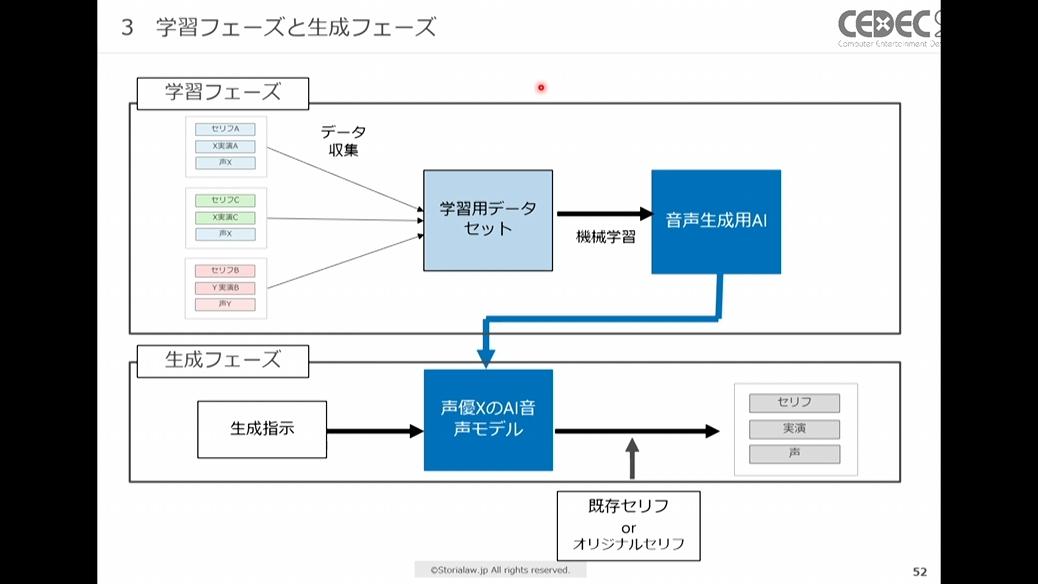
音声生成AIの学習・生成のフロー
学習フェーズ
声優XによるセリフAの実演を使用してAIに学習させた場合、それぞれの権利は次のように考えられます。
- セリフAの著作権:著作権法三十条の四第二号(情報解析のためであれば著作物の複製を許す)により、AI学習への利用は原則適法
- 声優Xの著作隣接権:著作権法第百二条、同三十条の四第二号により、AI学習への利用は原則適法
- 声優Xの声に関するパブリシティ権:著作権法の問題ではない。柿沼氏は、学習に利用するだけであれば「肖像等の顧客吸引力の利用を目的とした使用」にはあたらず適法になると考えている

先に挙げた設例1・2を見ながら、具体的に声優の実演をAI学習に使った場合にどのように判断するか考えます。
【設例】
- 設例1:さまざまなゲーム内の、さまざまな声優による音声を大量に収集し、音声生成用AIを作成したい。無断でそれらの声優音声データを収集してAIの生成(学習)に利用することは可能か
- 設例2:ある特定の声優の音声を再現するために、当該声優の音声を大量に収集し、音声生成用AIを作成したい。無断でそれらの声優音声データを収集してAIの生成(学習)に利用することは可能か
【検討結果】
- 設例1:適法
- 設例2:適法
設例1と設例2の違いは「さまざまなゲーム内のさまざまな声優の音声を収集した」か「特定の声優の音声を収集したか」ということです。
学習モデルを作る段階では、これらの行為は情報解析にあたるためどちらも適法となります。
ただし、生成・利用フェーズでは適法とはなりません。次はこちらの点を詳しく見ていきます。
生成・利用フェーズ
声優の実演を使用した学習モデルを使って生成・利用した場合、生成物のパターンとして以下の3つが考えられます。
- 既存セリフ+実演+声
- オリジナルと同じ声優Xによる既存セリフAの実演(パターン1)
- オリジナルと異なる声優Yによる既存セリフAの実演(パターン2)
- オリジナルセリフ+実演+声
- 声優XによるオリジナルセリフBの実演(パターン3)
- オリジナルと同じ声優Xによる既存セリフAの実演(パターン1)
- オリジナルと異なる声優Yによる既存セリフAの実演(パターン2)
- 声優XによるオリジナルセリフBの実演(パターン3)
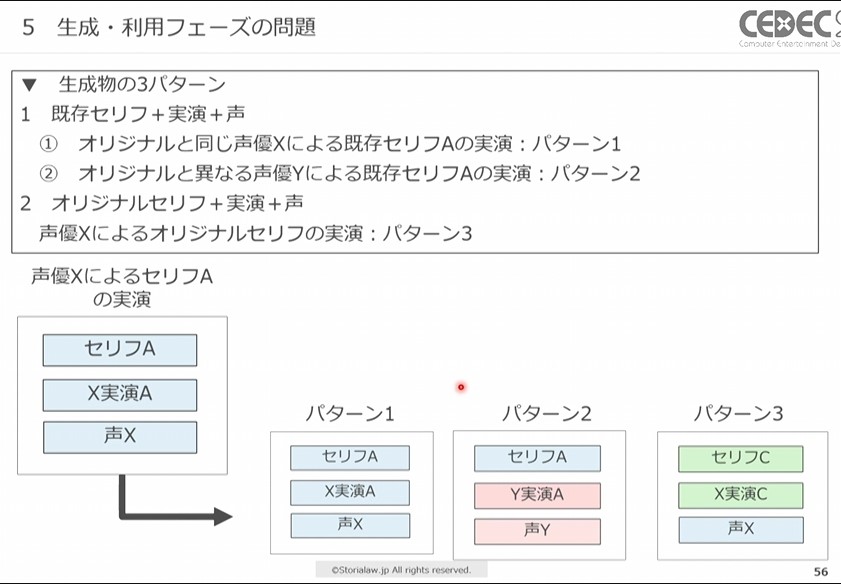
生成AIを使って出力した3つのパターン。パターン1はAI学習で使用したものとまったく同じ、パターン2は異なる声優でセリフが同じ、パターン3は声優が同じで異なるセリフを生成している
【パターン1:オリジナルと同じ声優Xによる既存セリフAの実演】
音声生成AIを利用して、声優Xによる既存セリフAの実演を作成してゲームに利用した場合です。それぞれの権利の侵害状況は以下のようになると考えられます。
(1)セリフAの著作権
既存セリフの無断利用は著作権侵害となります。これは生成AIの問題とは関係ありません。
(2)声優Xの著作隣接権
AIによる実演は、実際に演じられた実演ではないので著作隣接権の侵害にはなりません。これはモノマネに著作隣接権の侵害が発生しないのと同じことです。
(3)声優Xのパブリシティ権
生成された声が当該声優のものと認識できた場合、無断でその音声をゲーム内音声として利用するとパブリシティ権侵害となります。

パターン1「オリジナルと同じ声優Xによる既存セリフAの実演」では、セリフの著作権侵害と声優Xのパブリシティ権侵害が発生
【パターン2:オリジナルと異なる声優Yによる既存セリフAの実演】
音声生成AIを利用して、既存セリフAを、オリジナルとは別の声優Yの声によって実演を作成し、ゲームに利用した場合です。
(1)セリフAの著作権
こちらはパターン1の場合と同様に、既存セリフの無断使用として著作権侵害になります。
(2)声優Yの著作隣接権
声優YによるセリフAの実演は生成AIが生成したもので、もともと存在していた実演ではありません。そのため、声優Yの著作隣接権の侵害にはなりません。
(3)声優Yのパブリシティ権
パターン1の時と同様に、生成された声が別の声優Yのものと認識できる場合、無断でゲーム内音声として利用するとパブリシティ権侵害になります。

パターン2「オリジナルと異なる声優Yによる既存セリフAの実演」では、セリフの著作権侵害と声優Yのパブリシティ権侵害が発生
【パターン3:声優XによるオリジナルセリフBの実演】
音声生成AIを利用して、声優Xの声によるオリジナルのセリフBの実演を生成し、ゲームに利用した場合です。
(1)セリフBの著作権
セリフBはオリジナルのセリフであるため、著作権侵害になりません。
(2)声優Xの著作隣接権
声優XによるセリフBの実演は生成AIが生成したもので、もともと存在していた実演ではありません。そのため、声優Xの著作隣接権の侵害にはなりません。パターン2の場合と同様です。
(3)声優Xのパブリシティ権
パターン1・2の時と同様に、生成された声が声優Xのものと認識できる場合、無断でゲーム内音声として利用するとパブリシティ権侵害になります。
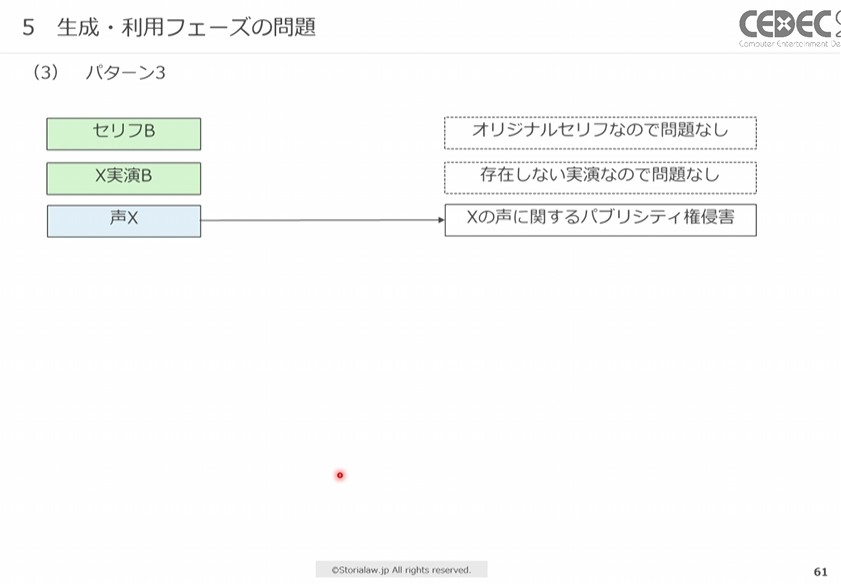
パターン3「声優XによるオリジナルセリフBの実演」では、声優Xのパブリシティ権侵害が発生
以上を踏まえ、設例3について検討します。
【設例】
設例3:作成した音声生成AIを利用して、①特定のゲーム内の特定の声優による特定のセリフ音声と同じ音声を生成すること、または②特定の声優による、それまでに実演されたことのないオリジナルセリフ音声を生成することは可能か
【検討結果】
①については、先述のパターン1の場合と同じため、以下となります。
- セリフの著作権:侵害あり
- 声優Xの著作隣接権:侵害なし
- 声優Xのパブリシティ権:侵害あり
②については先述のパターン3の場合と同じため、以下となります。
- セリフの著作権:侵害なし
- 声優Xの著作隣接権:侵害なし
- 声優Xのパブリシティ権:侵害あり
AIと著作権Q&A
この後は、柿沼氏がよく質問を受ける内容や会場からの質問について検討していきます。
音声生成AIを使用した調整および新たなセリフ生成行為
【設問】
ある声優の収録済みの音声を利用してその声優専用の音声生成AIを作成し、以下の行為を行った場合の権利侵害について
①音声生成AIでイントネーションや抑揚を調整した
②音声生成AIでその声優から同意を取れていないセリフを作成して、作品に利用した
【検討結果】
- ①については、既に収録済みの音声をイントネーションや抑揚の調整するのであれば、声優の黙示の同意があったとみなされる場合が多いと思われる。黙示の同意があるとみなされれば、権利侵害の問題は生じない。
- ②については、声優の同意が取れていないセリフを後からAIで作成して実装することは、黙示の同意があるとは言えず、パブリシティ権侵害に該当すると思われる。
今後、契約にこうした行為を許容する項目を含めたうえで、その分、声優に対価も多めに支払う、という潮流になっていくかもしれないと柿沼氏は述べました。
音声合成AIで声優の仕事はなくなるのか?
【設問】
ある声優の高性能な音声合成AIを生成すれば、その声優の仕事は失われるか。
【検討結果】
- 音声合成の完璧なモデルを作成するまでは適法
- しかし、その音声合成AIを使って、無断でその声優・アーティストの音声を生成・利用することはパブリシティ権侵害となる
- もしも、こうした音声合成AIを使用するのであれば、声優・アーティストはその許諾に際して契約を結び、合理的な対価を支払ってもらえばよい
- ただし、プロダクション契約等で力関係の弱い声優が対等なギャランティ交渉を行えず、すべての権利を安く丸取りされるリスクはあり得る。その場合は独占禁止法などで対応することが想定される
- もしも、こうした音声合成AIを使用するのであれば、声優・アーティストはその許諾に際して契約を結び、合理的な対価を支払ってもらえばよい
今後、既存のどの声優にも似ていない音声を自由に生成・利用できるような音声合成モデルができ、その音声に人気が出てくれば、人間の仕事が代替される可能性があります。これは法律上の問題ではないので、規制をかけるべきかどうかは社会で考えていく必要があるだろう、と柿沼氏は考えを述べました。
降板した声優の代わりを音声生成AIに演じてもらう
【設問】
①シリーズ物のゲームで人気キャラクターを担当していた声優・俳優が、声優等の都合で降板してしまった。以後の作品で音声生成AIを利用して音声を生成・利用することは可能か
②収録後に不足していることが分かったセリフや追加されたセリフを音声生成AIを使って音声を生成・利用することは可能か
③NPCのリアルタイムで柔軟な回答を行うチャットボット的な回答に音声生成AIを利用することは可能か
【検討結果】
- ①②についは、パブリシティ権侵害にあたるため、対価や利用範囲についての協議・合意が必要となる(設例3の回答と同じ)
- ③特定の声優や俳優と類似した声でなければ法的に問題ない。
①②について、今後は降板後の事態に備えて、出演契約時に降板後の音声合成利用の可否も契約に盛り込むことは考えられる、と柿沼氏。
完全にAI発の音声生成モデルができた場合の権利者は?
【設問】
世界中の誰のものでもない音声を生成する音声生成AIを作成した場合、そのAIモデルや生成された声に発生する権利はどうなるのか
【検討結果】
- 音声合成モデルは、パラメーターを組み込んだプログラムであるため、そのプログラムを生成した者に権利が帰属する
- そのAIの利用者が非常に特徴的/魅力的/独創的な音声を生成し、その音声を利用して特定の歌やセリフを生成した場合には、その歌やセリフに対して著作権が発生する可能性はある
- 上記の「音声」に著作権は発生しない
- パブリシティ権は人格権に由来するものなので、AIで生成された音声にパブリシティ権は発生しないと思われる
AI学習防止のための特殊透かしはウイルスになるのか
【会場質問】
AI学習防止のために、画像をAI学習に使うとノイズがのる『Glaze』のようなAI学習段階で誤動作を起こさせるサービスがコンピューターウイルス作成の罪に問われることはあるのか
【回答】
自衛のための手段であって、他人の権利等を侵害する目的ではないため、このケースでウイルス作成罪やその供与罪を問われることはないと思われる。
死後何十年も経過した人を使って生成AIを作ることは?
【会場質問】
死後何十年も経過した声優の実演を使用して音声生成AIを作ることは適法か
【回答】
- パブリシティ権は人格権に由来するものであるため、本人の死後にその権利を訴えることは難しいと思われる。相続対象にもならないだろう
- 国によって扱いが異なるが、現在の日本の法律では死後のパブリシティ権は保護されていないと考えられる
「類似性」の判断はAI登場後も現状のまま?
【会場質問】
「類似性」を判断する明確な判断基準はあるか
【回答】
- 「表現上の本質的な特徴を捉えているか」が類似性判断の鍵となり、これまでの著作権に関連する裁判の判例などが参考となる
- 「作風」「画風」はアイデアであるため似ていても著作権侵害にはならない
- しかし、AIの登場により「作風」の模倣が簡単にできるようになってしまった
- 類似性の判断基準について、これまでと異なる基準で判断したほうがいいのでは、という議論が出始めている
- 現状、類似性を「狭く、厳しく判断する」方向と「広く、緩く判断する」方向の双方で議論されている
- 今後AIの類似性については、これまでとは別の判断基準がなされる可能性はある
- ただし、「類似性」を厳しく判断することは創作活動の幅を狭めることにつながる
- 安易に保護範囲を広げることは人間の創作活動にも悪影響を及ぼす可能性があるため、慎重な議論が必要だろう
- 類似性の判断基準について、これまでと異なる基準で判断したほうがいいのでは、という議論が出始めている
- 現状、類似性を「狭く、厳しく判断する」方向と「広く、緩く判断する」方向の双方で議論されている
- 今後AIの類似性については、これまでとは別の判断基準がなされる可能性はある
- 安易に保護範囲を広げることは人間の創作活動にも悪影響を及ぼす可能性があるため、慎重な議論が必要だろう
生成AIに関して広範囲でさまざまなケースについて語られた本講演をまとめると、以下のようになります。
- 著作権侵害には、類似性・依拠性といった要件や権利制限規定がある
- AI学習時に既存著作物を利用するのは、情報解析とみなされて原則として適法
- 類似著作物が生成された場合、学習/生成/利用の段階で元となった既存著作物を使用しているか、その既存著作物を知っていたかで判断が分かれる
- AI生成物に著作権を発生させるのに最も確実なのは、人間が十分な加筆修正をして人間の創作性を付加すること
- 音声生成AIで生成した音声は、その元となった声優のパブリシティ権侵害に注意
本講演終了後も柿沼氏はチャットに寄せられた質問にask the speakerの場で回答しました。
各種情報や海外事例などを交え、コンピューターエンターテインメント領域で起こりうる事例に即した柿沼氏の講演は、AIとともに進むこれからのゲーム開発の指針となるものでした。
STORIA法律事務所 公式サイトコンピューターエンターテインメント領域における生成AIの利用と法律・知財・契約 - CEDEC2023
ゲーム会社で16年間、マニュアル・コピー・シナリオとライター職を続けて現在フリーライターとして活動中。 ゲーム以外ではパチスロ・アニメ・麻雀などが好きで、パチスロでは他媒体でも記事を執筆しています。 SEO検定1級(全日本SEO協会)、日本語検定 準1級&2級(日本語検定委員会)、DTPエキスパート・マイスター(JAGAT)など。
関連記事


注目記事ランキング
1
2
3
4
5
1
2
3
4
5
1
2
3
4
5
1
2
3
4
5
1
2
3
4
5
連載・特集ピックアップ
西川善司が語る“ゲームの仕組み”の記事をまとめました。
Blenderを初めて使う人に向けたチュートリアル記事。モデル制作からUE5へのインポートまで幅広く解説。
アークライトの野澤 邦仁(のざわ くにひと)氏が、ボードゲームの企画から制作・出展方法まで解説。
ゲーム制作の定番ツールやイベント情報をまとめました。
CEDECで行われた講演のレポートをまとめました。
UNREAL FESTで行われた講演のレポートやインタビューをまとめました。
GDCで行われた講演などのレポートをまとめました。
CEDEC+KYUSHUで行われた講演のレポートやイベントレポートをまとめました。
GAME CREATORS CONFERENCEで行われた講演のレポートをまとめました。
Indie Developers Conferenceで行われた講演のレポートやインタビューをまとめました。
ゲームメーカーズ スクランブルで行われた講演のアーカイブ動画・スライドやレポートなどをまとめました。
東京ゲームショウで展示された作品のプレイレポートをまとめました。
BitSummitで展示された作品のプレイレポートをまとめました。
ゲームダンジョンで展示された作品のプレイレポートをまとめました。
日本と文化が近い中国でゲームを展開するための知見を、LeonaSoftware・グラティークの高橋 玲央奈氏が解説。
インディーゲームパブリッシャーの役割や活動内容などを直接インタビューします。




今日の用語
レンダリング(Rendering)
Xで最新情報をチェック!




