登壇した柴原 考志 氏はゼノブレイド3チームに所属。アセットパイプラインやツールプログラマーの経歴を持ち、本タイトルで初めてJenkinsツールの業務を担当しました。一方、鈴木 成門 氏はR&Dチームに所属し、依頼される形で本タイトルに従事。可視化・自動テストのシステムを担当しています。
2022年7月29日にリリースされ、 「The Game Awards 2022」にもノミネート された『 Xenoblade3(ゼノブレイド3) 』。本作は マップ、物語、成長要素 において開発に必要な 素材が多く 、チームメンバーはデータ更新のたびにサーバーへのアップロードとコンバート、そしてゲーム実行ファイルの更新を行う必要がありました。
本講演では、こうしたデータ更新などの作業を CIツールで自動化する手法 やそれを発展させて プレイそのものを自動化する手法 、そして 自動化で起こりうる問題点 についても解説します。
「Jenkins」でなにができるのか
「 Jenkins 」は 開発プロセスの自動化 などに使われる オープンソースのツール です。本タイトルで利用したのは「 ビルド 」、「 データのコンバート 」、「 データのエラーチェック 」、「 自動テスト 」と多岐にわたりますが、そのいずれでもJenkinsが担ったのはツールを定期実行するというシンプルな役割で、それこそが最も重要なポイントだ と柴原氏は感じたそうです。
本作での具体的な使用プロセスは以下のようなものです。
①ビルドの自動化 プログラマーが新しいソースコードをサーバーにアップロードすると、Jenkinsがそれをビルド、完成した新しい実行ファイルをサーバーにアップロードします。ビルドが失敗すると、ログを含めた通知がチャットツールに送られ、ビルドエラーにプログラマーがすぐに対処できるようにしています。
プログラマーがサーバーにソースをアップしたことをトリガーにJenkinsがビルドし、完成した実行ファイルをサーバーにアップロード
ビルドをJenkinsに定期実行させると、ビルドに関するヒューマンエラーや漏れがなくなってプログラマーは開発に集中できます。また、定期実行がビルドテストも兼ねているため、エラーは漏れなく検知され、解消までの道筋も整えられる と柴原氏はいいます。
②ナビメッシュ更新の自動化 『Xenoblade3(ゼノブレイド3)』には、 目的地までの経路をオープンフィールド上に赤いラインで表示 するナビゲート機能があります。この機能は3Dゲームのルート検索によく使用される ナビメッシュデータ を使って実装されています。本作ではマップの地形データをもとにナビメッシュを事前 生成しているため、 マップの更新が入るとナビメッシュも更新 する必要があり、ここにもJenkinsが用いられています。
マップデザイナーが地形データを更新したら、Jenkinsがコンバートし、できあがったナビメッシュをサーバーにアップロードします。データの流れはビルドの例に似ています。一方で変換時間は地形の編集内容に応じてばらつきがあり 、短ければ1日、長ければ5日に及ぶ という違いがありました。 そこで、ナビメッシュ更新 の定期実行は1日1回実行予約を行い、前の更新が終わり次第、次の更新が開始される 運用にしました。このようなコンバート時間がまちまちの作業を人の手でやろうとすると 、 コンバートがいつ終わるかわからないため夜中まで待機 という事態も起こりかねません。Jenkinsの自動化はこうした場面でも有用であると柴原氏はいいます。
③カットシーン生成の自動化 本作では、合計18時間にも及ぶカットシーンの生成にもJenkinsを使用しています。
デザイナーが作成したアセットデータをJenkinsがコンバートする流れは、ビルドやナビメッシュの更新と同様です。カットシーンの場合は、 背景モデル、キャラクターモデルなどたくさんのリソースが組み込まれている わけで、アニメーションの変更のほかにも、登場モデルのテクスチャの色を変更するだけでもコンバートが必要になります。
そこで、 シーンが依存するアセットをデータベース化 し、どのモデルを更新するとどのカットシーンのコンバートが必要になるのかを検出できるようにしました。
また、カットシーン制作にはたくさんの人が関わっているため、コンバートツールで変換されたカットシーンをスタッフがチェックする際、 各自がゲームを起動して動画を確認することは避けたい です。そこで、 動画の録画から制作管理ツール「 ShotGrid 」にアップロードするツールを呼び出すまでの流れをJenkinsによって自動で行ってもらい、動画のチェックはShotGridからも行える ようにしました。
カットシーンの自動化イメージ(左)と実行に必要なツールや要件(右)
柴原氏は、もしこれらを人の手で行うとカットシーンの素材の多さ、複雑な依存ファイルの更新、コンバート手順の多さなどから ヒューマンエラーが起こりやすくなる ため、本作のカットシーン制作において、 Jenkinsの定期実行はなくてはならないもの だったと、説明しました。
Jenkinsはツールを定期実行するシステムのようなもので、これにより スタッフが開発に集中できるほか、問題の発見も早め、エラーのダメージも抑えられた と柴原氏はまとめました。
メリットだけじゃない自動化、その壁をどう超えるか
これまでJenkinsによる自動化のメリットを話してきた柴原氏ですが、 すべての点において手動よりも良くなっているわけではない といいます。自動化がもたらすメリットの裏には、エラーが発生した際に、誰が、どういう優先度で対応していくのかという問題対応のプロセスが宙に浮くリスクが存在しており 、 考えなしに自動化を押し進めるわけにはいかない と柴原氏は言います。
本作で最終的に行った自動化は70以上。それを実行するにあたっては、いくつかの対策が行われていました。
対策1:エラーはチャットツールに投稿し、見落としを防ぐ エラーが起きていてもそれに 気付かなければ対処のしようがありません 。そこで、 エラーが起きた際に、チャットツールに投稿 しています。その際、データの更新者や エラーの概要・ログ もチャットツールに投稿するようにして、対処にあたるスタッフをサポート しています。情報が多くなりすぎると、かえって分かりにくくもなるため、復旧作業の案内に適切な内容にとどめます。
対策2:状況を俯瞰する エラーの通知は有用ですが、その数が増えてくるとこれが新たな問題になります。
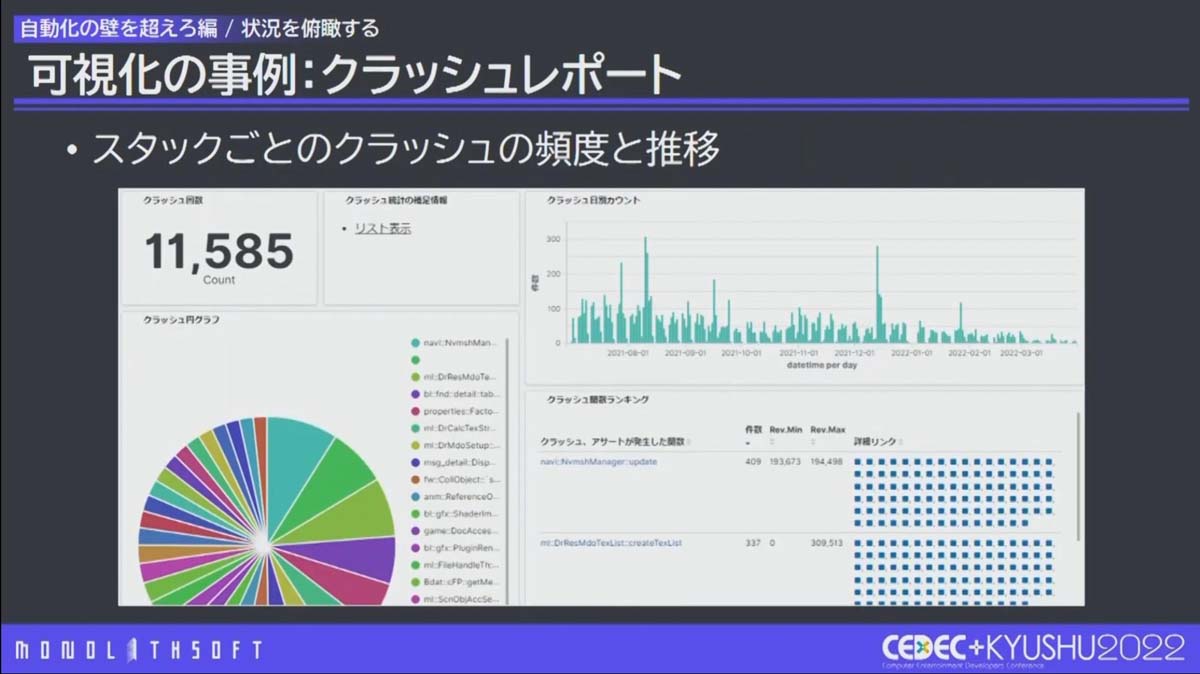
本作のクラッシュレポートシステムは、スタッフの手元でクラッシュが起きた時に、 スクリーンショット、直近のオートセーブ、ログなどをチャットツールに自動投稿 する仕組みです。
しかし、未完成部分が多い段階ではクラッシュレポートも大量に投稿されることがあるため、そういう場合は、問題を解消できるキャパシティに合わせて、 どのクラッシュに対応すべきか判断する必要 があります。
そこで、柴原氏はクラッシュ状況の可視化に着手。 クラッシュ情報をサーバーに送ってスタック毎に集計 できるようにしました。
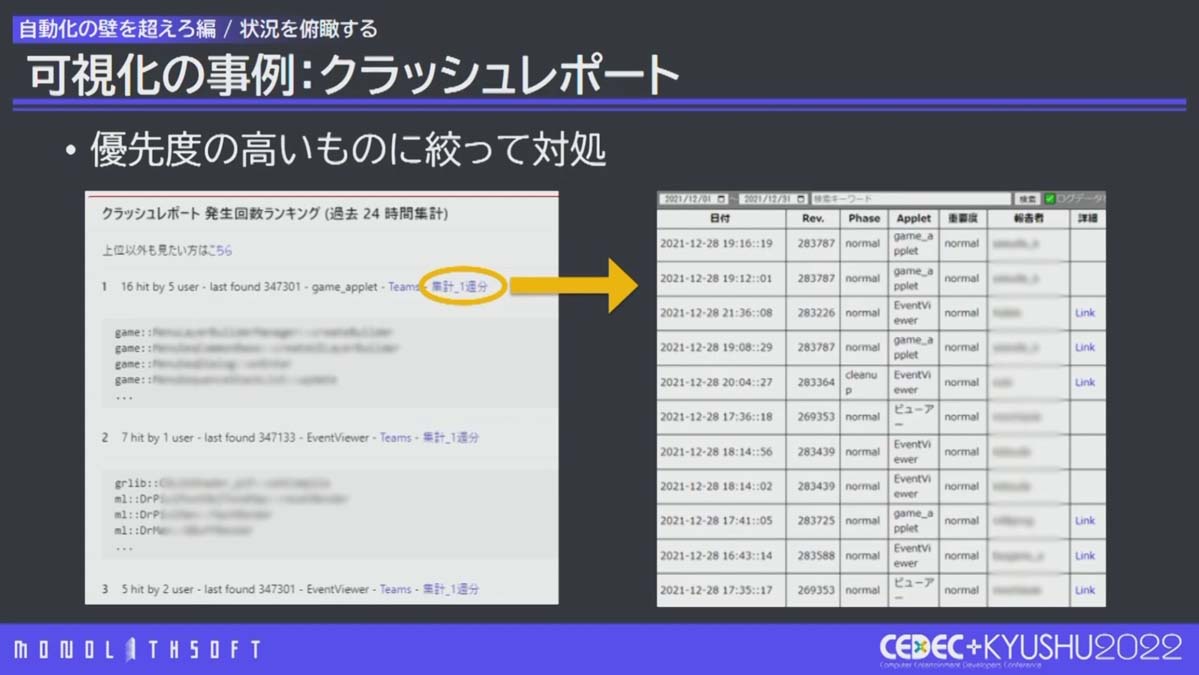
実際の運用としては 1日に数回 、Jenkinsからサーバーに 頻度の高いクラッシュを問い合わせ、チャットツールへ投稿 。その投稿から、 可視化サイトや1週間単位の発生回数履歴へ誘導 しました。これにより、スタッフは 毎日決まった時間に優先度の高い課題に絞って向き合える ようになりました。
チャットツールに投稿された頻度の高いクラッシュレポートから可視化サイトへ誘導
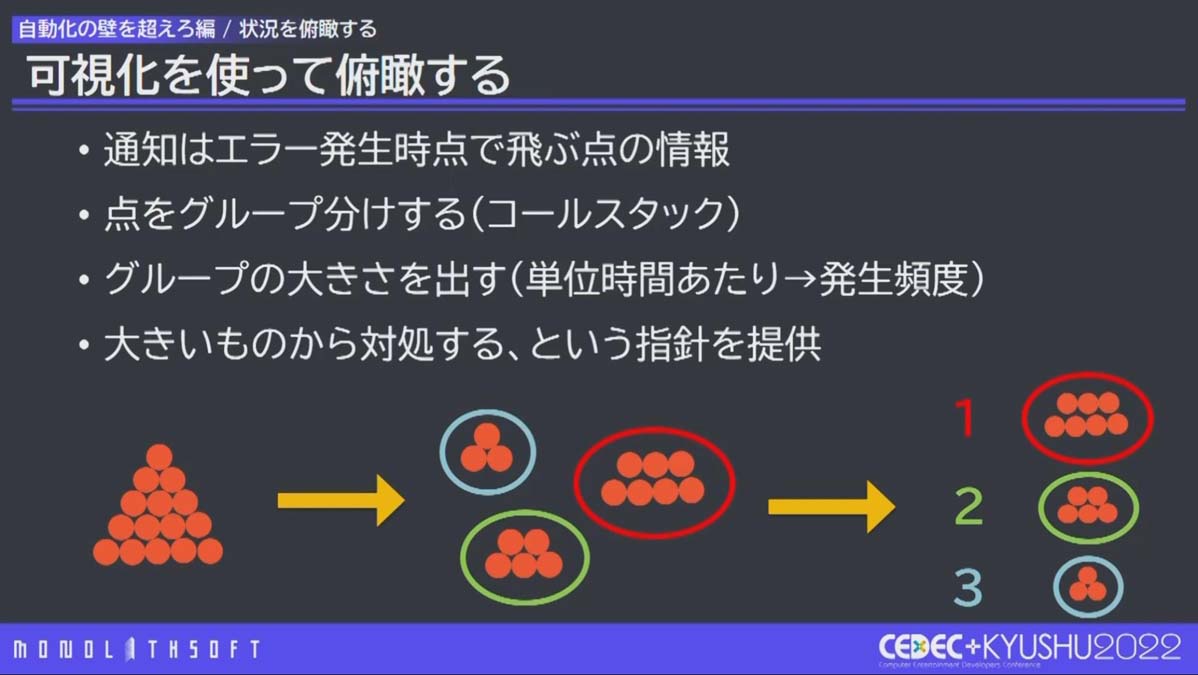
クラッシュの通知は「いま問題が起きた」という 点の情報 にすぎませんが、 点をコールスタックという類似性でまとめ 、単位時間あたりの 発生頻度を求めて、問題対応の優先度にした のが本件のポイントです。
対応する問題を絞ったことによって、効果的に対処が進むようになったほか、すぐに対応が難しいものはクラッシュの回避方法を案内することができるようになったそうです。
増えていくエラー通知を可視化することにより状況を俯瞰。効果的な対応が可能に
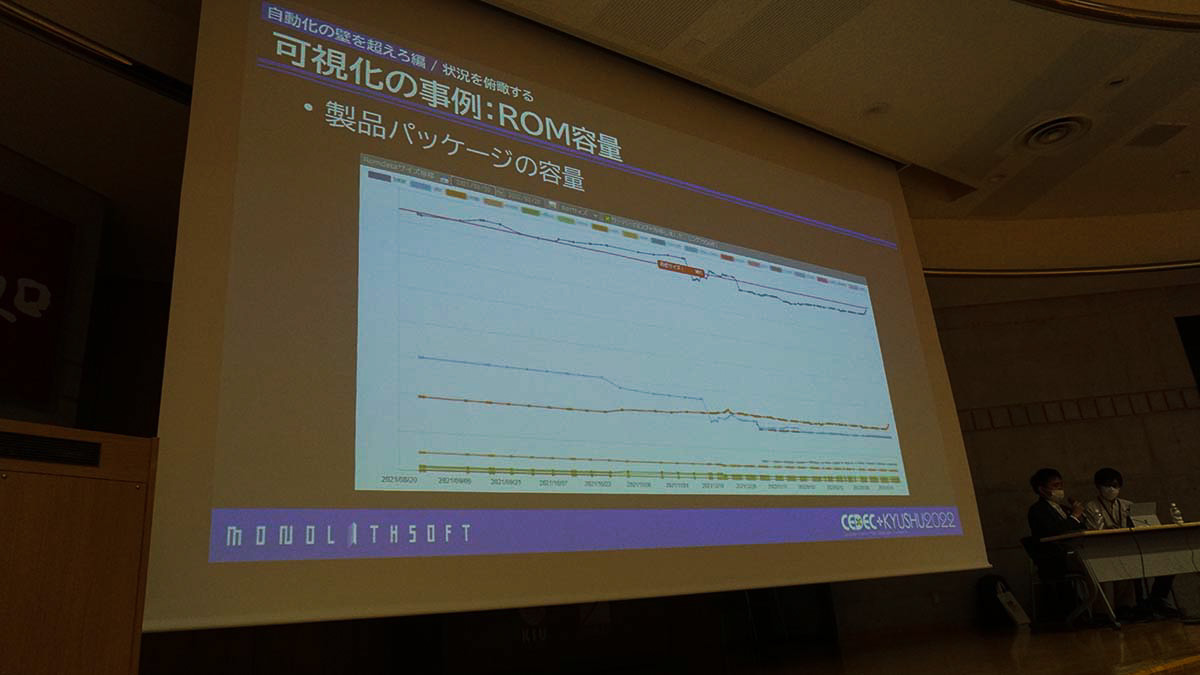
可視化に関しては、エラー情報に限定する必要はないと柴原氏。本作では、 マスターアップの限界容量に対しあとどれくらい容量が残っているのか も一目で判断できるようにしました。X軸に日付を入れた折れ線グラフにすれば、 最適化が前日と比べて効果的かどうかも確認できます 。
容量情報の時間推移を可視化。グラフに大きな変化があったときは、ヒューマンエラーの可能性が示唆される
可視化の実装にはKibanaや独自のWebベースのツールを活用 可視化に使用する技術は過去のCEDECの講演などを参考に以下のものを選択しました。
Elasticsearch :ログの蓄積・検索が可能。自社サーバーにインストールする場合無料 Kibana :Elasticsearchと組み合わせて使用する可視化のためのソフトウェア。自社サーバーにインストールする場合無料 Chart.js :html5ベースで動作するチャート描画ライブラリ。
これらを使用し、次のようなフローを構築しています。
Jenkinsが定期的にジョブを実行、ログをElasticsearchに送信 Elasticsearchに蓄積されたログをKibanaやChart.jsがブラウザで閲覧可能な形に可視化・整形 チャットに投稿されたURLから可視化データを閲覧
通知によってエラーの見落としを防ぎ、蓄積したログの俯瞰によって中長期的な問題に対処する。こうした工夫をほどこすことで、本作は自動化によって生まれるリスクと向き合った、とまとめました。
負荷計測を自動化する
ゲーム開発ではパフォーマンス最適化を行うフェーズがつきもの。しかし、そのための 負荷計測は面倒で時間がかかることが多い と鈴木氏。しかし、負荷計測は自動化が可能な分野です。自動化によって作業者に喜んでもらえるのではないかと考えました。
本作で自動化したのは「 マップの負荷計測 」と「 カットシーン負荷の計測 」でした。この2つは特に 物量が多く、計測にかかる時間も長くなりがち であったため、自動化に取り組んだと、鈴木氏は述べました。
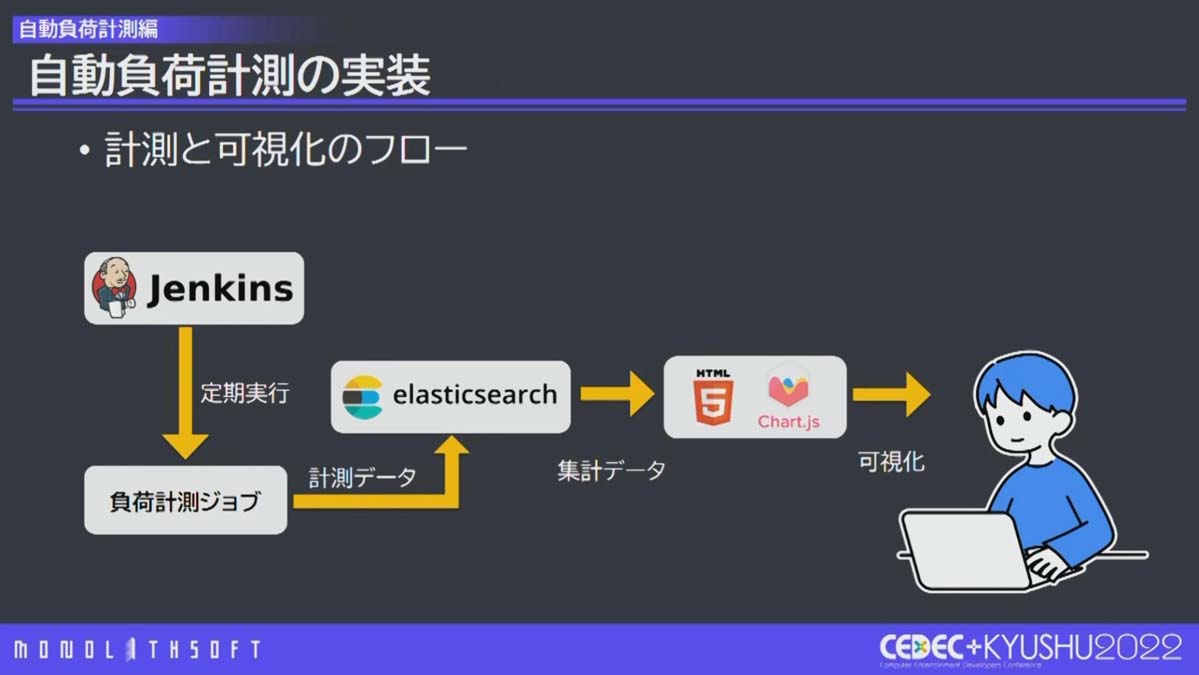
負荷 は、Jenkinsでの計測ツールの 定期実行により計測 するようにしました。また、計測データが多いと、ElasticsearchとChart.jsを使用していた可視化にも一工夫必要です。本作では負荷計測で発生する大量のデータを効率的に閲覧するために Webベースの閲覧ツールを開発 したそうです。
マップ負荷の自動計測 マップ負荷の自動計測は、 マップ全体を5m×5mのグリッドで区切り、各セルにカメラを移動させた際の負荷を計測 しました。このとき、カメラは4方向に向けて、CPU・GPU・エフェクトの各負荷の最大値を計測結果とします。情報として、位置座標・マップIDも記録しました。マップが広大であるため、全マップを計測するのに8時間もの時間が必要でした。
計測した負荷データは、可視化サイト上で ヒートマップ化 し、場所による負荷の高低がわかるようにしました。操作性はGoogle マップを参考に実装。ドラッグ移動やマウスホイールによる拡大・縮小が可能です。講演ではGPU負荷の高低が例として明示されました。
負荷が高い場所は街のような場所でオブジェクトやNPCが多数存在する。逆に負荷が低いのは草原のような場所でオブジェクトやNPCが少ない
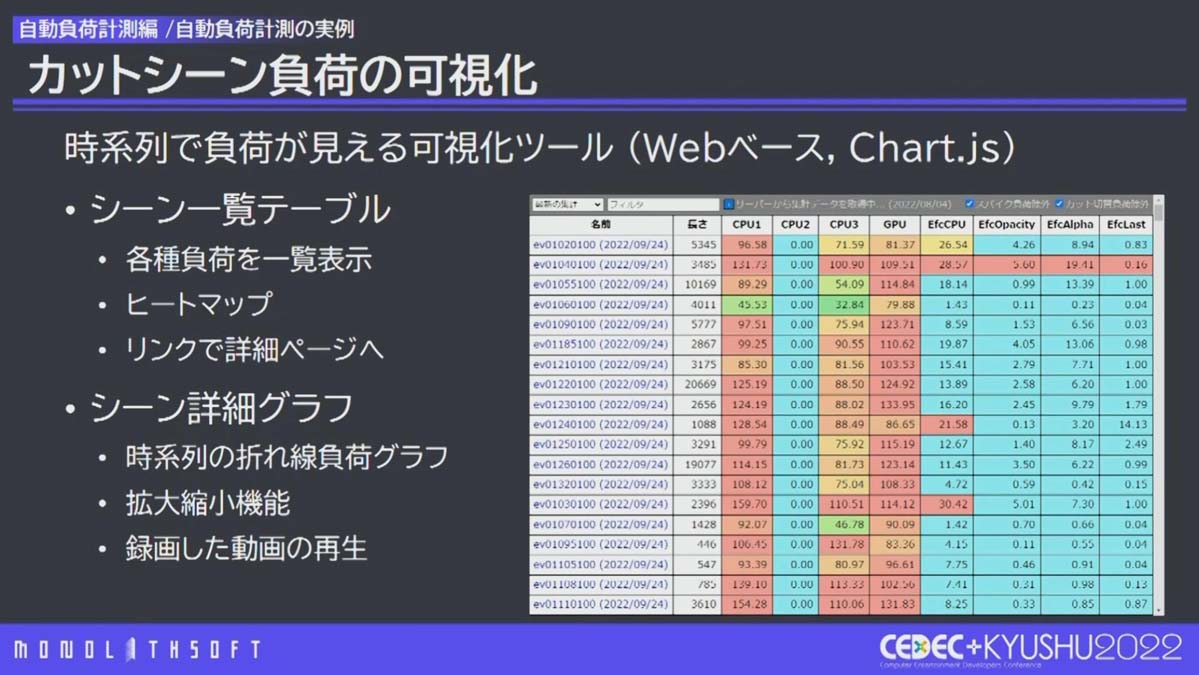
カットシーン負荷の計測 カットシーン負荷の計測は、 シーン開始から終了までの毎フレームの負荷を計測 しました。マップと同様にCPU・GPU・エフェクトの負荷を計測し、加えて、フレーム番号・カット番号・カット内フレーム番号を記録しています。本作のカットシーンは数が多く、計測にはカットシーンの実際の時間分かかるため、計測対象を全て計測すると18時間にもおよびます。これでは計測マシン1台では夜間に全カットシーンを計測できません。そこで、 カットシーンのリストを2つに分けて2日かけて全カットシーンを計測 できるようにしています。
カットシーンの負荷はグラフ化し、時系列で見ることができます。また、計測時に録画した動画も可視化サイトから確認が可能です。
シーン一覧テーブル(左)のリンクをクリックすると詳細ページ(右)を表示。詳細ページは本作のために作成したもので、時系列で負荷が、グラフにカーソルを当てると、実際の負荷の数値やカットシーンのカット番号・フレーム番号が確認できる
負荷計測の可視化フローは、 自動化の可視化フローと似ています 。Jenkinsが負荷計測ジョブを定期的に実行し、計測データを取得します。取得した計測データはElasticsearchに送られます。可視化はユーザーが任意で行えるようにしました。
これらのシステムにより、自動負荷計測・可視化・可視化に基づいての調整という最適化のサイクル構築に成功したと鈴木氏はいいます。これは、 副次的に自動テストの役割も果たしました 。定期的な自動負荷計測でクラッシュした場合にエラーを通知するようにした結果、品質向上にもつながったのです。
Pythonで自動テストの基盤システムを構築
自動テストは『ゼノブレイド2』の頃から C++を使って簡易的なツールを作っていました 。本作ではこれを発展させました。
そろそろツールのテストができる、という段階に至ったのは 忙しい開発中盤期 。この状況でプログラマーが自動テストのチャレンジを始めるには テストを作る負担を減らす必要があった といいます。そこで、テストの開発環境を工夫して状況を打開することを狙いました。 開発環境の打開に必要な要件 は次の2点です。
試行錯誤を重ねやすく イテレーションを早く回せる 手の空いているプログラマーが、自分の担当範囲を超えて自動テストを開発 できる
この要件を満たす環境として、スクリプト言語である Pythonを採用 して自動テストを行うことにしました。
自動テストを行うためには、 Pythonとゲーム本体を連動させる ことが必要です。具体的には、プレイヤーの位置、ステータス情報、エネミー分布などのゲームの内部情報取得が必要です。また、 Pythonからゲームの操作ができる ことも必要です。そのため、テストプレイ用の仮想パッドでの操作やデバッグコマンドでゲーム機能を操作できることが要件に挙げられました。そして、 リリース時にこれらの機能が残らないようにする ことも必要です。本体に機能が残ることは 外部からアクセスが可能になることを意味する ため、必ず防ぐ必要があると鈴木氏は強調しました。
連動させる手段は、本体とテストスクリプトを通信でつなぐRemote Procedure Call (以下RPC )方式を採用しました。本作では通信フォーマットにMessagePackを使い、独自のRPCプロトコルを作りました。
RPCの利点は、 Python実行環境をゲーム本体に組み込む必要がない ほか、 ゲーム本体の動作への影響が少なく、スクリプトの差し替えが容易 である点にあります。
その他、開発環境であるPCと実機であるNintendo Switchの違いも考慮する必要がありました。本作では、同社に用意されている共通の通信基盤によって環境の違いを吸収しています。
RPC Server、RPC Clientそれぞれの実装は以下のようになります。
呼び出し先のRPC Serverの実装 RPC Serverは ゲーム本体側に実装 します。RPCのリクエストを受けたら、対象の機能を実行し、結果の返り値をRPC Client側に返します。C++のテンプレートライブラリが付属しているため、メンバ関数、ラムダ式を少ないコードでバインド可能です。
ラムダ式も少ないコードでバインド。この例では「print」と「add」というメソッドを可変引数テンプレートを使いラムダ式で登録している。RPCに必要なシグネチャはコンパイル時に取得
呼び出し元のRPC Clientの実装 RPC Clientは、 テストスクリプト側がimportするpydモジュール で、実装はC++で行われています。RPCリクエストをサーバーに送り、実行を待ち、結果を受け取ってPythonの処理を実行するのがおもな機能です。Vec2・Vec3・Vec4・Col4といったよく使う型はビルトイン型として定義し、Python側でも同じメソッドが使えるようにしてあります。
呼び出し時の型チェックはしっかり行い、呼び出し先のC++の関数で型の不一致によるエラーが起こるのを避けます。
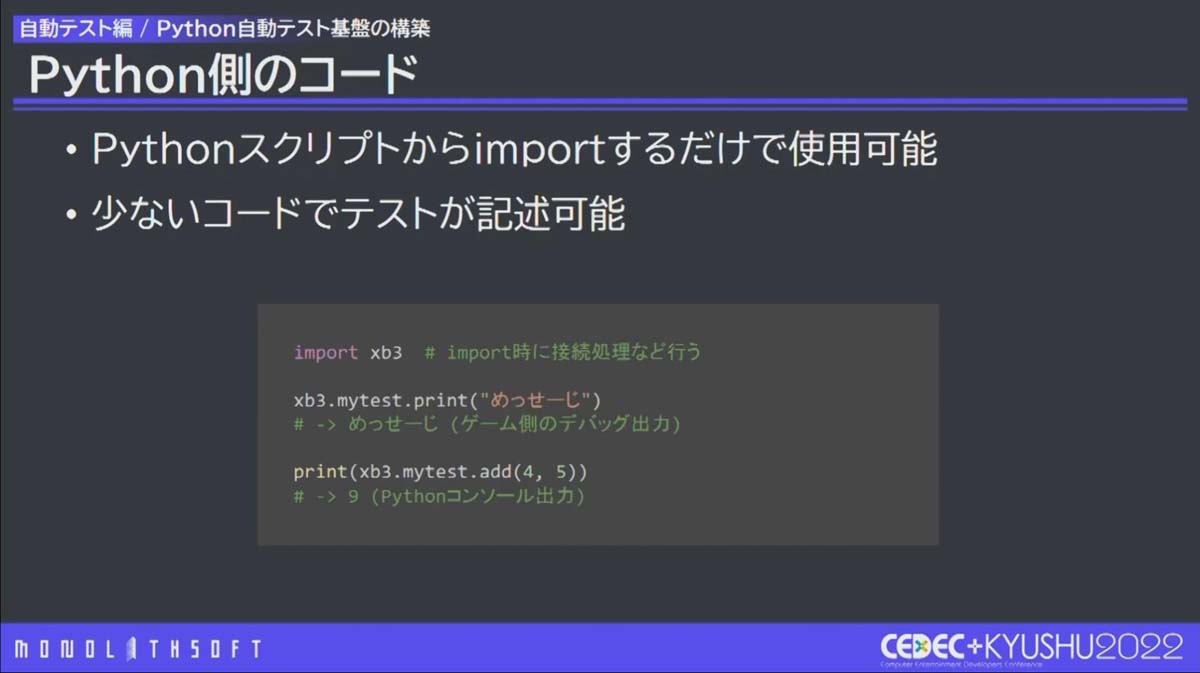
Python側ではスクリプトからimportするだけで使用可能です。
Python側のコードサンプル。C++側で定義したprintとaddの関数を呼び出している
テスト実行フロー テスト実行の際は、まずゲームプログラムを先に実行します。次にテストスクリプトを起動し、RPC Clientをimportします。すると、ゲームプログラムのRPC Serverに接続し、テストスクリプトが関数リストを取得します。これでゲーム本体の関数を呼び出す準備ができたので、テストスクリプトを開始します。
これらの処理は同期的に行われるため、テスト側は特に何も考えずにテストコードを書き始めることができます。 ただし、ゲーム本体が起動していないと、手元でエラーが発生するので注意が必要です。
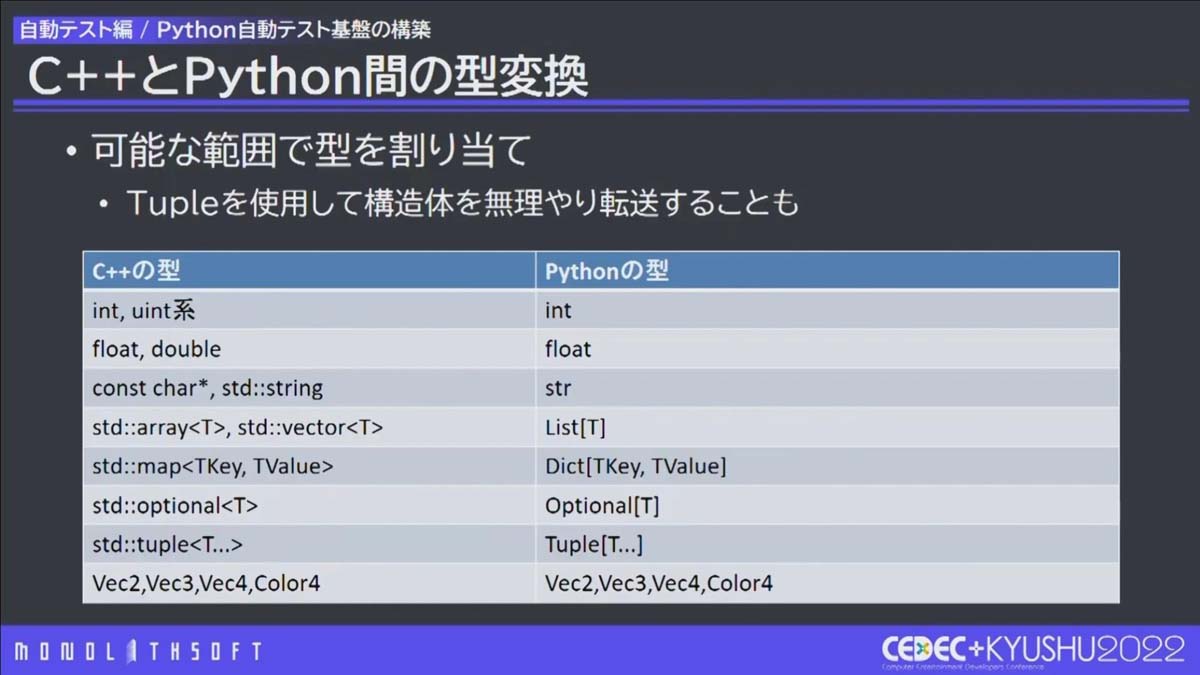
C++とPythonの型変換 C++とPythonの型変換は可能な限り行いました。PythonのオブジェクトはC++に渡せないため、Tupleを使って構造体に変換してC++に渡しています。また、Vec2などビルトイン型が使えるものはそれを使いました。
今回、独自のRPCプロトコルを使用したのはこのような言語間の型変換を柔軟に行えるようにしたかったからだといいます。
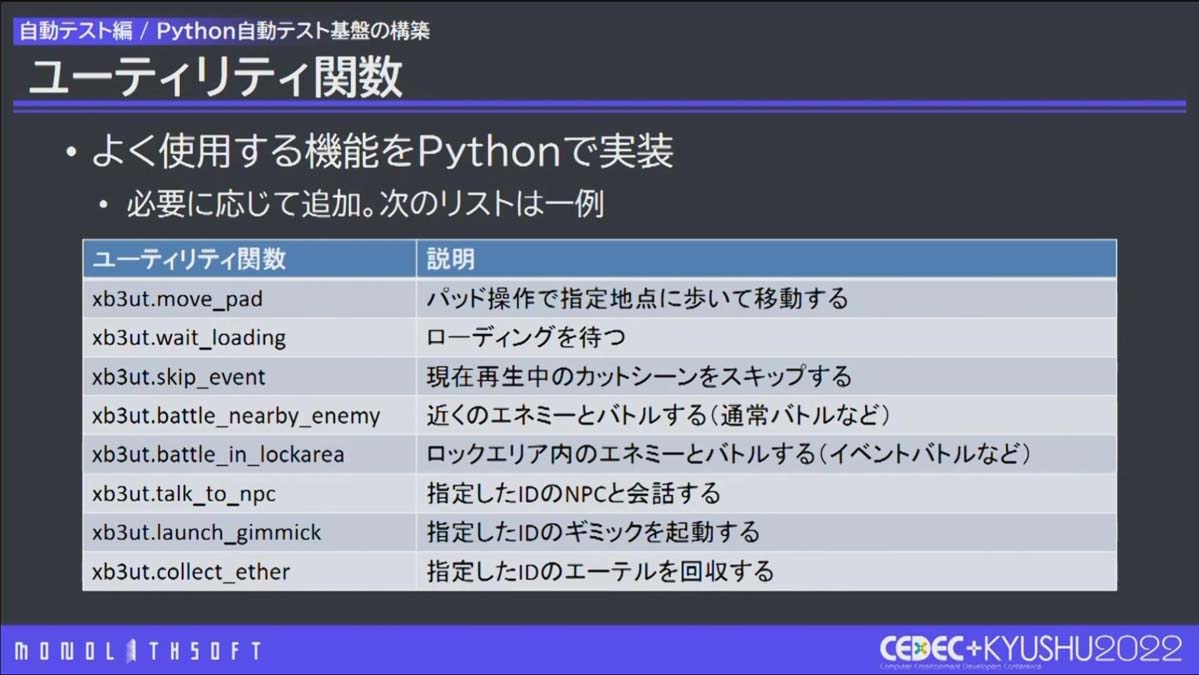
ゲーム側の実装API ゲーム側に実装したAPIは、ゲーム内の機能にアクセスするためのもので、これを充実させたことが、担当範囲外の自動テスト開発のハードルを下げることにつながりました。数が増えてもいいようにモジュール分けをしています。テスト実施時に必要なものを増やしていきました。
Python側に実装したユーティリティ関数 Python側で実装したユーティリティ関数もテスト実施時に必要なものを増やしていきました。これは指定したIDのNPCと会話するなどのゲーム内でよく使うまとまった操作を関数にしています。
これらの設定により、Pythonによる自動テスト基盤を使ってゲーム本体の外にテストコードを置きながらテストコードが書けるようになりました。
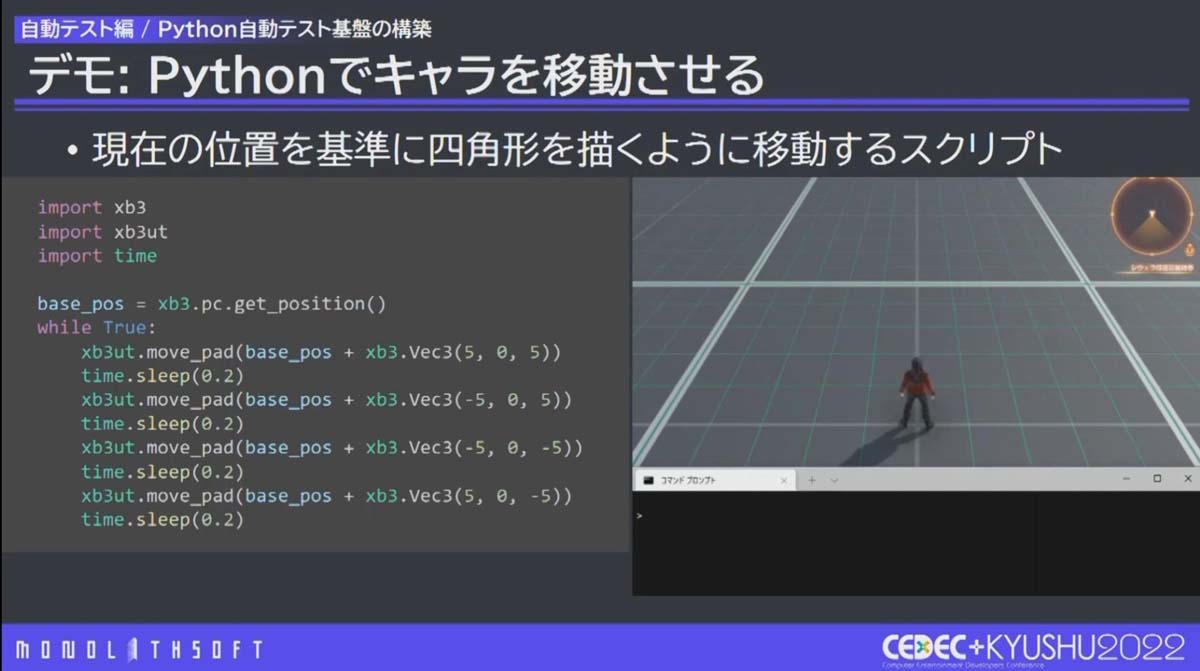
キャラクターが現在位置から四角形を描くように移動するサンプルスクリプト
Pythonは開発用PCで動作するため、実機の影響を抑えられるほか、Pythonの拡張 モジュールを使ってテスト環境を強化することができます。
「今回はできなかったが、機械学習技術を活用していくことも可能だろう」と鈴木氏。
また、 テストコードを本体外に置けたことにより、ゲーム本体側のビルドが不要になり、自動テスト実装の試行錯誤が気軽に行えた こともテスト作成のうえで効率化につながったそうです。
プレイログ、リプレイシステムの実装でパッドの操作を再現可能に これまでの実装で自動テストは作成可能ですが、これではプレイヤーキャラクターを歩かせるためにその都度 スクリプトを書かなくてはなりません 。本作の広大なフィールドに対応するのは困難であるといえます。そこで、 プレイログとリプレイシステム が登場します。
プレイログは、プレイヤーの移動やアクション操作を記憶したログファイルのようなものです。そして、リプレイシステムはプレイログを読み込んでリプレイを行うものです。これは セガがCEDEC2020で発表 した「どこでもリプレイシステム」を参考にして開発したそうです。
これらを開発したのは自動テスト作成のワークフローを改善するためです。テスト実装にかけられる人員が限られるなか、 パッドによるプレイを記録して再現できればテスト作成が楽になる と考えたのです。また、 バグが起きた状況をプログラマーがリプレイシステムを使って自動で再現 できればデバッグフローも効率化すると考えました。さらに、 モニタープレイ中のプレイログを可視化 できればゲームプレイの改善にも役立てられそうです。
プレイログの出力は、 ゲーム本体側に手を入れて実装 しました。1行に1つのJSONが出力されるNDJSON形式を使って、 定期的に出力している移動の軌跡や宝箱を開けたりNPCと会話するなどの各種アクションログを出力します。
実際に出力されたプレイログ。移動の軌跡を中心に、ジャンプや宝箱を開けるといったプレイもログから読み取れる
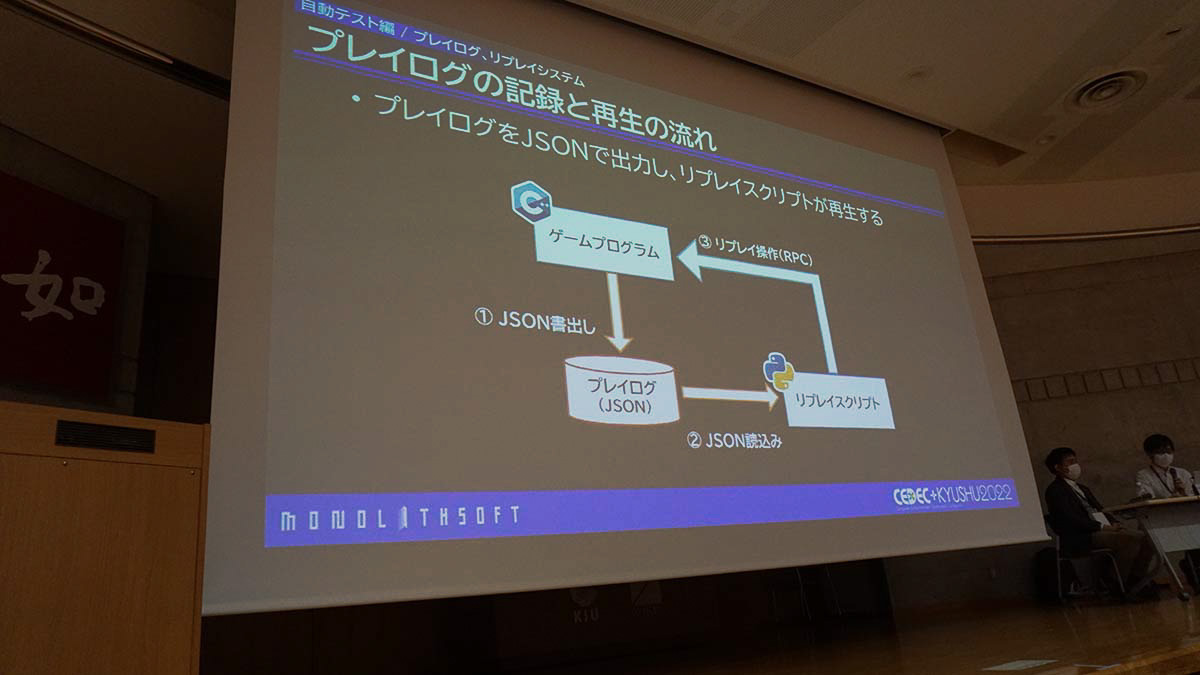
プレイログの記録と再生の流れ プレイログは次のようにして記録と再生を行います。
ゲームを実機でプレイし、プレイログのJSONを書き出す Pythonのリプレイスクリプトを使って、出力されたJSONのログを読み込む Pythonテスト基盤のRPCを使って、リプレイ操作を行う
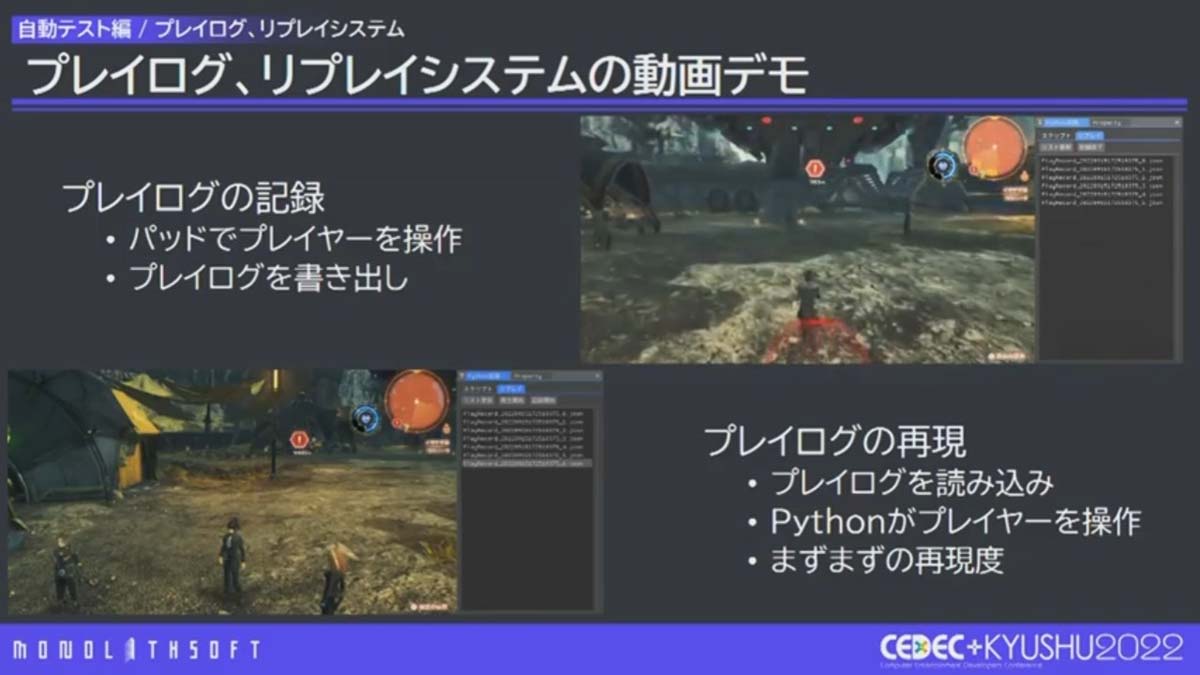
講演ではプレイログ、リプレイシステムの動画デモも公開されました。
プレイ画面(右上)。キャラクター後方の赤い球体はプレイログを出力したことを表す
リプレイシステム実行中(左下)。これから移動する場所に赤い球体が表示されている点がプレイ画面とは異なる
プレイログとリプレイシステムを開発した結果、 フィールドアクションのリプレイがある程度可能 となり、自動テストのワークフロー改善に寄与できたと述べる一方、再現できないアクションもあったことは今後の課題だと鈴木氏は締めくくりました。
自動通しプレイでセーブデータの更新を自動化 構築したPythonの自動テスト基盤を活用して作ったのが「 自動通しプレイ 」です。これは、ゲームの最初からエンディングまでのメインストーリーを自動で進めるもので、柴原氏は自動通しプレイにいくつかの目標と優先度を定めました。実行時にさまざまな異常も検知してくれる完璧なテストを作りたいという誘惑を断つ ためにこれらの目標を定めたそうです。
最も優先したのは ストーリー中の進行度に応じた セーブデータ更新 でした。本作はクリアまでの時間がかかるため、こうしたセーブデータが有るか無いかは開発効率に影響を与えます。また、セーブデータに更新があったにもかかわらず古いセーブデータで確認をしてしまうことで起きるトラブルもセーブデータ更新の自動化で防ぐことにしました。
クラッシュ検知、進行不能検知は第2、第3の優先度 としました。人間のチェックほどの精度を目指すのではなく、 自動通しプレイがクラッシュすることなく正常に通せる程度の精度を目指した といいます。
自動通しプレイに必要なセーブデータの更新については、Pythonからセーブの指示を出すことはせず、ゲーム内のオートセーブ機能で生成されるものを利用 しています。また、目的地への移動や対象の人物との会話、装置へのアクセスにはリプレイシステム を使用しました。目標到達地点への微妙なズレはあったものの、スクリプトで微調整できる程度の結果だったそうです。バトルは基本的にゲーム内のオートバトル を利用しましたが、いくつか調整が必要でした。自動通しプレイの総時間が長時間化してきたため、味方のHPが0にならないようにしたり、バトルから一定時間が経過したら敵を強制討伐するデバッグ機能も利用しました。一方、終盤まで調整が入る可能性があるUI操作 (装備変更など)は、あえて 一つ一つの動作をコマンドで記載 しています。チュートリアル も同様の事情があるため、自動通しプレイ中では発生しない ように調整しました。
割り切った要素もありますが、セーブデータを更新することを一番の目的としていたので、こういった判断ができたと柴原氏は語ります。
こうした自動通しプレイに必要な要素はJenkinsで次のように実行しました。
サーバーから最新のゲームデータと自動通しプレイのスクリプトを取得し、それらを使って自動テストを動かします。そして、テストの成果物として生成されたセーブデータをサーバーにアップし、エラー情報を含めた実行結果をチャットツールに投稿します。
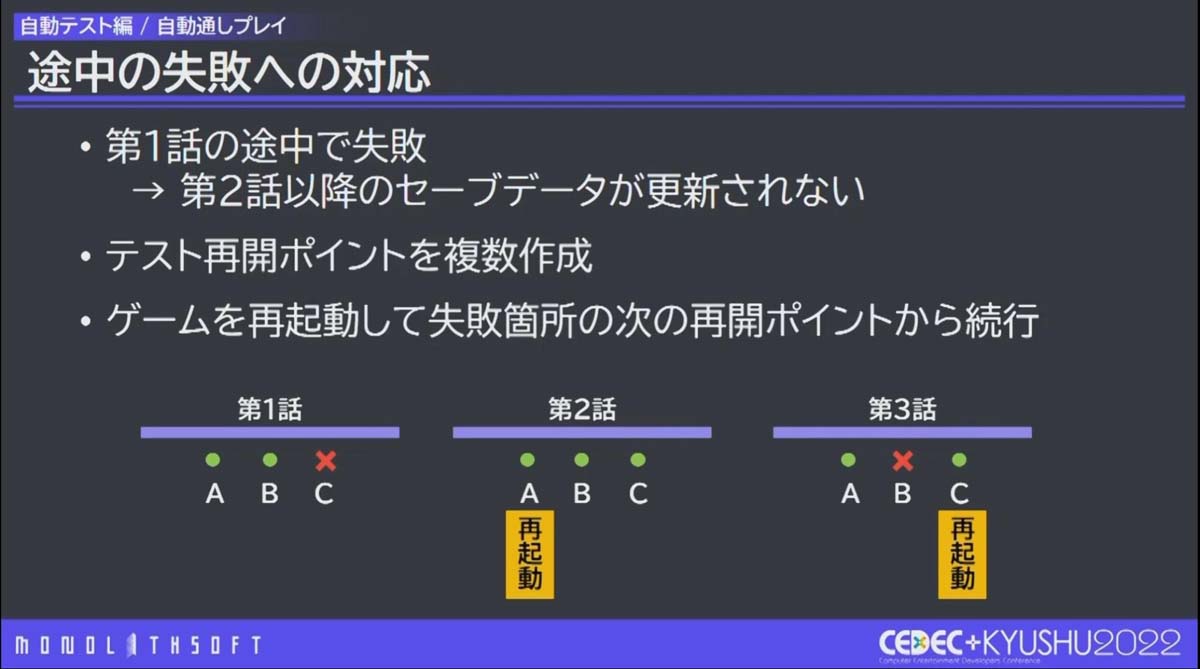
さらに、自動通しプレイでは、この基本のフローに、テストが途中で失敗した時の対策を追加する必要がありました。例えば、第1話の途中でエラーが起きてテストが中断された時、このままでは、第2話以降のセーブデータは更新されないことになるからです。
そこで、 メインストーリー内にテスト再開ポイントを設けて、エラー発生時にもゲームが再起動して再開ポイントから進む ことができるようにしました。テストだけでなく、ゲームの起動処理もPythonで処理しているため自動テスト基盤は扱いやすかったといいます。
第1話のCパートで失敗した場合は第2話Aパートから、第3話のBパートで失敗した場合は第3話Cパートからセーブデータの更新処理が再開される
自動テストを毎晩1回動かすことでセーブデータは継続して更新 できるようになり、デバッグ開始時点での停止バグも過去作より少なくなった と、柴原氏は成果を語りました。また、デバッグ期間に入ってからも、バグ対応によって別のバグが発生するエンバグの発生を検知 できたこともあったそうです。
しかし、クラッシュ検知や進行不能検知は 想定以上のコストがかかった といいます。
たとえば、 クラッシュ検知では自動テストのみクラッシュするのか、条件によっては手動テストでも起こるのか追加の調査が必要 となりました。進行不能検知では移動目標の座標変更によってプレイの正解が変わっ たケースで誤検知が起こり、自動テスト側の修正が都度必要になりました。こうして、 検知された問題を一つ一つ確認・判断をする作業が運用コストとして膨らんでいった のです。
最終的には、 状況の俯瞰のための可視化の発想を用いて、 複数台のマシンで自動テストを実施し、再現率の高い問題に優先的に対処する という方法に切り替えました。テストの開発者としてテストの信頼性を高めたい気持ちが強かったものの、マスターアップが近づくにつれてテストでの失敗そのものが減っていったことを考慮すると、 ゲームが未完成のうちにテストの安定化にコストを割きすぎても仕方がない と学んだと柴原氏は所感を述べました。
自動化は実施するタイミングと内容の見定めが運用の鍵
最後に、柴原氏は近年のゲームは、自動化なしには完成が困難なほど複雑化しているとし、自動化や自動化のスケーリングの技術は 選択肢として持っておきたいものになったと語りました。また、自動化運用のコストは 開発が不安定なフェーズでは大きくなる という懸念点を挙げ、 自動化についていつからどのくらいの規模で取り組むべきか、そして出現した課題にどのように優先順位を当てて対応するのか、計画性を持つ 重要性について話しました。
最後にこの自動化の取り組みに当たり、他社の情報公開についての謝辞と自動化を支えたメンバー構成が述べられました。Jenkinsの担当は2名、可視化・自動計測・自動テストは3名でシステム・プレイログ・運用の役割を分担しました。他に自動テストの量産にあたっては数名のプログラマーが参加しました。自動化は他業務を兼任しながら進めていったそうで「この事例をもとに、 兼任でも自動化や可視化ができると多くの人に思ってもらえたらうれしい 」と柴原氏は語りました。
また柴原氏は今後、より大規模なタイトルでの運用に備えて、検出した問題のチケット管理による管理の効率化、カバーできる範囲を広げるためにプログラマー以外のスタッフもテスト作成に関わることができるようにしたいそうです。
開発環境の改善によってゲームの品質向上に貢献したいという同じ志を持つ方々の参考にしてほしいと述べて本講演を終えました。
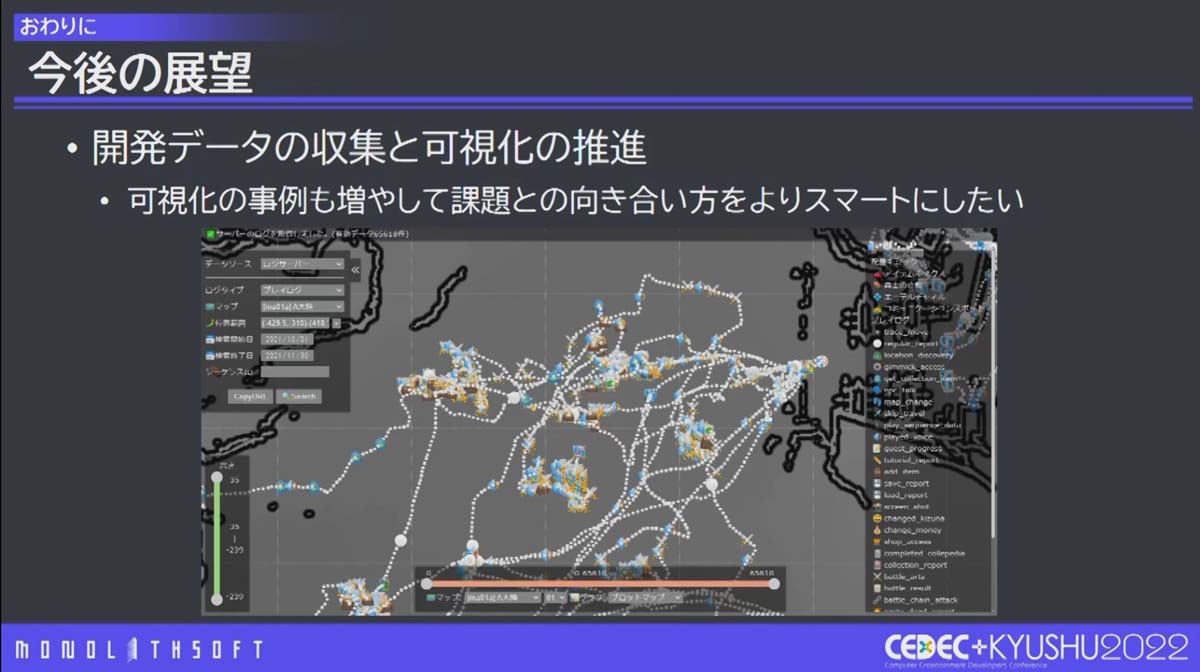
開発スタッフのプレイログをウェブツール上にマッピングしたもの。このようなデータ収集や可視化をゲームの改善に活用する事例も次回作では増やしたいとのこと
『Xenoblade3(ゼノブレイド3)』公式サイト 『ゼノブレイド3でのCIツールを使った自動化の取り組み』 - CEDEC+KYUSHU 2022
© Nintendo / MONOLITHSOFT
5歳の頃、実家喫茶店のテーブル筐体に触れてゲームライフが始まる。2000年代にノベルゲーム開発を行い、異業種からゲーム業界に。ゲームメディアで記事執筆を行いながらゲーム開発にも従事する。