
国内最大規模のゲーム業界カンファレンス「CEDEC2022」が、2022年8月23日(火)から8月25日(木)までの日程で開催されました。最終日となる8月25日には、Cygames開発運営支援 ゲームエンジニア 立福 寛氏が登壇し、「AIによる自然言語処理を活用したゲームシナリオの誤字検出への取り組み」と題した講演が行われました。BERTを用いた誤字検出機能の開発や、運用するにあたっての工夫やアイデアなどについて語った本講演をレポートします。

AIによる自然言語処理を活用したゲームシナリオ制作術――誤字検出だけでなく訂正候補の提示まで行うCygamesのシナリオ執筆ツールの内側を解説【CEDEC2022】




TEXT / じく
EDIT / 酒井 理恵、神山 大輝


登壇したのは、複数のゲーム会社でコンテンツパイプラインの構築、モバイルゲームの開発・運営などに携わった立福 寛氏。株式会社Cygamesに入社したのは2018年10月で、その後2019年後半からAIの社内導入に取り組み、CEDEC2021では「ゲーム制作効率化のためのAIによる画像認識・自然言語処理への取り組み」という講演を行っています。
内製シナリオ執筆ツールの開発状況
Cygamesには、社内のシナリオライターや監修者が使用する内製のシナリオ執筆ツールがあります。本ツールはシナリオ作成ワークフロー全般をサポートするWebアプリとして開発されており、ストーリーのアイデア作成から対象のキャラ音声の再生確認といった機能が提供されているほか、シナリオ自体の執筆や監修、台本出力も可能です。
Cygames Tech Conferenceで公開されたシナリオ作成全般をサポートするWebアプリの事例。『ウマ娘 プリティーダービーの大規模シナリオ制作を効率化するソリューション~社内Webアプリ開発運用事例~』
最初に実装した誤字検出機能
ツールのユーザーからのフィードバックとして「シナリオの誤字をAIで見つけてほしい」という要望が挙がったことから、誤字の位置を求めることができる最初の誤字検出機能が開発されました。

最初の誤字検出機能。漢字の間違いや余計な文字、補助動詞の表記ミスを検知する
最初の誤字検出機能の仕組みは、文章を「誤字なし」「誤字あり」に分類し、「誤字あり」の文章を形態素解析の上で単語の出現順を求め、誤字の位置を決定するというもの。
形態素解析は、人間が日常的に使用している自然言語を意味を持つ最小単位にまで分解し、品詞や意味などを判別することです。例えば、「今日はいい天気です」という文章ならば「今日/は/いい/天気/です」に分解します。
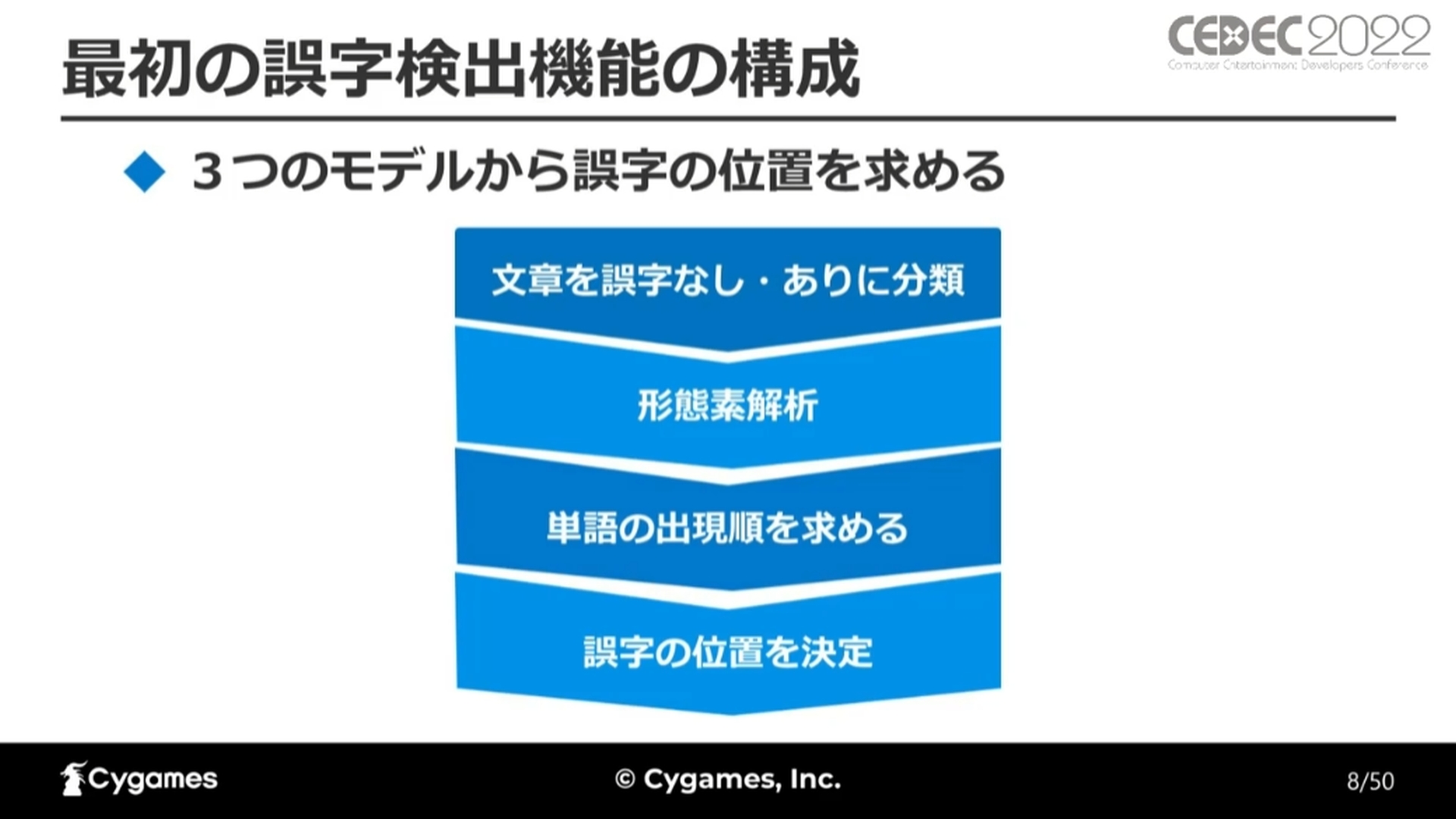
最初の誤字検出機能の構成
ここで紹介された文章分類や単語ごとの出現順を求めるモデルなどについては、CEDEC2021講演「ゲーム制作効率化のためのAIによる画像認識・自然言語処理への取り組み」でも解説されており、詳細は同社のテックブログに掲載されています。
【CEDEC 2021 フォローアップ】ゲーム制作効率化のためのAIによる画像認識・自然言語処理への取り組みBERTを使った新しい誤字検出機能の開発
最初の誤字検出機能は一定の精度で実用できていましたが、「検出された結果が誤字の位置のみで、それが誤検出(誤字としての検出が間違い)のときに分かりにくい」「誤字検出機能を利用するユーザーが限られている」という課題も出てきました。
以前のバージョンの課題だった「誤検出のときに分かりにくい」場合の解決策として、新たに「訂正候補を出す」機能が策定されました。
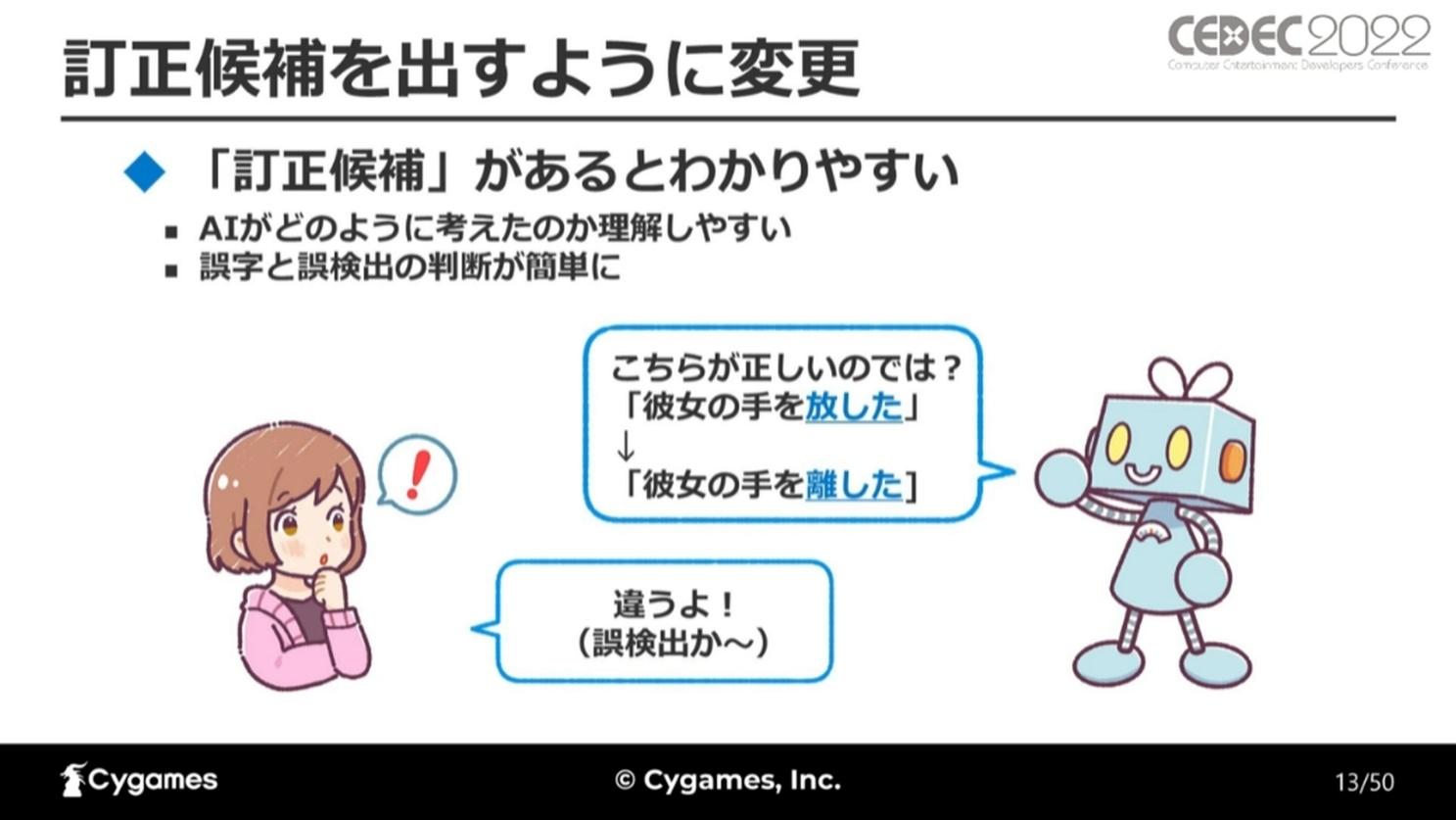
「彼女の手を放した」を検出されただけでは誤字なのか誤検出なのか分かりにくいが、訂正候補として「彼女の手を離した」が提示されることで、この検出は誤検出であると判断できる
新たな誤字検出機能の開発に用いられたのが、BERTを使った文章校正です。BERTは2018年10月にGoogleから発表された自然言語処理モデルで、翻訳、文書分類、質問応答などのタスクで、当時の最高スコアを達成しています。
現在はさらに新しい自然言語処理モデルが登場しているにも関わらずBERTを採用した理由について、立福氏は「前回使用していて慣れており、他の言語処理モデルよりも圧倒的にドキュメントが充実しているため」としています。

BERTは誤字を含む文章を入力して、誤字を訂正した文章との差をなくすように学習します。最終的に、誤字を含む文章を入力すると、誤字の無い文章を出力するようになります。ここから、誤字の位置と訂正候補を取得することができます。
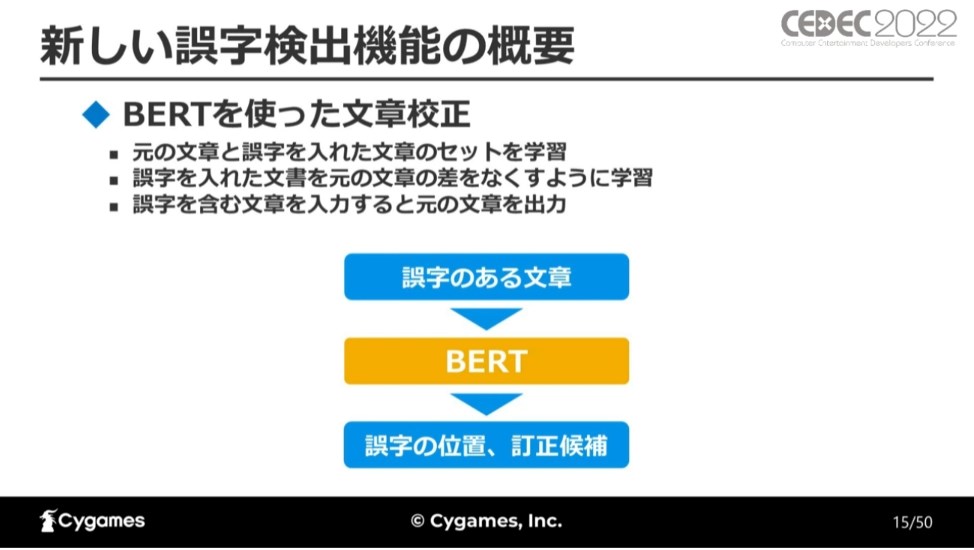
BERTの学習方法
BERTの学習はテキストの穴埋め問題と言えます。これは入力されたトークン(形態素解析された要素)の一部をランダムで[MASK]という特殊トークンに置き換えて、本来の正しいトークンをクラス分類問題として学習するというものです。この時のクラスの数がBERTの語彙数となります。
クラス分類
クラス分類とは、機械学習において、未分類のデータをある決まったクラス(カテゴリ)に分類して学習することです。これまでの学習の結果=法則性を基にして、未分類のデータに対してラベル付け(※)を行います。
※クラス分類ではラベルとデータのセットを持つ「教師データ」を用いる。分類を行うために、対象がどんなものかを示す情報を事前にラベルとして入力する必要がある
BERTの学習における具体例
学習の具体例として、「今日/は/いい/天気/です」という文章をトークンに変換し、ランダムに[MASK]する例が紹介されました。今回は「天気」の部分を[MASK]しています。
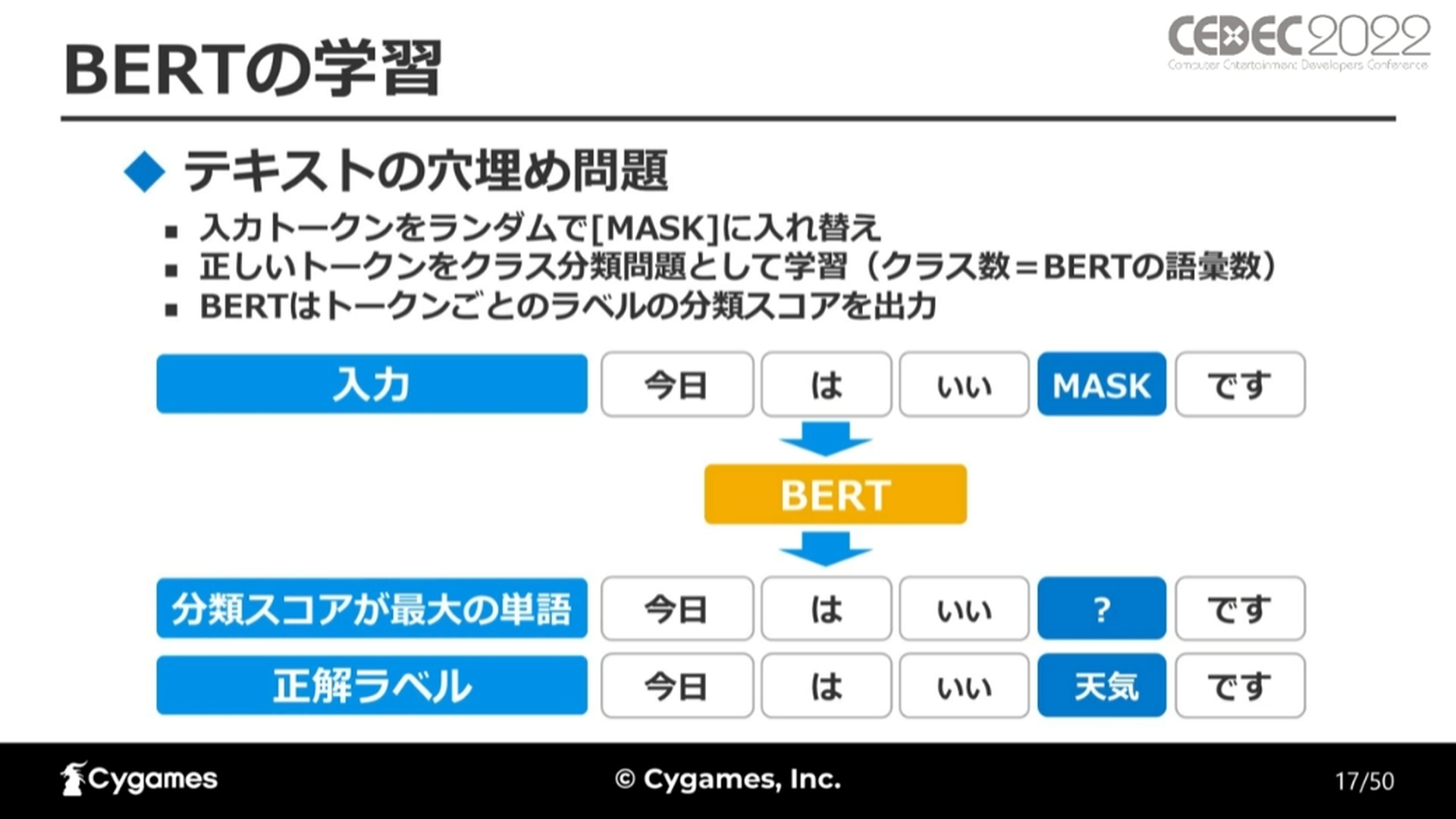
BERTはトークンごとの分類スコア(※1)を出力します。分類スコアが最大のものが、実際に出力される単語になります。この単語と正解ラベルから損失(※2)を計算することができます。この損失を使ってBERTの学習を行っていきます。
※1:機械学習モデルが出力する0から1の間を取る値。Positive(異常)と Negative(正常)を予測する場合、分類スコアが大きく1に近いほどPositiveの可能性が高く、値が小さく0に近いほどNegativeの可能性が高い、とモデルが判断していることを意味する
※2:機械学習においてモデルによって出力された予測値とのズレの大きさ。この損失の値を最小化(あるいは最大化)することで機械学習モデルを最適化する
先ほどの穴埋め問題の応用で、文章校正の学習を行うことができます。先ほどの入力の学習を「誤字のある文章」、正解ラベルの部分を「誤字のない文章」に置き換えます。
この状態で、入力トークンをランダムで[MASK]に置き換えて学習していくことで、誤字のある文章を入力すると誤字のない文章を出力するようにBERTを学習させていくことができます。

推論時には、入力トークンごとに分類スコアを求めます。分類スコアの一番高い単語が訂正候補となります。誤字検出機能の結果としては、訂正候補のトークンのリストと、その誤字の位置を返します。
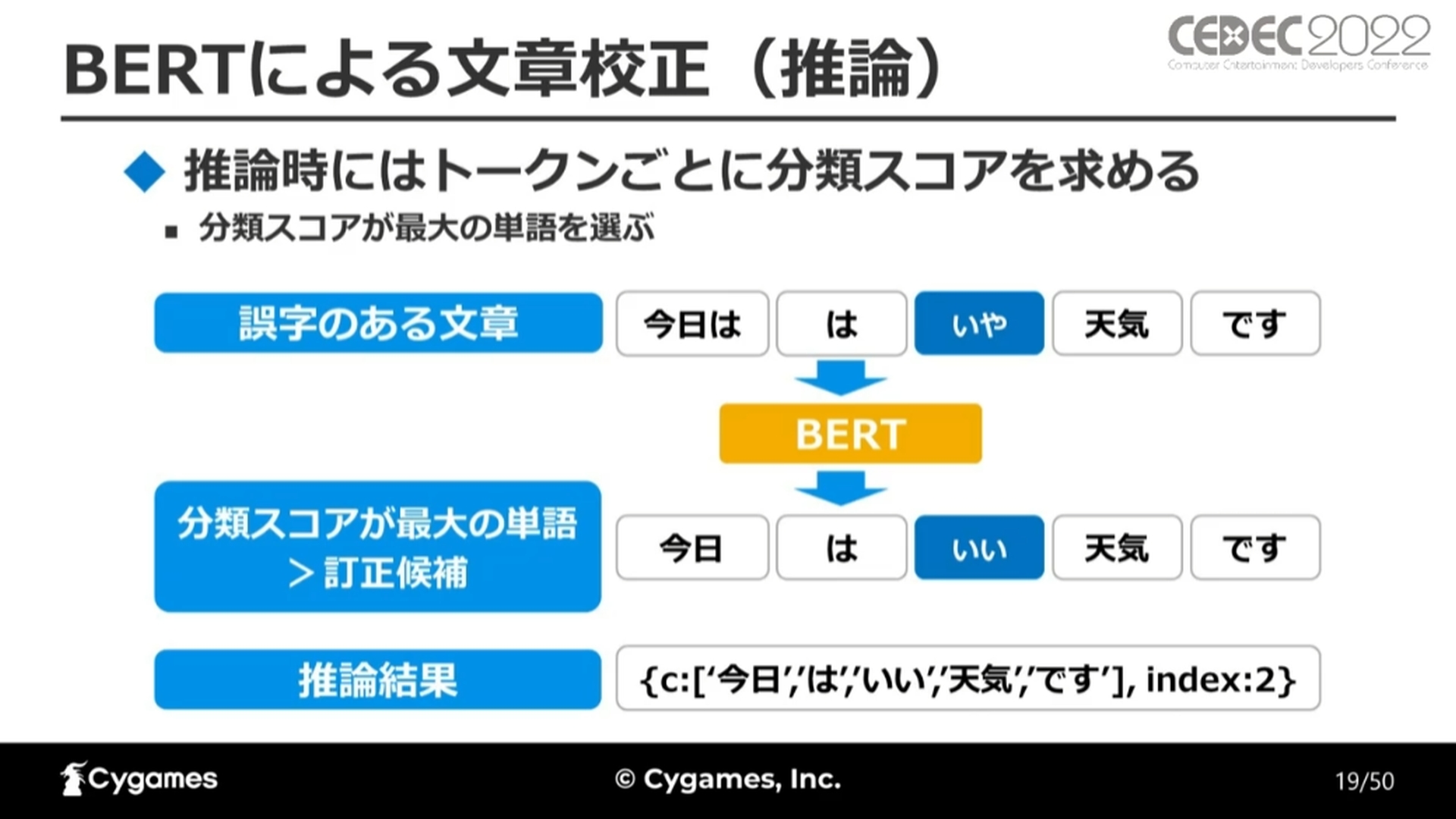
学習データセットにはゲームシナリオの文章データを使用
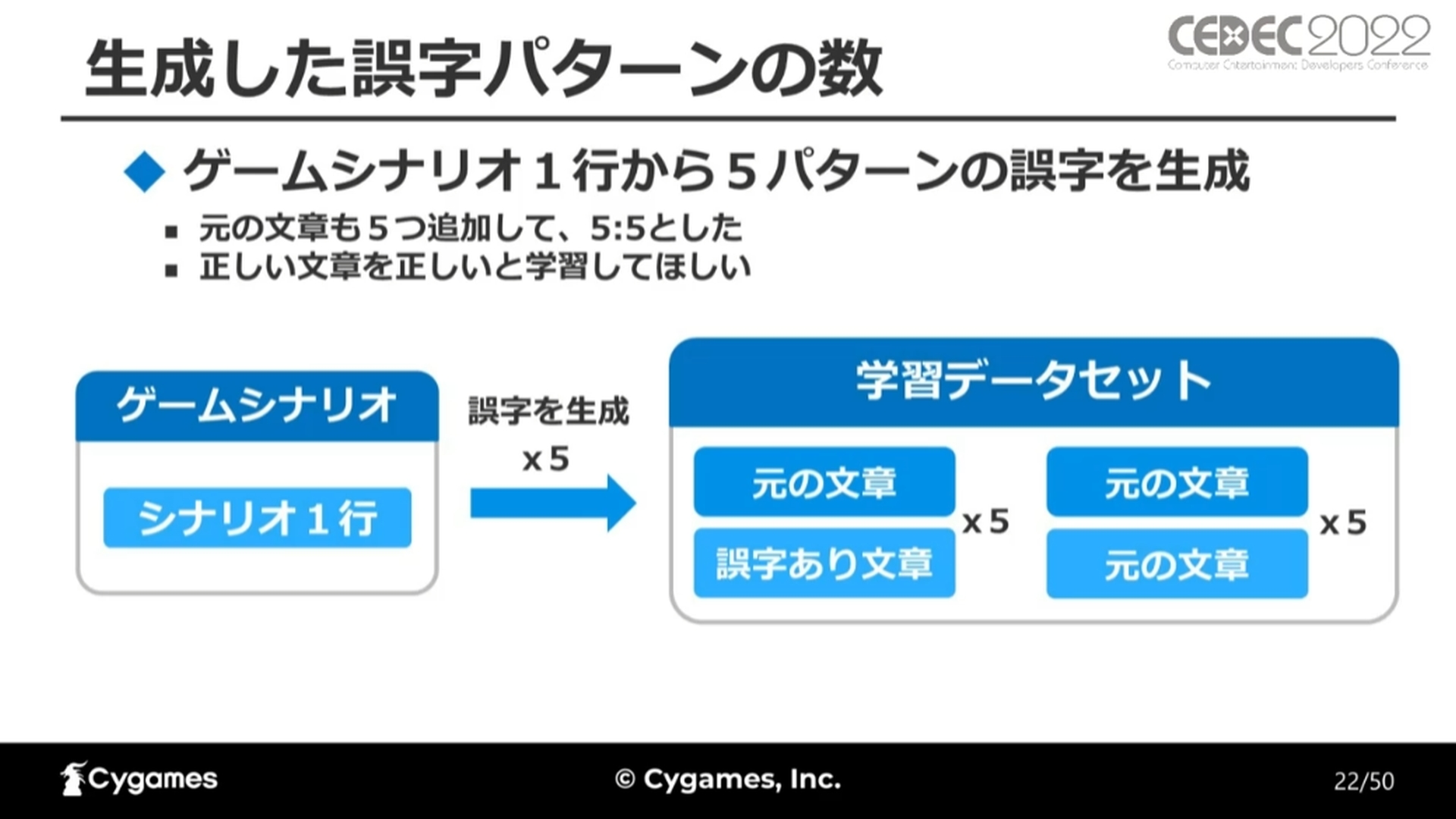
BERTの学習におけるデータセットは「もとの文章」と「誤字を入れた文章」の組み合わせになります。今回、学習に用いたのはゲームプロジェクトのシナリオ文章で、正しいものと誤字を追加したものが用意されました。
なお、ここではゲーム中に一度に表示される単位を1行として扱っており、誤字パターンは1行のゲームシナリオから5パターン生成しています。
3つの機械学習モデルを使用していた以前のバージョンと比較して、学習セットをBERTのみに絞ったことでメンテナンス性・実行時間・推論の正しさにおいてパフォーマンスが改善されました。

機械学習モデルを1つに限定したことでAWS Lambda上の実行時間も5分以下に短縮。誤字発見の精度も上がった
実装上の改良点
訂正候補を出す新しい誤字検出ツールを実装するにあたって、以下の点が改良されています。
誤字パターンの改良
以前のバージョンで7つの誤字パターンを使用しましたが、そのうちの1つである社内の校正テキストから手動で抽出された「よく間違えられる単語リスト」を「日本語Wikipedia入力誤りデータセット(以下、入力誤りデータセット)」と入れ替えました。
採用の理由は「よく間違えられる単語リスト」のデータ数が足りないことが問題となっていたため。「入力誤りデータセット」を利用することによって豊富な誤字パターンを利用することが可能となりました。

「入力誤りデータセット」は日本語Wikipediaの編集履歴のうち入力誤りを訂正した履歴をデータセットとしてまとめたものです。こちらには「訂正前の文章」、「訂正後の文章」、「訂正される単語」、「訂正後の単語」、「訂正の種類」などの情報が入っています。

入力誤りデータセットは、京都大学の黒橋・褚・村脇研究室がJSON形式で公開
今回はこの誤字のパターンを社内のゲームシナリオに適用したかったため、データセットのうち訂正が行われた単語の部分だけ利用しています。入力誤りデータセットの訂正後の単語をゲームシナリオから検索し、それを訂正前の単語に置き換えて誤字を生成しています。
入力誤りデータセットには単語だけでなくもとの文章も入っているため、単語を適用する品詞を調べて文章中の品詞が合う箇所だけ変更することも可能ですが、今回は省略したとのこと。また、訂正後の文字が1文字だけの場合、意図しない文字を置き換えてしまうことがあるため、2文字以上の単語のみ適用しています。
このような手順で、入力誤りデータセット側「教→今日」、ゲームシナリオ側「今日はいい天気です」から、学習データ「教はいい天気です」という誤字パターンを追加しています。
トークンマッチングの工夫
今回の仕組みではデータセットでトークン数が一致する必要がありました。誤字のある文章が「教/は/休み/に/し/よ/ー」、もとの文章が「今日/は/休み/に/し/よ/ー」の場合、トークン数は一致しています。一方、トークン数が一致しないデータは使用できません。

トークン数が一致する文章の組み合わせでは、シナリオ全体の6割程度しか利用できません。そこで、誤字のある文章ともとの文章でトークン数がずれている場合、使用されていない部分を埋める「PAD(Padding)」という特殊トークンを正解データに使用し、トークン数が一致するように調整しました。PADを実際に入れてみて、その後の対応がもっとも一致する場所に挿入するアルゴリズムになっており、推論時の出力には「PAD」を取り除きます。
逆に、正解の文章のほうがトークン数が多い場合、この手法は使えません。しかし、通常は誤字のある文章の形態素解析はうまくいかず、トークン数が多くなるため、あまり問題にはならないと説明されました。
最終的な精度
最終的な精度として、分離しておいたテストデータ10万行(誤字なし・あり、40%が誤字)での検証結果が説明されました。誤字のない文章は90%程度の確率で正しく判定しており、誤字のある文章も72%で判定できています。
誤字を正しく訂正できたのは30%程度に留まっていますが、立福氏いわく「もとの正しい文章を復元できているため、それなりに高い数値と考えられる」とのことで、一定の成果が現れた形になります。

誤字のうち28%は検出されなかったことになる。誤字を正しく訂正できたのは30%程度だが、もとの正しい文章を復元できているためそれなりに高い数値、と立福氏は考えたとのこと。プロジェクトAとBの違いは単純にデータセットの分量の差
シナリオ執筆ツールのUIを改良
続いて、誤字検出機能をユーザーに利用してもらうためのUI設計について説明されました。
以前のバージョンでは、誤字検出機能を利用するユーザーが限られていました。これは誤字検出機能が執筆画面ではなく一括処理画面に入っており、ユーザーは誤字検出機能を使うために別画面に遷移する必要があったことが理由とのこと。シナリオライターの使用は少なく、使用したユーザーの多くは監修者となっていました。

そこで、執筆画面に誤字検出機能のボタンを追加するというUI改良を行いました。「新たな機能を開発してもUIが悪いと使ってもらえず、AIの性能と同様にツールのUIも重要」という事例になります。

UIを改善したことにより誤字検出までの手順が減った
ルールベースの文章校正機能
最後に、ルールベースの文章構成機能について説明されました。AIを使わないルールベースの文章校正機能として「難しい漢字の検出(漢検1級、準1級で登場する漢字)」「補助動詞の漢字を検出」「ら抜き言葉を検出」などがあります。難しい漢字の検出については、漢字のテーブルを事前に持っておき、マッチしているだけのシンプルな仕組みになります。
補助動詞の漢字を検出
「補助動詞の漢字」のミスについて、具体的には「ちょっと寄って来る」の「来る」が、補助動詞(付属動詞)であるのに漢字が使われている場合などが挙げられます。補助動詞の検出は、京都大学の黒橋・褚・村脇研究室が公開している形態素解析システム「Juman++」を使用しています。
AIでの誤字検出機能ではMeCabを使って形態素解析を行っていますが、MeCabでは補助動詞の検出をするのに情報が足りないため、Juman++の結果も使用しています。
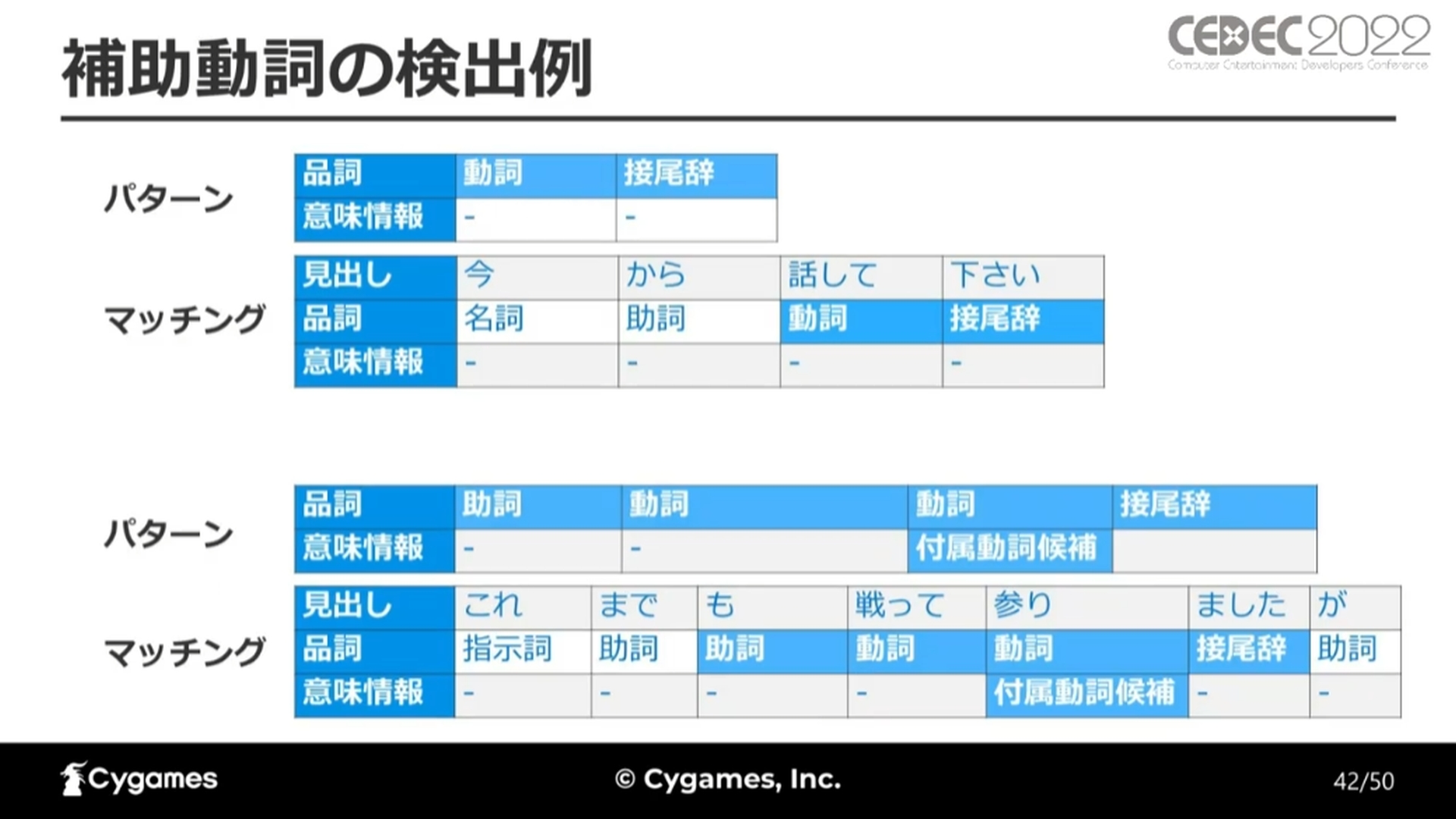
補助動詞の漢字検出では、最初にユーザーが補助動詞を検出したい文章のリストを基に補助動詞を検出するパターンを作成します。たとえば「参考/に/して/頂く」という文の場合「頂く」が検出したい補助動詞です。Juman++で形態素解析を行い、登場した品詞の順序を検出パターンとして登録します。
このようにして、ユーザーが検出したい文章のリストから補助動詞を検出するパターンを20件程度作成しました。
補助動詞を検出できたパターン
この検出パターンを使用して、実際に補助動詞を検出します。検出できた例として、最後が「動詞」+「接尾辞」のパターン、「助詞」+「動詞」+「動詞」+「接尾辞」のパターンが挙げられました。
ら抜き言葉を検出
ら抜き言葉に関しては、Web記事「ラ抜き言葉判定アルゴリズムを考えてみる」を参考にして実装しました。Juman++で形態素解析を行い、「代表表記」と「活用形1」を利用します。

上記のように、あるトークンの代表表記が「れる/れる」で、そのひとつ前のトークンの活用形が「未然形」「カ変動詞来」「母音動詞」だと、ら抜き言葉であると判定できます。
あるシナリオ全体でテストすると、158件の検出に対して正解が148件、失敗が10件でした。キャラクター特有の言い回しで誤検出する場合もありますが、失敗は少ないといえます。

最後に立福氏は講演内容を総括した上で「Cygamesでは最高のゲームシナリオを提供するためにAIを活用していきます」と語り、講演を締めくくりました。
講演参考文献
「BERTによる自然言語処理入門 Transformersを使った実践プログラミング」
編集:ストックマーク株式会社 著者:近江 崇宏、金田 健太郎、森長 誠、江間見 亜利 発行:オーム社
「作ってわかる!自然言語処理AI〜BERT・GPT2・NLPプログラミング入門」
著者:坂本 俊之 発行:C&R研究所

ゲーム会社で16年間、マニュアル・コピー・シナリオとライター職を続けて現在フリーライターとして活動中。 ゲーム以外ではパチスロ・アニメ・麻雀などが好きで、パチスロでは他媒体でも記事を執筆しています。 SEO検定1級(全日本SEO協会)、日本語検定 準1級&2級(日本語検定委員会)、DTPエキスパート・マイスター(JAGAT)など。
関連記事



注目記事ランキング
1
2
3
4
5
1
2
3
4
5
1
2
3
4
5
1
2
3
4
5
1
2
3
4
5
連載・特集ピックアップ
西川善司が語る“ゲームの仕組み”の記事をまとめました。
Blenderを初めて使う人に向けたチュートリアル記事。モデル制作からUE5へのインポートまで幅広く解説。
アークライトの野澤 邦仁(のざわ くにひと)氏が、ボードゲームの企画から制作・出展方法まで解説。
ゲーム制作の定番ツールやイベント情報をまとめました。
CEDECで行われた講演のレポートをまとめました。
UNREAL FESTで行われた講演のレポートやインタビューをまとめました。
GDCで行われた講演などのレポートをまとめました。
CEDEC+KYUSHUで行われた講演のレポートやイベントレポートをまとめました。
GAME CREATORS CONFERENCEで行われた講演のレポートをまとめました。
Indie Developers Conferenceで行われた講演のレポートやインタビューをまとめました。
ゲームメーカーズ スクランブルで行われた講演のアーカイブ動画・スライドやレポートなどをまとめました。
東京ゲームショウで展示された作品のプレイレポートをまとめました。
BitSummitで展示された作品のプレイレポートをまとめました。
ゲームダンジョンで展示された作品のプレイレポートをまとめました。
日本と文化が近い中国でゲームを展開するための知見を、LeonaSoftware・グラティークの高橋 玲央奈氏が解説。
インディーゲームパブリッシャーの役割や活動内容などを直接インタビューします。




今日の用語
プレイアブル(Playable)
- ゲームをプレイすることができる状態。
- 1の状態の実行ファイルのこと。
- プレイヤーの操作が可能な状態。操作可能なキャラクターのことをプレイアブルキャラクター(Playable Character)と呼ぶ。
Xで最新情報をチェック!




