今回登壇した矢部氏と宮内氏はディープラーニング技術を用いたプレイヤーAIの研究、中原氏はエンジニアとしてソフトウェア品質保証に従事しています。
ソニー・インタラクティブエンタテインメント ゲームサービスR&D部 Machine Learning Researcher 矢部 博之氏と宮内 佑多朗氏、基盤システム・エクスペリエンス設計本部 Software Engineer, Software QA Engineering 中原 弘貴氏
システムソフトウェアQAに求められたテスト自動化とゲームプレイ自動化
はじめに中原氏よりPlayStation5®のシステムソフトウェアQAの取り組みが紹介されました。
PlayStation5®はホームやコントロールセンターなどのシステム機能を有しており、その表示内容や画面遷移などの品質保証が必要となります。そのために、QAチームではテスト自動化を積極的に取り入れています。
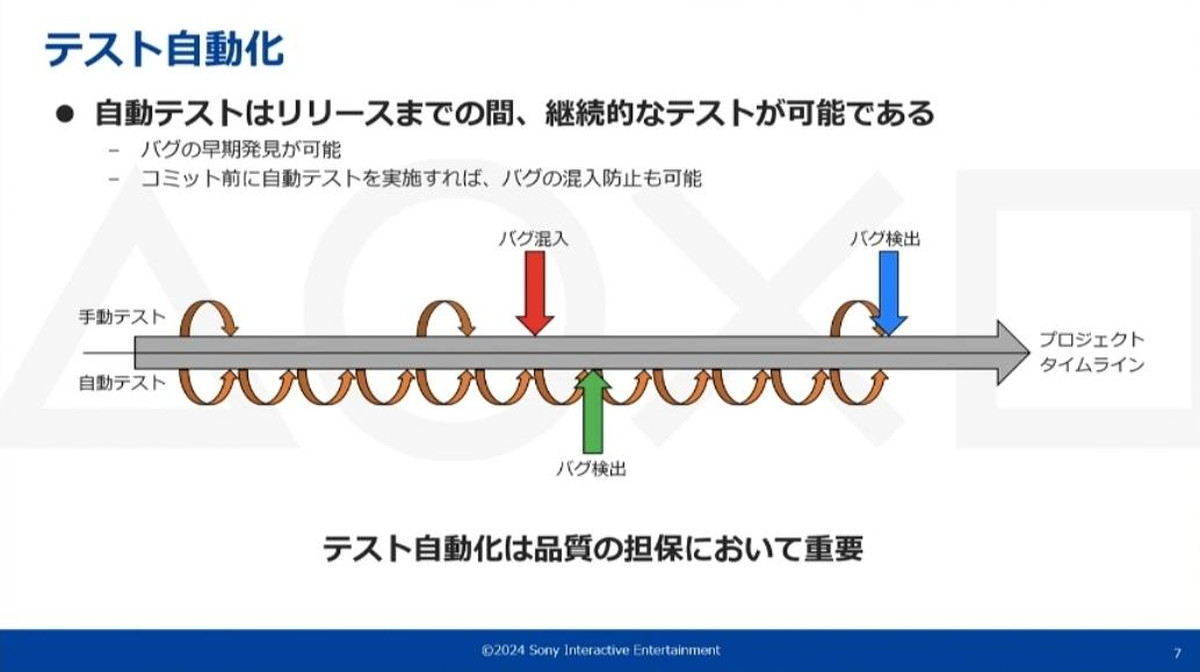
自動テストのメリットには、リリースまでの期間で継続的なテストができる点があります。これによりバグの早期発見や、開発コードのコミット前におけるバグの混入防止が可能になります。
自動テストは毎日でも可能。数回の手動テストではバグ検出がリリース直前になりスケジュールに影響が出てしまう場合も、自動テストならば早期にバグ検出が可能になる
ただし、PlayStation5®の場合はゲームプレイに連動したシステム機能を有している点を考慮しなければなりません。
例えば「アクティビティ」というプレイ時間や進行度を確認できる機能があります。これを初期状態からゲームプレイを経て進行度が0%から更新されているかなどをQAで確認しますが、そのためにはある程度のゲームプレイが必要となります。
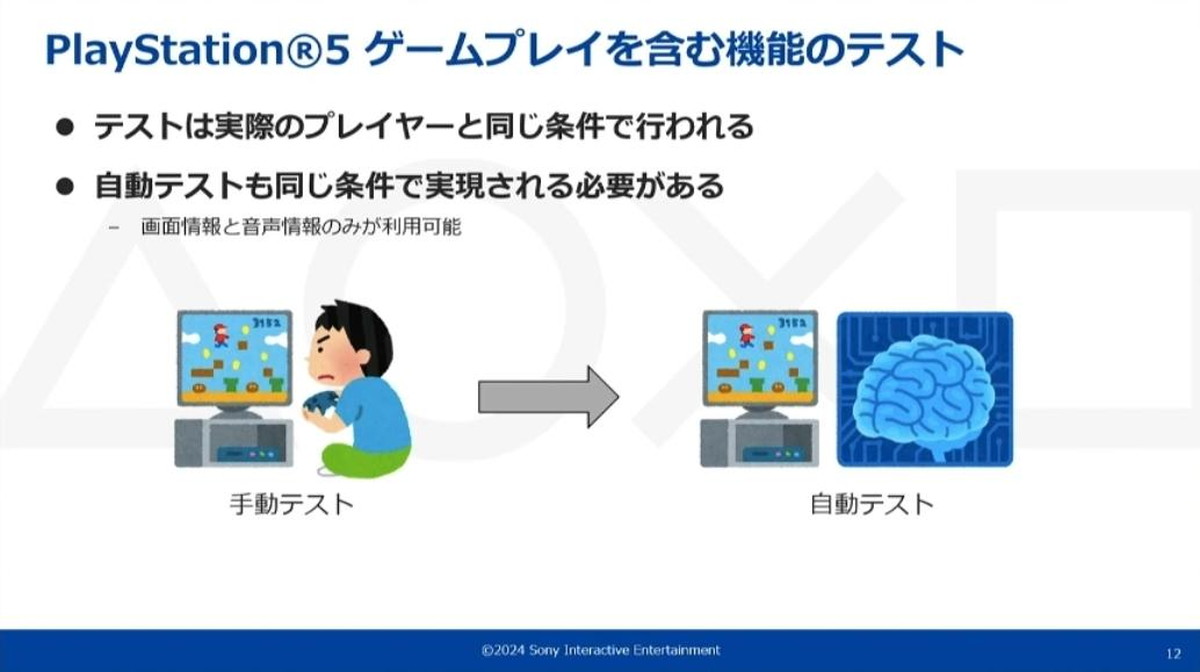
そこでテスト自動化のために必要なゲームプレイの自動化を考えます。ゲームプレイに連動した機能はタイトルによって有無があり、タイトル内容に依存しない汎用的なプレイが求められます。そしてゲームプレイの自動化は、人間のプレイヤーと同じ条件で行われる必要があります。
実際のゲームプレイと連動する「アクティビティ」などのシステム機能がある
ここで言う同じ条件とは、画面情報と音声情報のみを利用可能ということです。こうした制約があり今までは自動化が非常に困難でしたが、今回の講演ではその挑戦について紹介がありました。
ゲームプレイの自動テストには、実際のプレイヤーによる手動テストと同じ条件で実現される必要がある
2つのエージェントを用いた自動プレイシステムの開発
続いて矢部氏から、自動プレイシステムの紹介が行われました。
自動化の研究方針は、いくつかの制約がある中で、人間のゲームプレイを学習して再現する模倣学習をベースに複数の技術を組み合わせる開発となりました。
「画面と音声のみ利用可能」「タイトルに特化しない汎用的な技術」「現実的なコスト」といった制約の中で自動プレイシステムの開発が行われた
以降の自動プレイシステム説明として、PlayStation5®にプリインストールされている『ASTRO’s PLAYROOM』での実行例が紹介されました。
『ASTRO’s PLAYROOM』は3人称視点のアクションゲームで、狭い足場のアスレチックやランダムに移動する敵との戦闘など、シーンに合わせたリアルタイムの操作が求められる
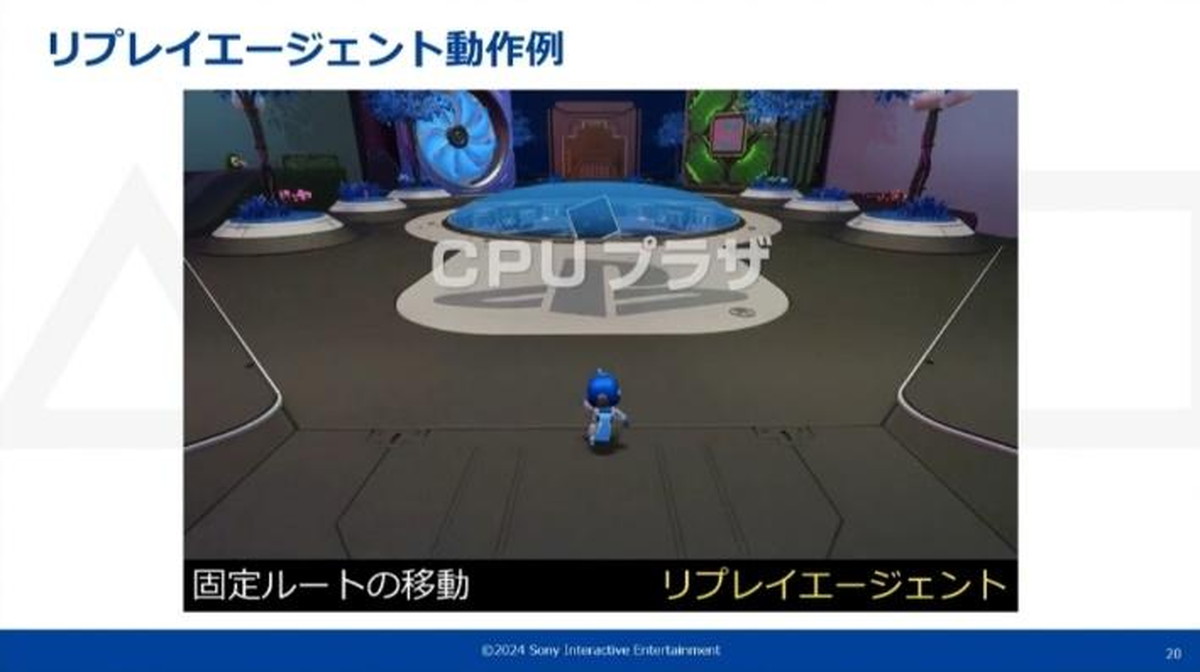
リプレイエージェントと模倣エージェントを用いたプレイ再現
自動プレイシステムは、PCがPlayStation5®からゲーム情報として画面のみを取得し、コントローラ操作をPlayStation5®に送信して行われます。
ゲームの操作を担当する機能には「リプレイエージェント」と「模倣エージェント」の2つがあり、シーンによってエージェントを使い分けています。
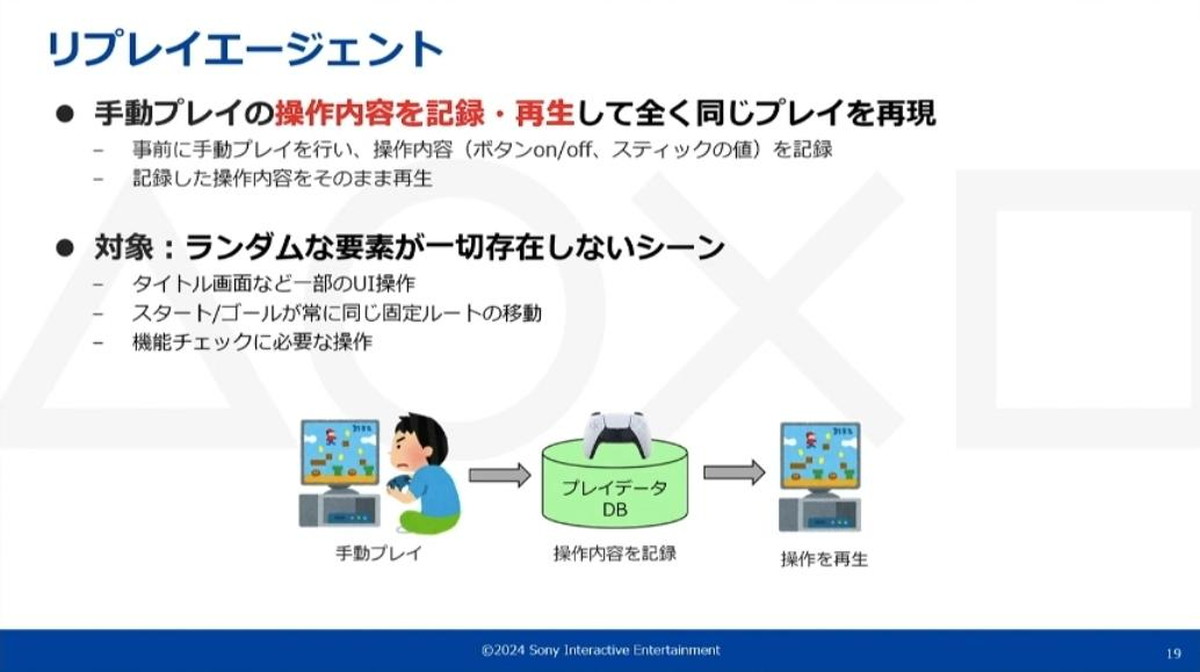
手動のゲームプレイを記録・再生することで全く同じ操作内容を再現する「リプレイエージェント」と、人間のゲームプレイを学習した機械学習モデルが人間のプレイを再現する「模倣エージェント」がある
リプレイエージェントは、事前の手動プレイで操作内容を記録再生し、コントローラ操作を再現します。ランダムな要素が一切存在しない、常に同じ操作で進行可能なシーンを利用対象としています。
メニューUI操作、固定ルートの移動、PlayStation5®機能チェックなどにリプレイエージェントを使用できる
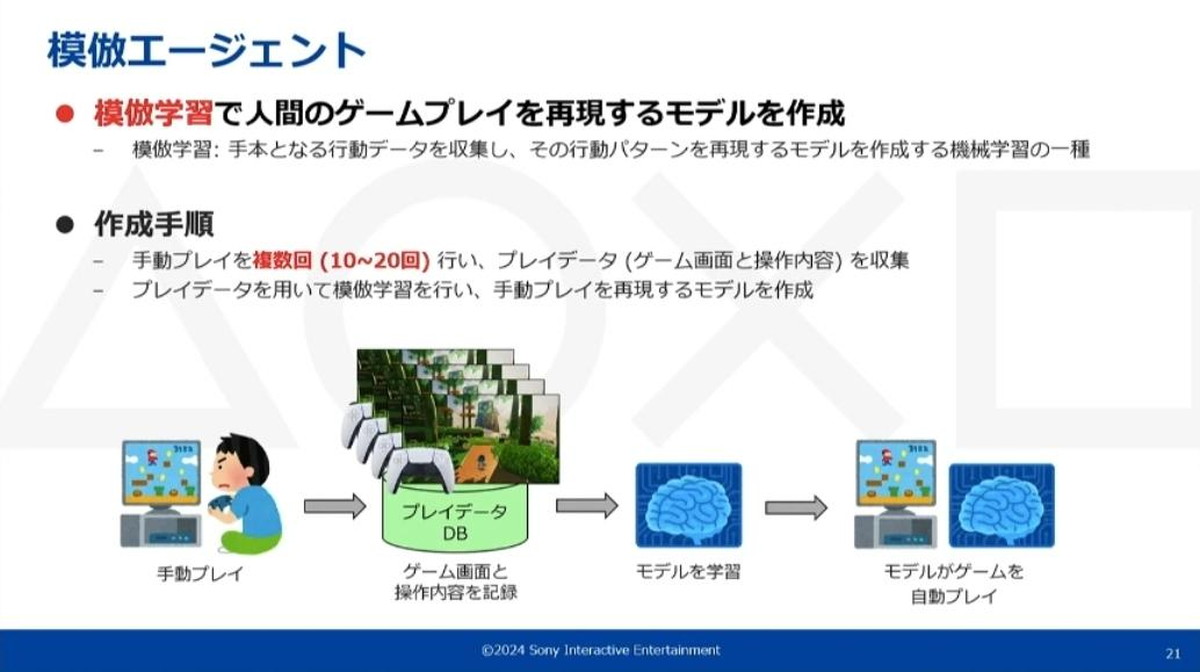
模倣エージェントは、模倣学習によって人間のプレイを再現する機械学習モデルを作成し、それを動作させることで自動プレイを行う機能です。模倣学習とは、お手本となる行動データから行動パターンを再現するモデルを作成する機械学習の一種です。
学習の手順として、まず事前に手動プレイを複数回行ってプレイデータを取得します。その後、収集したプレイデータを用いて模倣学習を行い、人間の手動プレイを再現できるモデルを学習させます。
模倣学習モデルはゲームの画面情報のみを必要とし、画面情報を入力すると次のフレームにおけるコントロール状態を出力します。このモデルを10fpsで動作させることで模倣エージェントはリアルタイムに操作を決定できます。
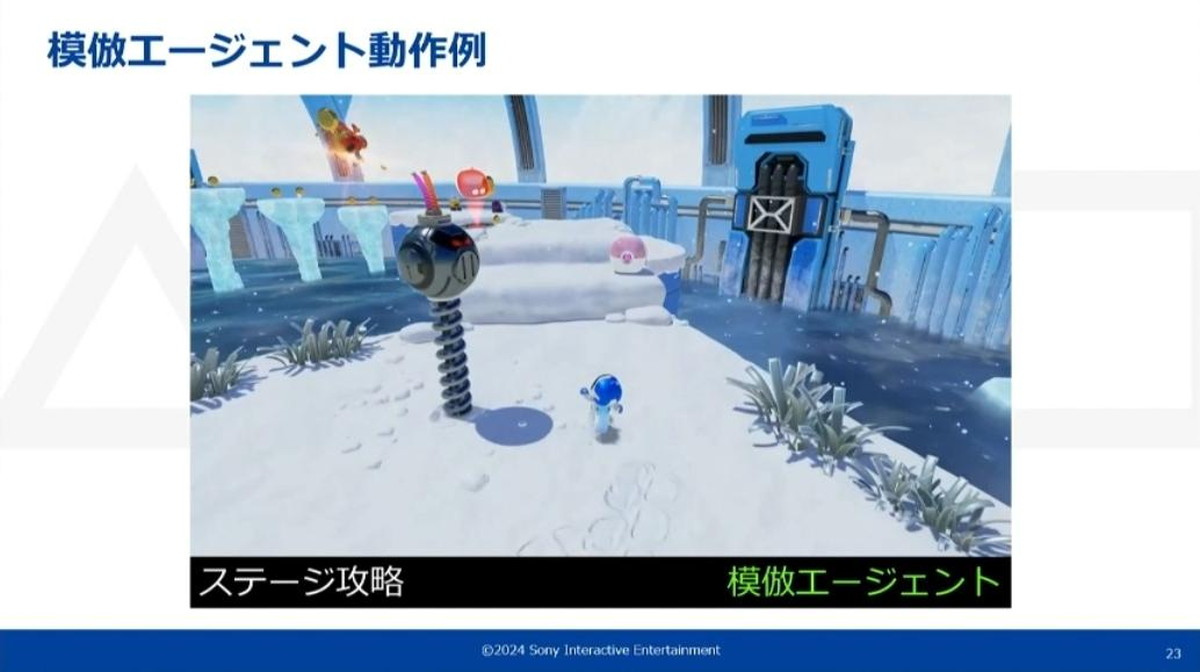
リプレイエージェントが適用できない、ステージ攻略など少しでもランダム要素のある全てのシーンに模倣エージェントを使用する
模倣エージェントはタスクごとに個別にモデルを学習しています。例えばステージAにはモデルA、ステージBにはモデルBといった形です。これは、ひとつのモデルが担当するシーンを少なくするほど、モデルの性能が安定することが分かっているためです。
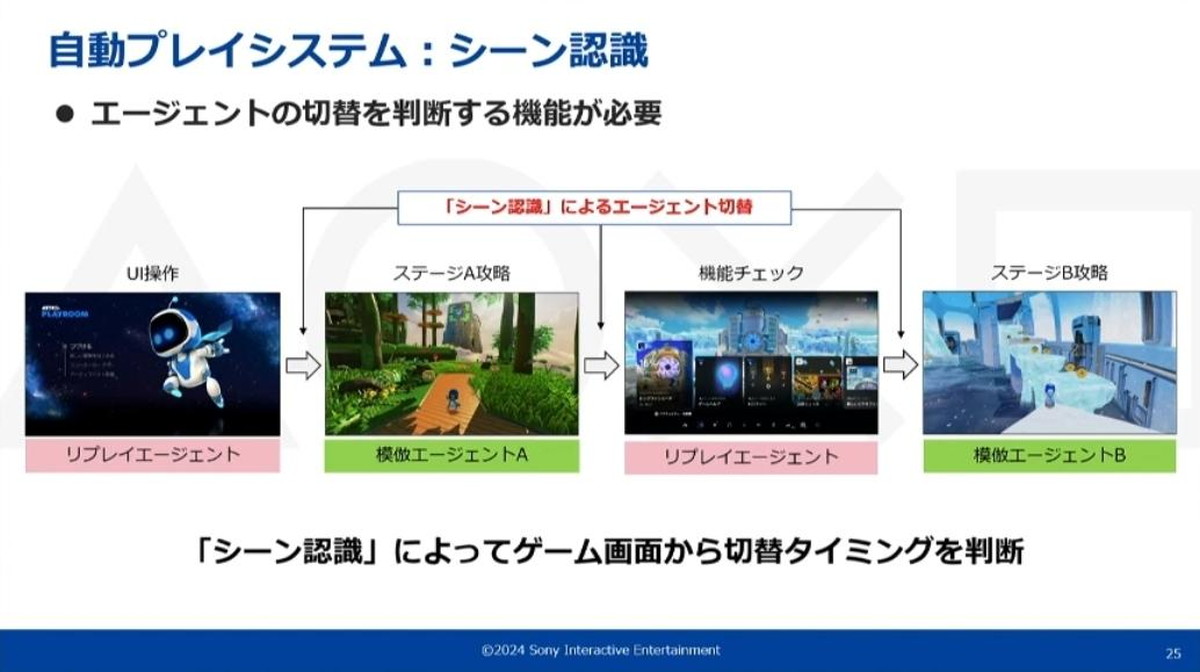
シーン認識で使用するエージェントを切り替える
リプレイエージェントと模倣エージェントをシーンに応じて切り替えるために、そのタイミングを判断するシーン認識の機能が別途必要となります。
シーン認識は画面情報のみから判断し、指定シーンへの到達を画面から認識する機能です。これには「テンプレートマッチング」と「特徴点マッチング」という2つの技術を用いています。
テンプレートマッチングは、あらかじめ準備したテンプレート画像と同じオブジェクトがゲームの画面内に存在しているかを判定するものです。例えば、クエスト攻略時に出てくるアイコンやポップアップ等を認識する場合に利用しています。
特徴点マッチングは、あらかじめターゲット画像を準備しておき、ゲーム画面とターゲット画像の類似度を常に監視し続けるものです。類似度が閾値を越えた場合に、ゲームがターゲット画像と同じシーンに到達した判断してエージェントを切り替えることができます。
なお、特徴点マッチングでは、見た目のブレに対するロバスト性(様々な外部の影響によって影響されにくい性質)が重要となります。
このマッチング技術として機械学習ベースのLoFTR(※)を利用しており、カメラの向きが多少違うなどしても同一シーンとして認識できます。
※LoFTR: Detector-Free Local Feature Matching with Transformers
カメラの向きやライティングなどによる見た目の変化に対して、ロバストに同一シーンを判定する機能が特徴点マッチングには求められる
このようなリプレイエージェントと模倣エージェントをシーン認識で切り替えることで、複雑なシナリオでも自動プレイが可能となります。
エージェント性能を改善する自動化の手順
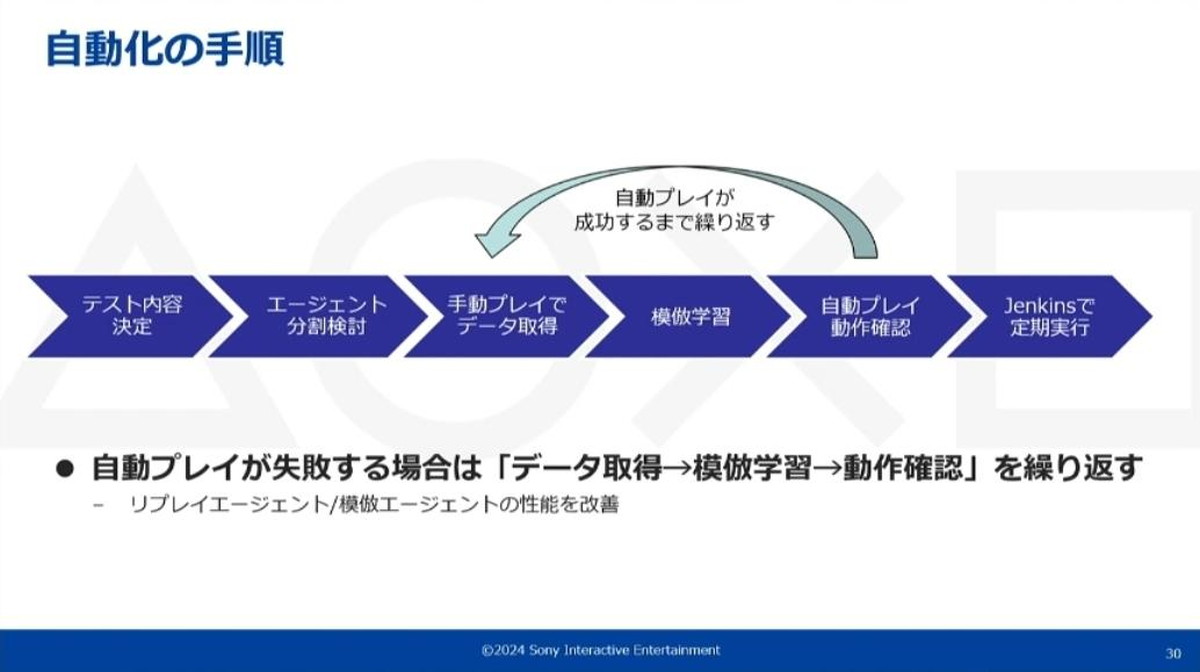
自動プレイシステムを用いたゲームプレイの自動化手順は、以下の通りです。
- 自動化したいテスト内容を決定
- エージェント単位に分割
- ゲームを実際に手動プレイし、データを取得
- リプレイエージェントの場合は1回、模倣エージェントの場合は10回以上プレイ
- 模倣エージェントの場合、取得したデータを用いて模倣学習を行う
- エージェントを実際に動かして自動プレイが通るか動作確認を行う。
- 失敗したらデータ取得のフェーズに戻り、エージェントが十分な性能を獲得するまでフローを繰り返す
- 自動プレイが通るのを確認後、Jenkins等の定期実行のパイプラインに乗せてプロセスを整える
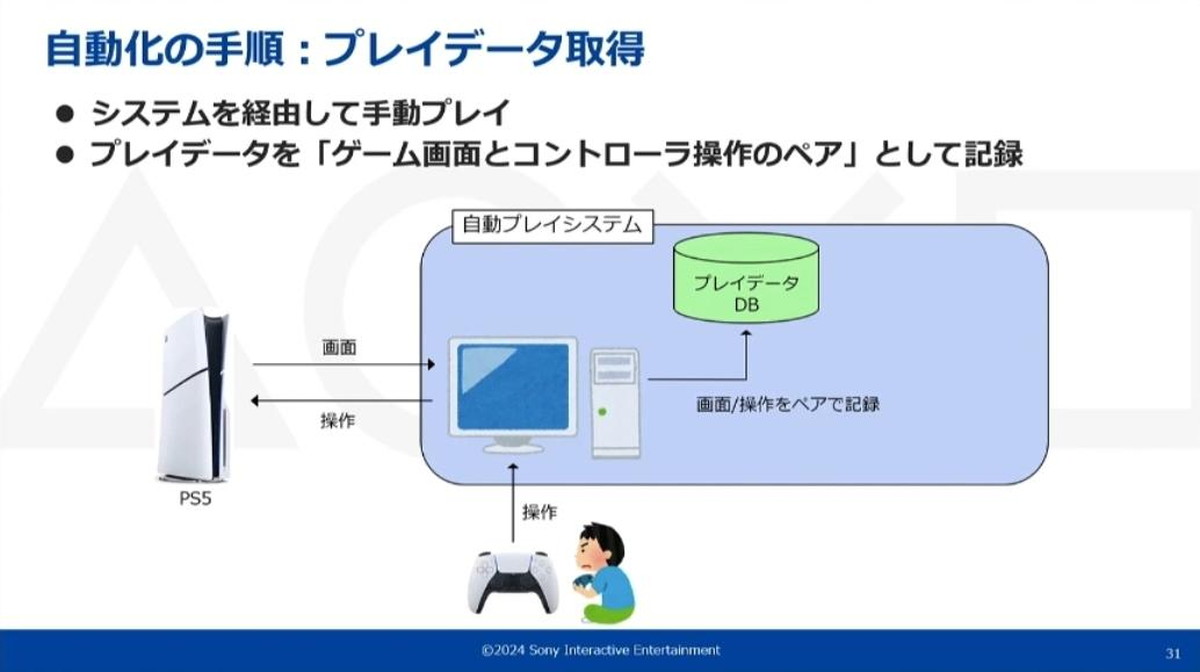
自動化の各手順におけるマシン構成やデータフローは以下のようになります。
手動プレイによるデータ取得時は、自動プレイシステムが動作しているPCにコントローラを接続し、このシステム経由でPlayStation5®上のゲームをプレイします。これによりPlayStation5®から送られてくるゲーム画面とコントローラ操作の内容を同期取得し、プレイデータとしてデータベースに保存していきます。
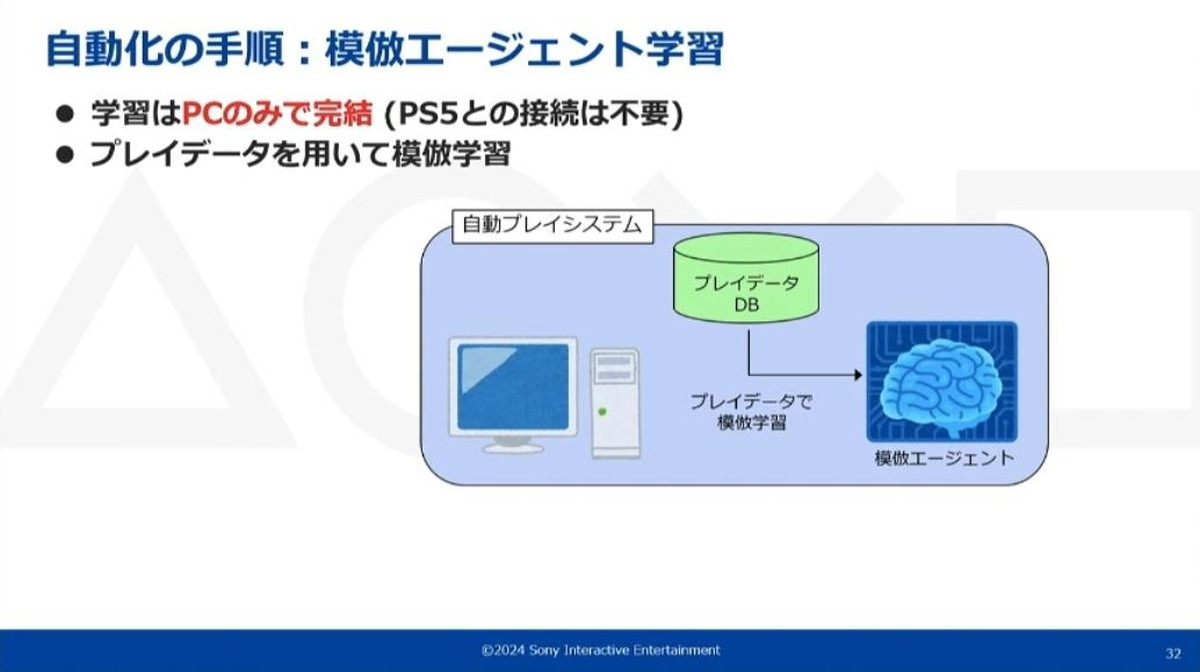
一方、模倣エージェントの学習時にはPlayStation5®との接続は必要なく、PC上のみで学習が完結します。
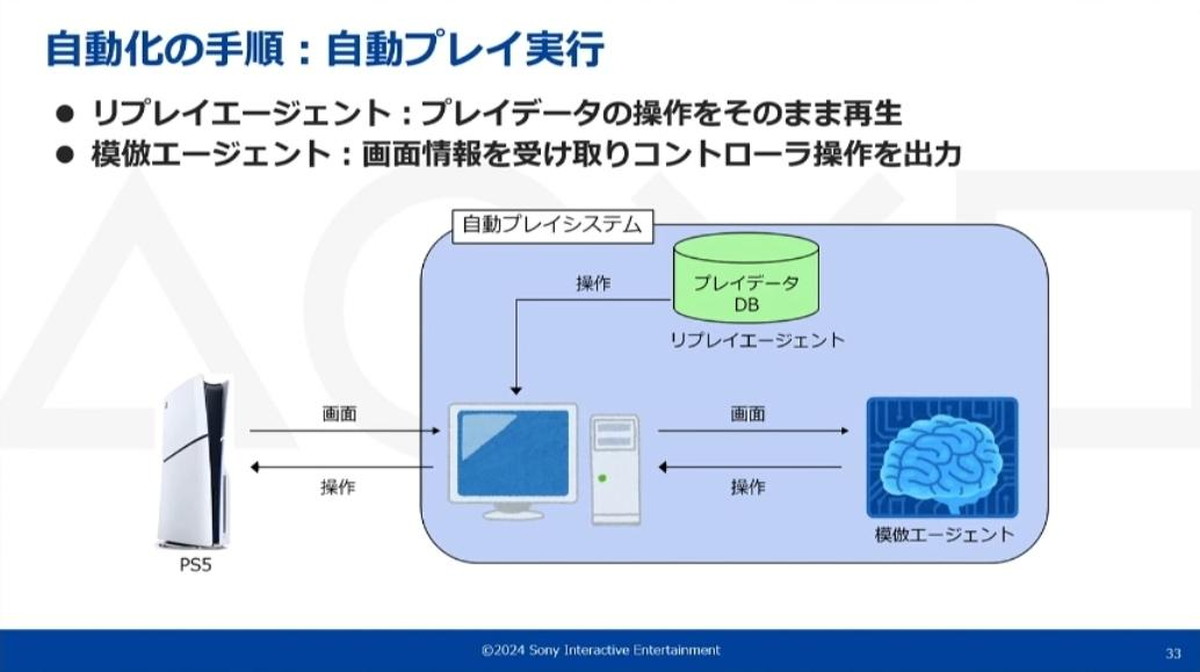
自動プレイの実行時は、自動プレイシステムがコントローラの操作内容を決定し、それをPlayStation5®に送信することでゲームを自動操作します。
リプレイエージェントは保存されたプレイデータから操作内容をそのまま再生、模倣エージェントはPlayStation5®から受け取った画面情報を入力内容として操作情報を出力するモデルを動作させて操作内容を決定する
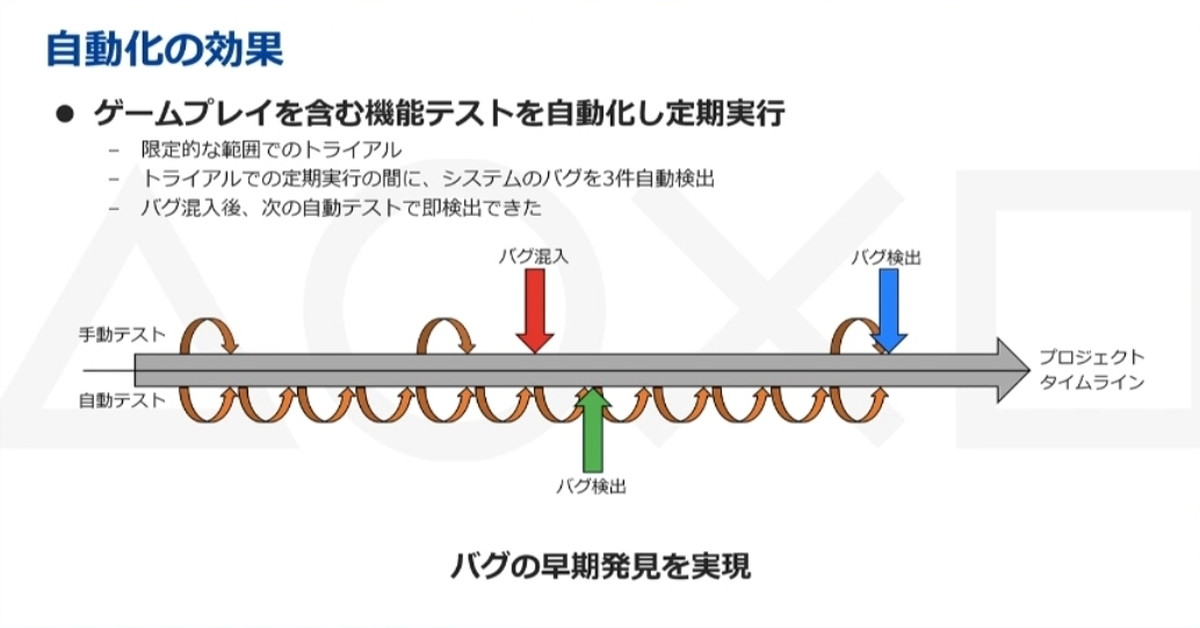
以上の自動プレイシステムは限定的な範囲でのトライアルですが、実際にテスト自動化して定期実行した結果、システムソフトウェアのバグを3件検出できました。発見数は決して多くはありませんが、当初の目的が達成できた点とバグの早期発見を実現できた点に成果としての重きを置いています。
また、その他の実施例としてFPS・アクションRPG・スポーツゲームなど複数のジャンルでも自動プレイシステムを検証しています。
ある事例では、手動で2時間かかるシナリオを自動プレイシステムでは5時間かけてクリア。模倣エージェントの動作が失敗することがありクリア時間が延びてるが、リトライ込みの最終的な自動プレイシステムによるクリア成功率は、ほぼ100%となりました。
別の事例では、手動で1時間かかるシナリオを最初から自動化する際の工数が約50時間となりました(シナリオの検討からデータ収集、模倣学習の動作確認を行い、性能が十分でなかった場合に再学習に戻る全工程の作業の累計)。最初は50時間分の工数がかかりますが、自動実行を繰り返すうちに削減できた工数が自動化にかかる工数を上回り、手動テストでは実現できないバグの早期発見が可能となることで、自動化の効用がコストを上回ると考えていると矢部氏は述べました。
機械学習によるモデル開発と性能改善の数々
続いて宮内氏から、ここまで説明に挙がっていた「模倣エージェント」の技術的な説明が行われました。
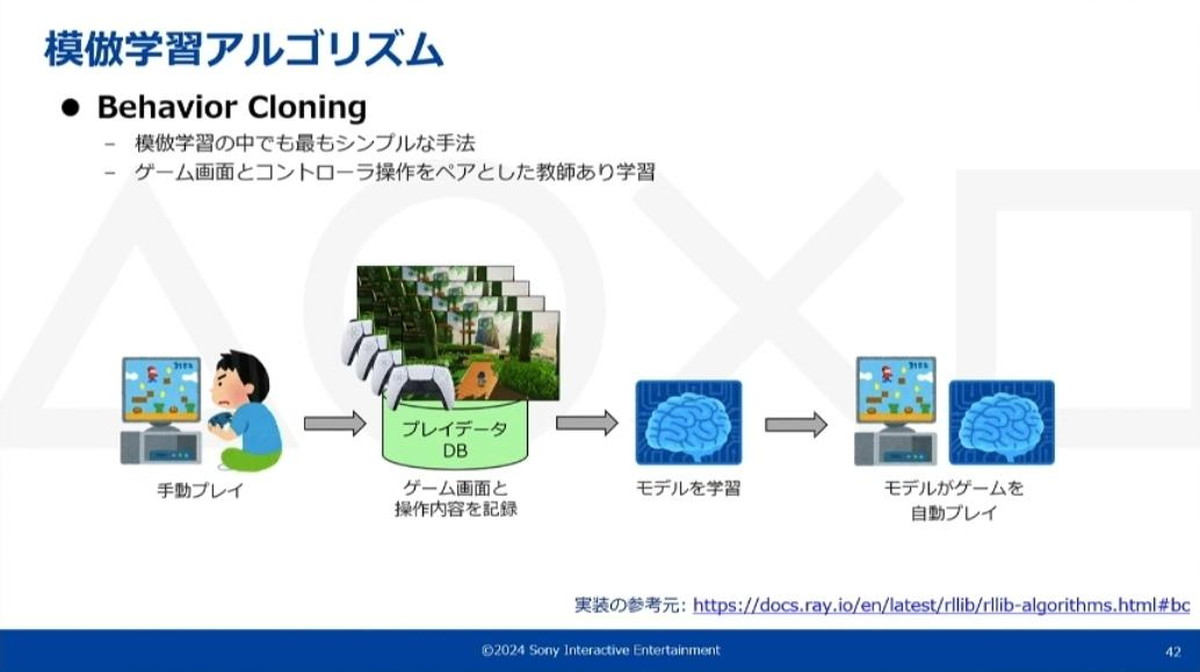
今回の技術は「様々なタイトルに対しても適用できる汎用性」と「誰でも使える簡易性」の2つを目指して開発が行われました。これらの目標を踏まえて、模倣学習ではではBehavior Cloningアルゴリズムを採用しています。
Behavior Cloningは模倣学習の中では最もシンプルなアルゴリズムで、モデルの入力と出力を対応付ける教師あり学習のひとつ
今回のケースでは、入力はゲーム画面、出力はコントローラ操作として学習しています。模倣エージェント作成までの流れとしては、事前に人間のプレイヤーが手動でゲームを操作し、ゲーム画面とそのコントローラ情報を記録します。記録したプレイデータを教師データとして、それをモデルに学習させます。
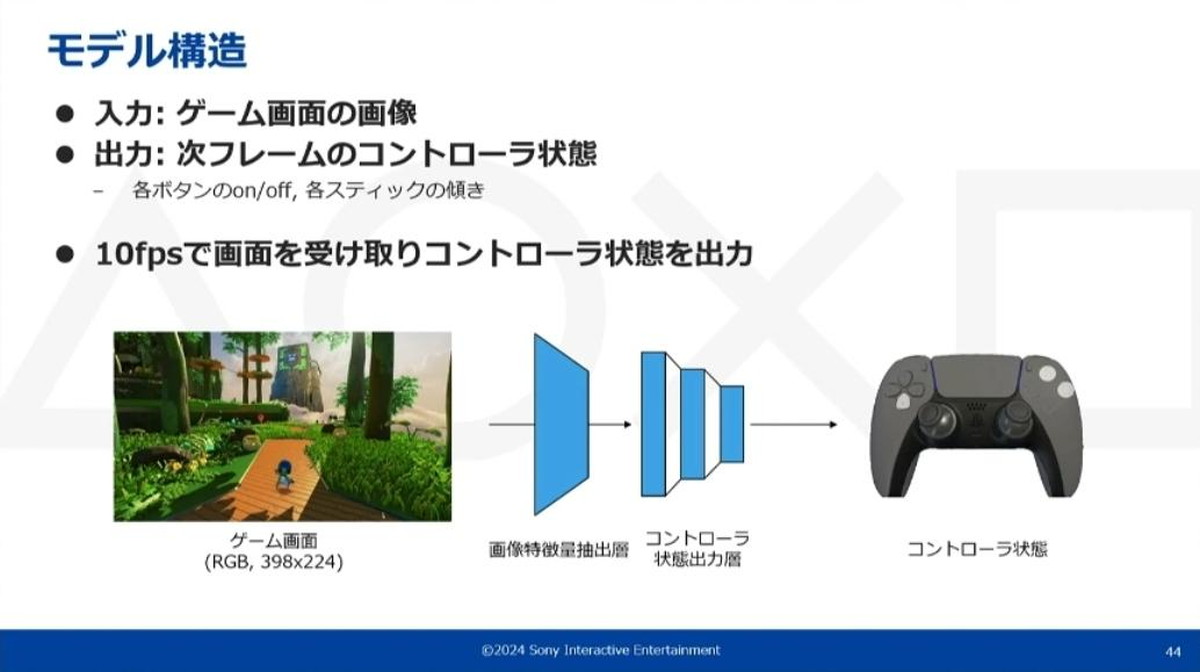
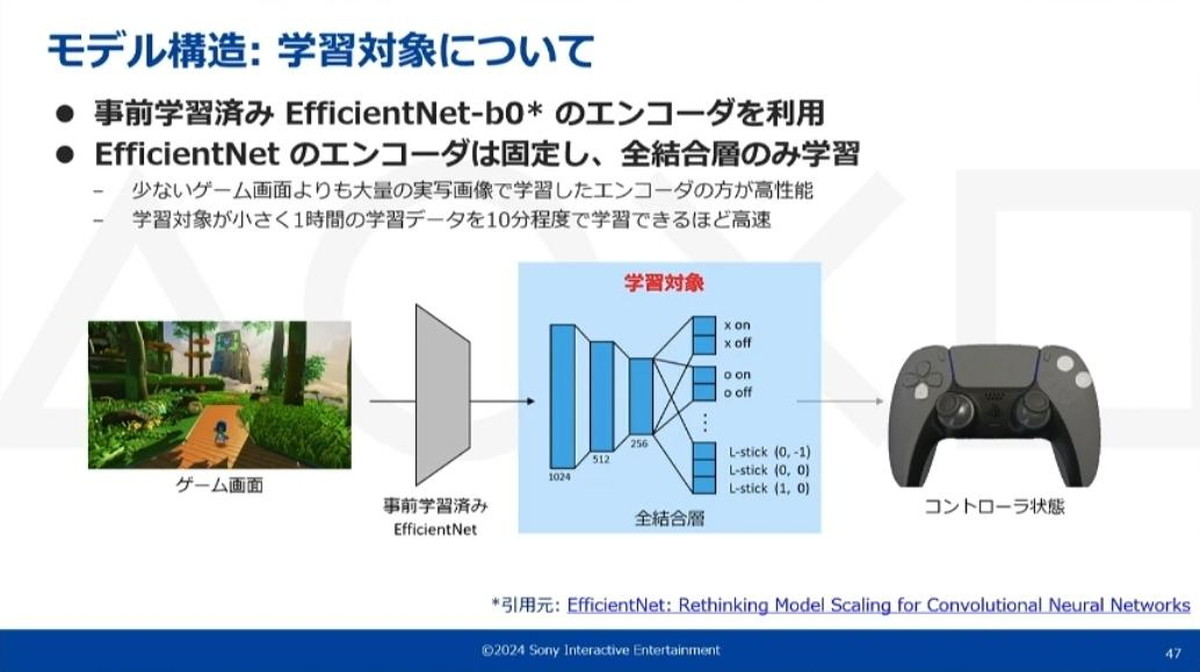
モデル構造
モデル構造は非常にシンプルなものとなっています。入力は画像一枚のみで、これを画像特徴量抽出層(CNN ※1)とコントローラ状態出力層(全結合層 ※2)に通して最終的にコントローラの状態を出力しています。
※1:画像の特徴量抽出の機械的手法のひとつ。画像の特徴量を畳み込み演算とダウンサンプリング操作によって抽出する手法
※2:ニューラルネットワークにおいて全てのノードを結合する層。CNNにおいては出力層に全結合層が用いられる
学習を簡単にするため、操作と記録の頻度は10fpsで行っている
アナログスティックの扱い
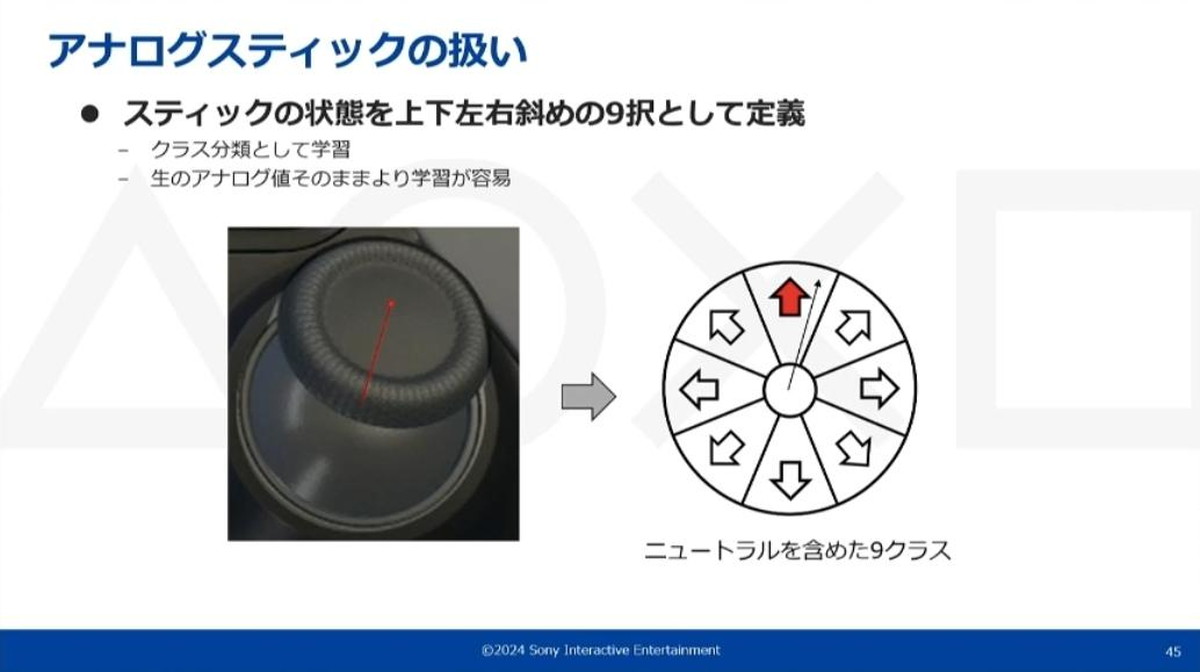
今回の工夫として、コントローラのアナログスティックの状態はすべてアナログ値ではなくクラスの値として扱っています。
PlayStation5®側に送信される操作もすべてクラスに対応した値が送られ、プレイデータと実際のPlayStation5®の操作に齟齬がないようにしています。
スティックは上下左右斜めニュートラルを含めた全9クラスとして扱っており、データベースにも全てクラスの値として保存される
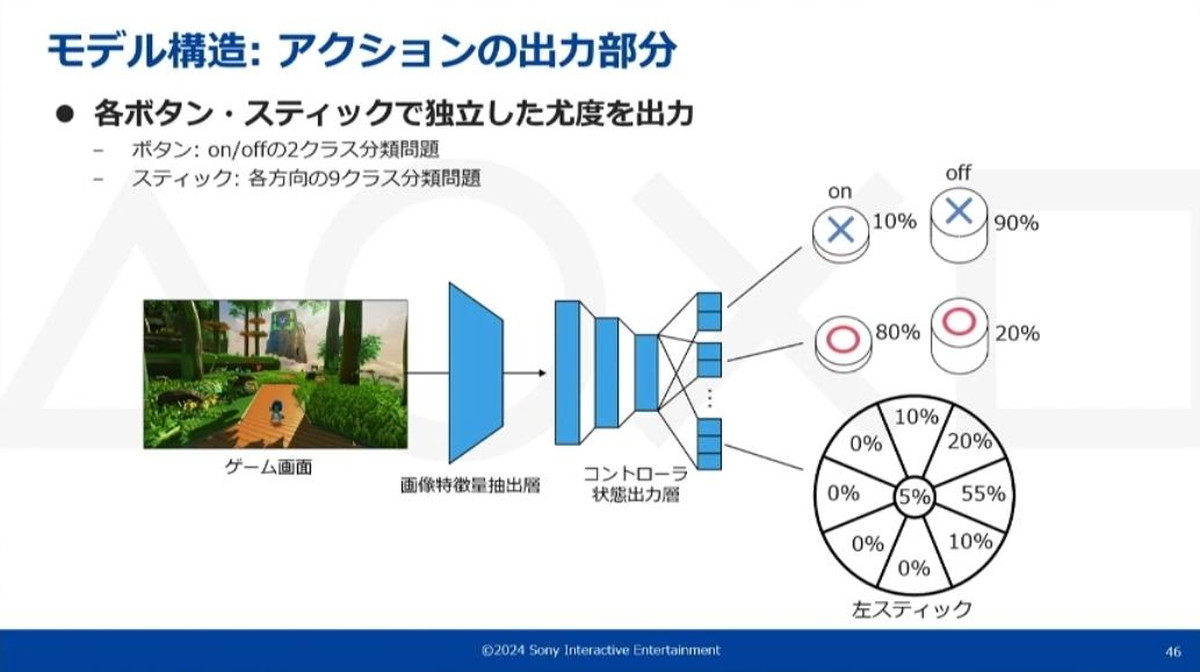
アクションの出力部分
今回のケースでは、padの各ボタン・スティックの状態を出力したいので、ボタン・スティックごとに最終層が分岐したようなネットワークを使用しています。
最終層の各全結合層では、ボタンであればon/offそれぞれの尤度(ゆうど ※)、スティックであれば各方向の尤度を出力しています。このボタン・スティックそれぞれは、ネットワークごとにクラス分類として独立に学習されています。
※想定するパラメーターがある値をとる場合に観測している事柄や事象が起こりうる確率のこと
データセットに合わせて余分な操作のネットワークを作らないことで、不要な学習の発生を防ぎモデルの性能を向上させている
モデルの学習対象
学習対象において、ネットワーク後段の全結合層がコントローラ状態出力層に対応しています。画像の特徴量抽出層には事前学習済みのEfficientNet(※)のエンコーダを利用しています。EfficientNetのエンコーダは学習せずに、全結合層のみを学習しています。
※引用元:EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
プレイデータに依存するが、少ないゲーム画面でエンコーダを学習するより大量の実写画像で事前学習されたEfficientNetを使った方がモデルの性能が上というのが、様々なタスクで確認されているとのこと。
また、全結合層のみを学習しておりネットワークがかなり小さいため、学習が非常に早いといったメリットもある
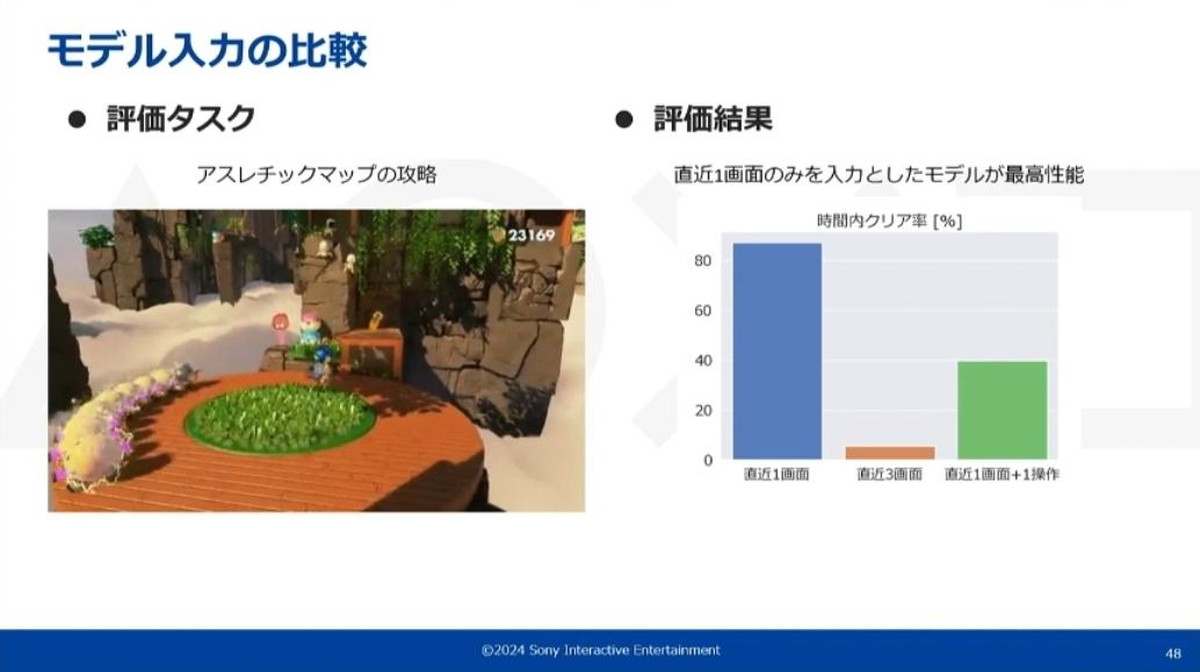
モデル入力の比較
ここまで入力は画像一枚のみと紹介されていましたが、その理由は直近何フレーム分を入力するか、過去の操作も画面と同時に入力するかを比較した実験を行ったところ、直近1画面のみを入力としたモデルが最高性能となったという結果によるものです。
この実験では手動プレイで1分程度の距離になるアスレチックマップのクリア率を計測し、この距離をモデルが10分以内にクリアできたかどうかを評価値としてる。なお、どの結果も30プレイ分の同じデータで学習されている
上記スライド画像の右側にあるグラフのように入力を増やすと性能が落ちるという結果が確認されており、こういった傾向は他のゲームや他のタスクでも同様に見られたそうだ
不均衡データへの対策
ここまでの開発で直面した課題として不均衡データへの対策があります。例を挙げると、ゲームの特性として出現回数は少ないがクリア率に大きく影響する操作が存在する場合などです。
具体的には、例えばランダムな地点に落ちている進行に必須なアイテムを拾うために×ボタンを押す必要があるとします。これが1000ステップ中に一回しかない場合、×ボタンの割合はそれだけで0.1%となります。
深層学習においては、こういったわずかな操作というのは学習がなかなか進まず、期待通りに×ボタンを押すモデルの作成は非常に困難になります。
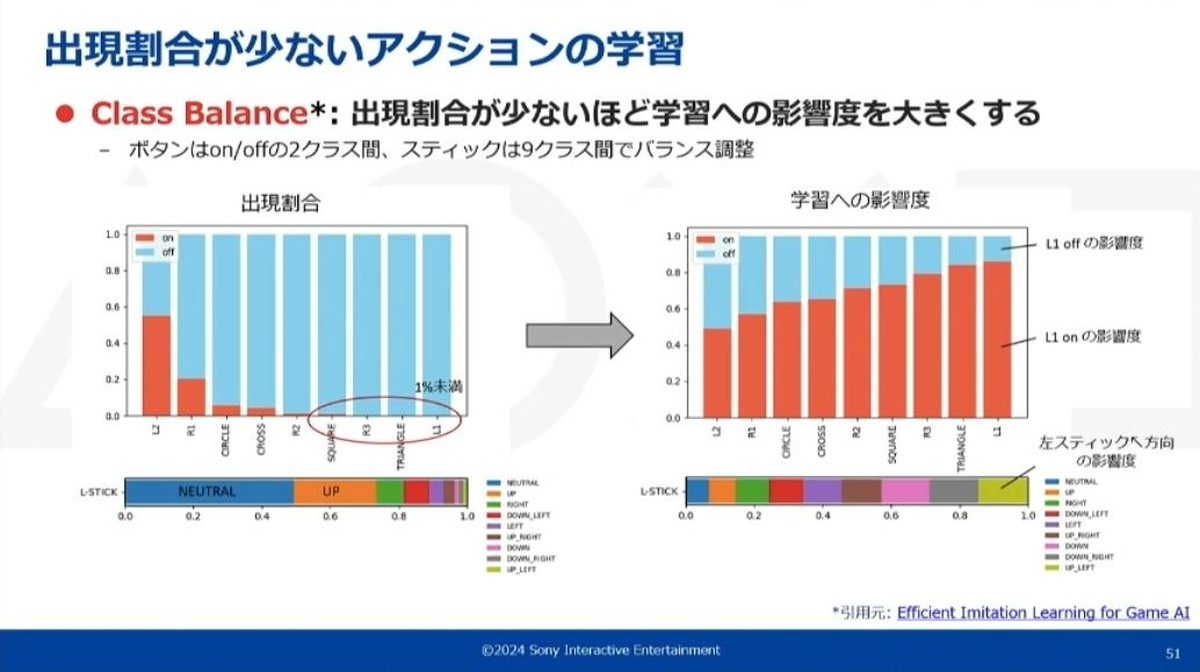
こういった状況は一般的なクラス分類タスクにも見られるもので、不均衡データ問題(またはクラスインバランス問題)などと呼ばれます。こういった問題の対処方法は一般的に大きく分けて2通りあり、一つが学習に使うデータのサンプリング確率を調整する方法、もう一つは学習がモデルに与える影響度を調整する方法です。今回の取り組みでは、影響度を調整するClass Balanceという方法を採用しています。
上記のグラフで示しているように、出現割合が少なければ少ないほど重みをつけ、少ない操作の学習がより強くモデルに反映されるClass Balanceを採用した
Class Balanceの有無で効果を比較するとジャンプの頻度やスムーズさで差が付き、クリア時間やクリア率もClass Balance有りの方が大きく向上している
こういった傾向は他の様々なタスクに対しても見られ、同じように性能が向上することが確認できています。
追加データを使った性能改善
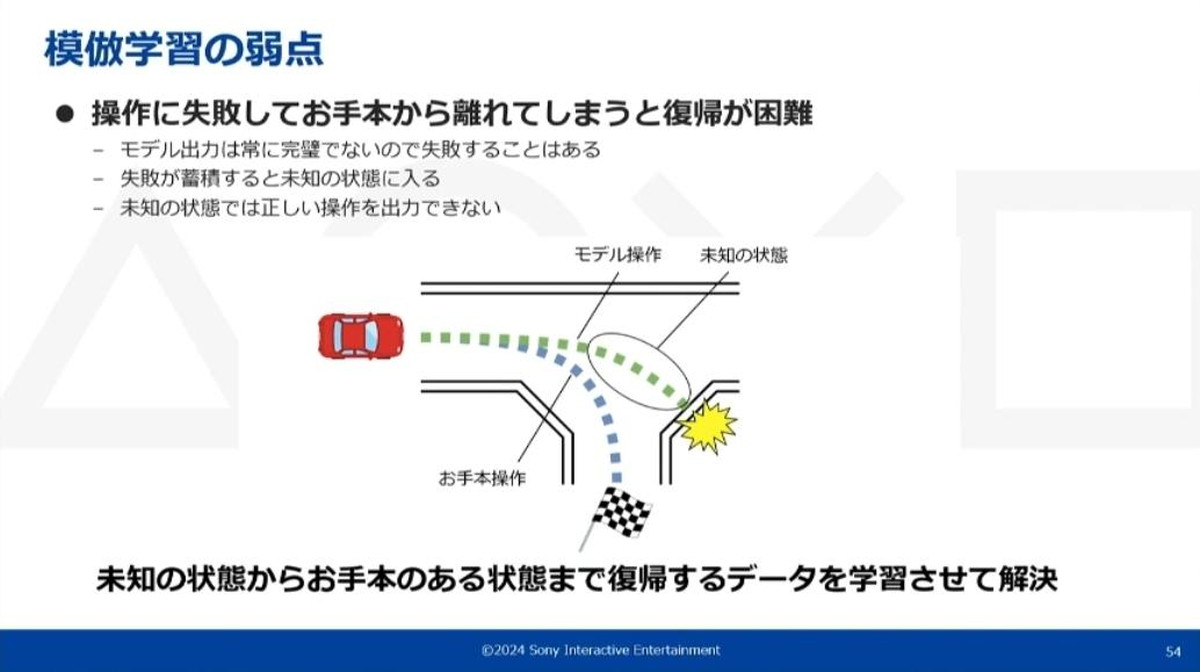
もう一つ直面した問題として、模倣学習の弱点があります。今回ゲーム操作を教師ありのクラス分類問題として学習していますが、過去の操作が将来の状態に影響するゲーム環境においては、誤操作の蓄積によりお手本から離れる可能性があることに留意する必要があります。
モデルは「お手本から離れた状態を、お手本のある状態に戻す」という学習データが与えられていないため、最終的に人間の操作では発生しないような状態に陥ります。
上記のように未知の状態の場所では、外れそうになるコースを元に戻すというお手本が含まれていない。そのため学習したモデルも元に戻ることができず、最終的に衝突する結果になる
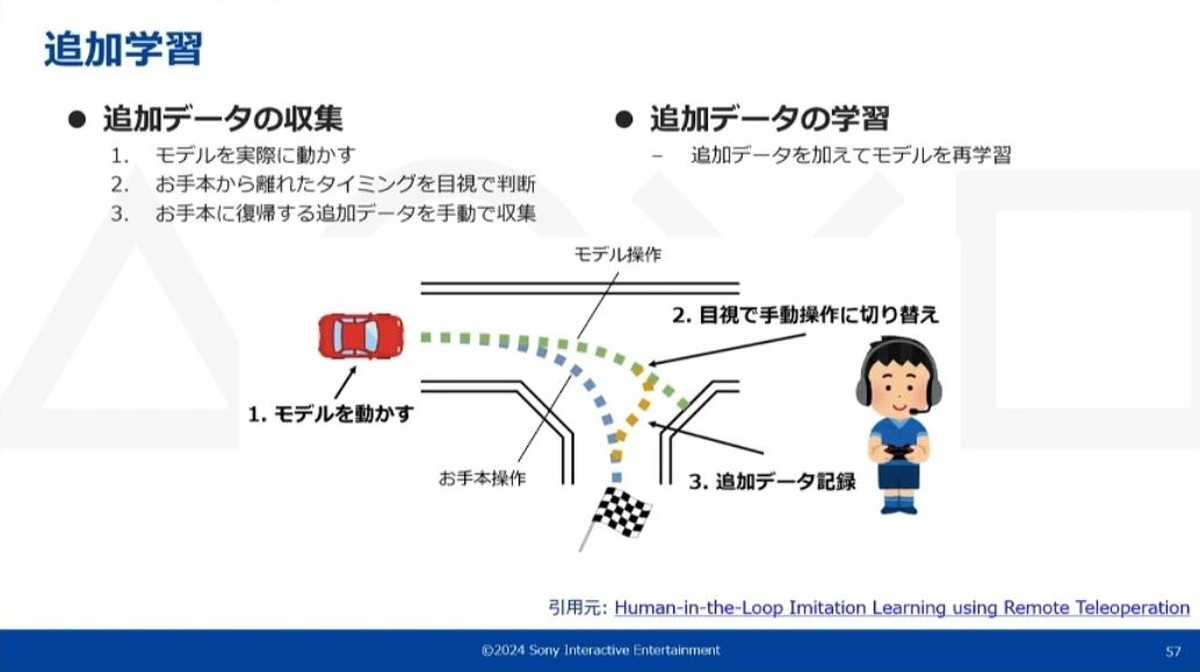
この現象に対して、「お手本のあるところまで復帰する」というデータを追加で集め学習させるという、追加学習というシンプルな方法で改善していきました。
追加データの収集法は、事前にお手本から学習したモデルを実際の環境で動かし、次にモデルの動きを見て、お手本から離れたタイミングを目視で判断します。そして手動操作に切り替えてお手本のある状態までのデータを追加で記録し、繰り返してデータを集めていくというものです。
追加データの学習方法は、収集したデータを訓練した時の最初のモデルに追加し、それら全てを使ってモデルを再学習させるというものです。性能が不十分であるときはこの追加データの収集と学習を繰り返すことにより、モデルの性能を引き上げることができます。
追加データを使用した性能改善の例。追加データ無しだとくぼみに引っかかって進行不可能だったものが、追加データ有りでは一度戻ってジャンプして越える動作を行い進行可能になった
なお、同じプレイ回数で比較した時に、通常のプレイだけを集めるより追加データも集めた方が性能改善されるのを確認できています。
技術的課題と発展
これらの手法により、複数ジャンル、複数のゲームである程度の自動プレイができていますが、課題もあると宮内氏は言います。
エージェント性能に関して、現在のモデルでは過去の情報に基づいた操作ができない構造になっているため、過去の情報が必須になるようなタスクはまず突破できません。これに対して時系列を扱えるTransformerなどのアーキテクチャに改善を期待しています。また、先述の通り、2時間の手動プレイに対して自動プレイで5時間ほどかかってしまう点も今後の改善すべき課題です。
模倣学習に必須の学習データ取得コストも大きな課題です。現在のモデルがある程度プレイできるようになるまで同じ箇所を数十回プレイする必要があり、これが非常に自動化工数に重くのしかかっています。こういった問題に対して、Few-shot学習(※)などの手法によって数プレイだけで済む可能性があります。
※非常に少数のラベル付きサンプルでトレーニングすることでAIモデルが正確な予測を行えるように学習する機械学習フレームワーク。
また、最近では汎用的なゲームプレイモデルを応用する手法が発表されており、注目されている研究領域のひとつであるとのことです。
このように本講演では、QAテストの自動化に自動プレイシステムを必要とすることから端を発し、「リプレイエージェント」「模倣エージェント」という2つのエージェントの使用が紹介されました。また、模倣エージェントにおけるモデル学習について詳細な技術説明も行われ、模倣学習を用いた自動プレイシステム、テスト自動化の成果が確認できる講演となりました。
PlayStation5®上で人間のプレイヤーと同条件でのゲームプレイ自動化を実現するAI技術 - CEDEC2024PlayStation5® 公式サイト
ゲーム会社で16年間、マニュアル・コピー・シナリオとライター職を続けて現在フリーライターとして活動中。 ゲーム以外ではパチスロ・アニメ・麻雀などが好きで、パチスロでは他媒体でも記事を執筆しています。 SEO検定1級(全日本SEO協会)、日本語検定 準1級&2級(日本語検定委員会)、DTPエキスパート・マイスター(JAGAT)など。