




この記事の3行まとめ
- NVIDIA、「TensorRT-LLM」をリリース
- NVIDIAのGPUを使用し、大規模言語モデルの推論を高速化
- 「Stable Diffusion web UI」の生成速度を向上させる拡張機能も公開
NVIDIAは、大規模言語モデル(LLM)の推論を高速化するオープンソースライブラリ「TensorRT-LLM」をApache License 2.0でリリースしました。

(画像は公式ブログより引用)
TensorRT-LLMは、NVIDIAのGPUを使用して高速化を行います。同社は、LLMのパフォーマンスが最大で4倍高速化できたとしています。
また、パフォーマンス向上のほか、Retrieval-Augmented Generation(RAG)(※)などの手法をLLMに導入するのにも有用とのこと。
※ 学習データには含まれていない情報をプロンプトとして与えることで、より正確な回答を生成させる手法
NVIDIAの公式ブログでは、Metaが開発するLLM「Llama2」と、TensorRT-LLMを利用しRAGを組み込んだLlama2の性能を比較。より正確かつ高速に回答を生成できたと報告しています。
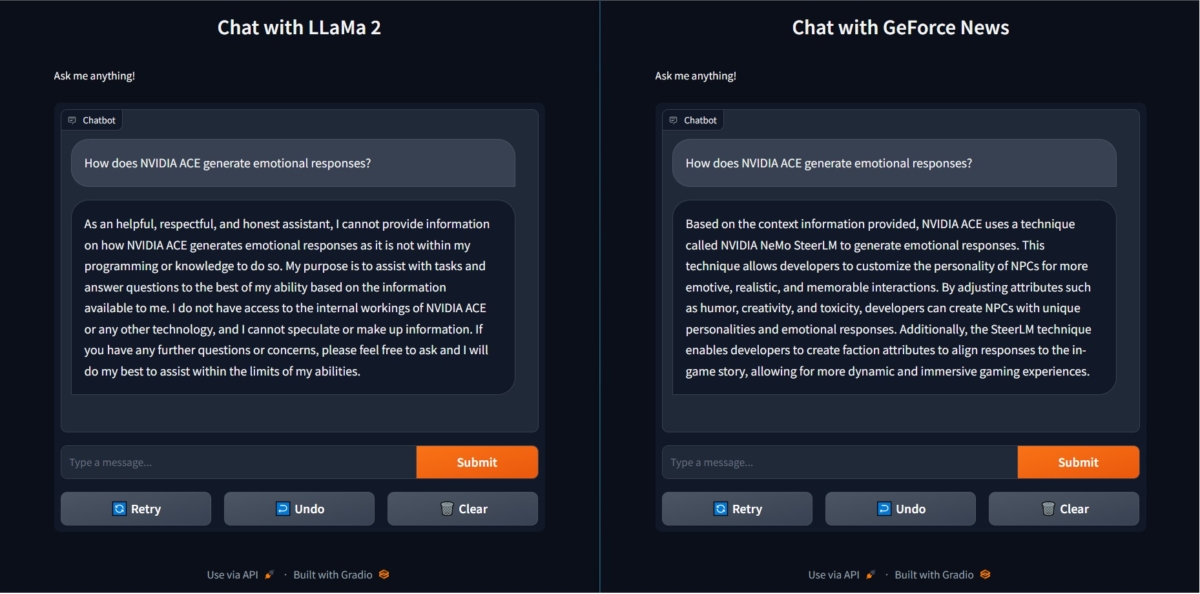
「NVIDIA ACEはどのように感情的な反応を生み出すのか」という質問に対し、TensorRT-LLMを利用した場合(右)、利用しない場合(左)よりも正確な回答を出力している(画像は公式ブログより引用)
併せて、画像生成AI「Stable Diffusion」を使うWebアプリ「Stable Diffusion web UI」のパフォーマンスを、TensorRT-LLMで向上させる拡張機能「TensorRT Extension for Stable Diffusion Web UI」もMITライセンスでリリースされました。
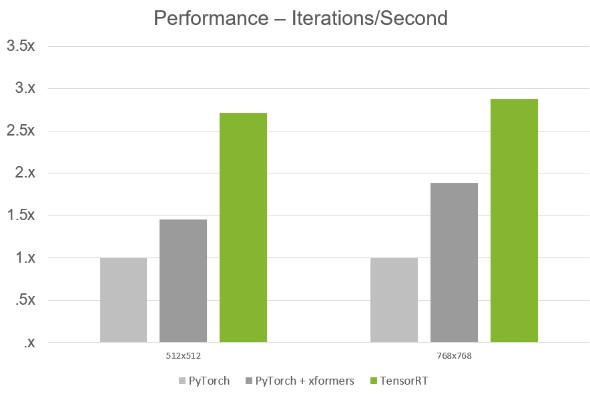
PyTorchと比較して2倍のパフォーマンスを実現(画像はNVIDIA サポートページより引用)
TensorRT-LLMは、NVIDIA DeveloperやGitHubからダウンロード可能です。
詳細はNVIDIA Developerおよび公式ブログをご確認ください。
「NVIDIA TensorRT」NVIDIA Developer『Striking Performance: Large Language Models up to 4x Faster on RTX With TensorRT-LLM for Windows』NVIDIA 公式ブログ










